はじめに
こんにちは。ZENKIGENデータサイエンスチームの栗原です。現在は主に『harutaka EF(エントリーファインダー)』の自然言語処理周りの研究開発に携わっています。
ChatGPTがOpenAIから公開され約半年が経ちましたが、この半年の大規模言語モデル、生成AI周りの発展スピードは凄まじいものです。
日本でも大きな盛り上がりを見せており、個人から企業、研究機関においてさまざまな活用、日本語モデルの開発等が活発に行われている印象です。
ZENKIGENにおいてもChatGPTを含め大規模言語モデル、生成AIをプロダクトに活用する上での様々な検討が進んでおり、その一環として社内勉強会で『ChatGPT(とその周辺)の技術』というお話をしました。
本記事は、これを外部向けに公開するものです。
内容は、OpenAIがChatGPTに至るまでの変遷として GPT(GPT-1)から GPT-4、人間に好まれる出力をするようにRLHFを応用した InstructGPT、大規模言語モデルをシングルGPUで動かすための技術である FlexGen、そして大規模言語モデルを軽量にファインチューニングする技術であるLoRA について、となっています。
GPT(GPT-1)
Improving Language Understanding by Generative Pre-Training [Radford et al., 2018]
GPTシリーズの始まりとなる論文です。
まず、この論文が出た当時の背景を簡単に述べます。
当時、自然言語処理界隈では教師あり学習への依存を軽減する方法の検討が一つの大きな研究トピックでした。
深層学習における教師あり学習は、多くの場合、人手による大量のラベル付きデータが必要となり、その作成および学習には大きなコストがかかるため、リソースの限られる言語・ドメインではその適用が困難でした。
また、それぞれのタスクに合わせてモデルの設計が必要でした。
そんな中で有効な選択肢として挙がったのが、ラベル付けされていないテキストから言語情報を獲得するモデルの構築です。
本論文はこの方向の有効性を示した重要な論文の一つで、ラベル付けされていないテキストから言語モデルを事前学習し、その後タスク用のデータでファインチューニングをすることで、モデルアーキテクチャの変更は最小限にさまざまなタスクで当時の最高性能(SOTA)を達成しました。
それでは詳細に入っていきましょう。
モデルアーキテクチャ
GPT(Generative Pre-Training Transformer)はTransformerのデコーダの一部を変更したものです。
Transformerに関しては、ZENKIGENから詳細な記事も出ていますのでこちらもご覧ください。
Fig.1 の左がGPTのアーキテクチャ、右が参考としてオリジナルのTransformerのアーキテクチャです。
GPT(Fig.1 の左図)とTransformerのデコーダ(Fig.1 の右図の右側)の違いは主に以下の2点です。
- オリジナルのTransformerにおけるエンコーダ(Fig.1 の右図の左側)の出力が入るMulti-Head Attention(Fig.1 の右図右側の中央付近の
Multi-Head Attention)と残差接続およびLayer Normalization(Fig.1 の右図右側の中央付近のMulti-Head Attentionの直後のAdd & Norm)がGPTにはないこと。 - オリジナルのTransformerにおける入力のPositional EncodingがGPTではPosition Embeddingとなり、学習可能になっていること。
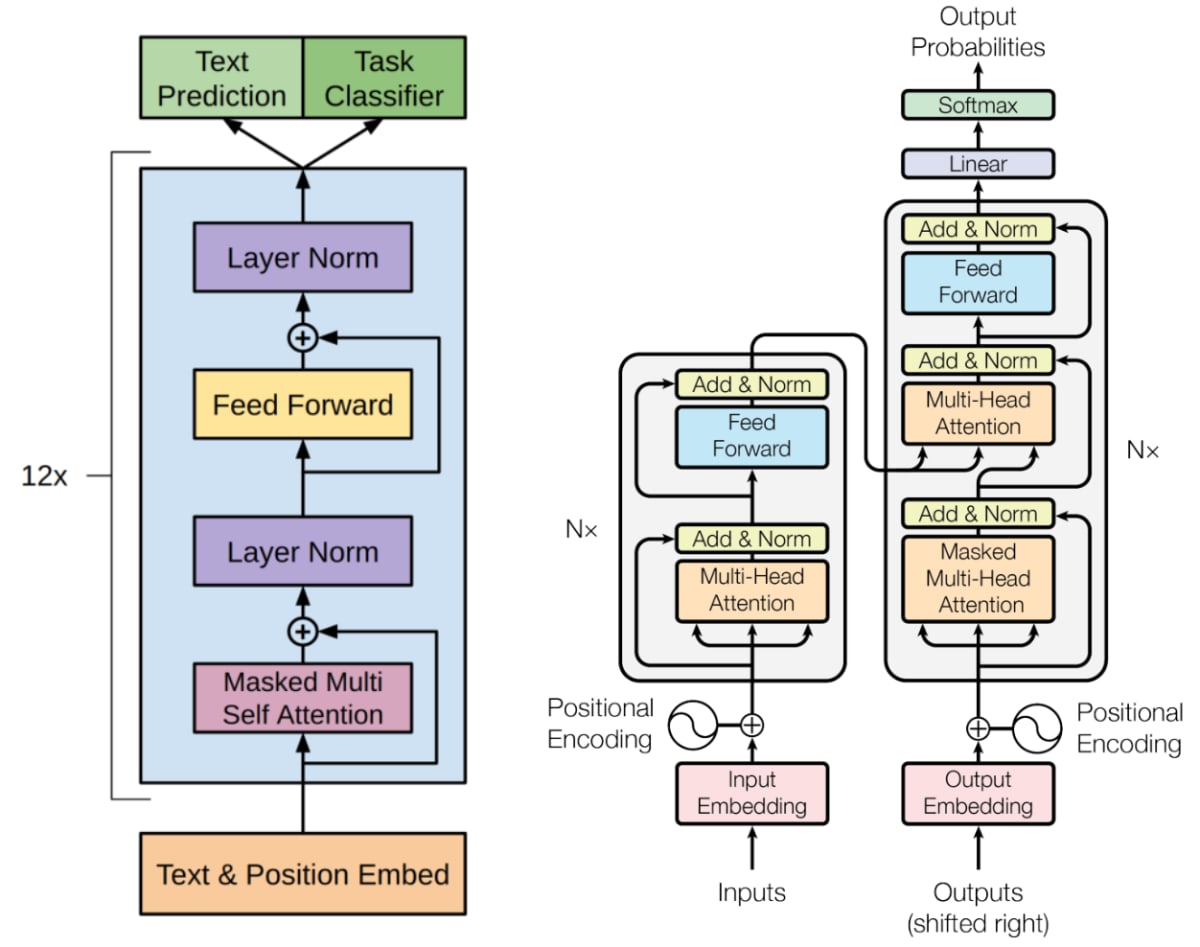
Fig.1.(左): GPTのモデルアーキテクチャ。Improving Language Understanding by Generative Pre-Training より引用。(右): オリジナルのTransformerのモデルアーキテクチャ。Attention Is All You Need より引用。
事前学習
フレームワーク
GPTの事前学習では、以下の尤度を最大化する形で、テキストの
ここで、
事前学習のフレームワークは以下のようになっています。
ここで、
事前学習設定
事前学習用コーパス
GPTの事前学習にはBooksCorpusという、7,000以上の未出版本からなるコーパスが使われました。
このコーパスは連続した長いテキストが含まれており、生成モデルが長距離の情報に基づく学習を行うことができると論文内で述べられています。
モデル仕様
学習時の全ての設定項目をここに上げることはしませんが、GPT-2以降と比較できそうな項目を記載します。
- Transformerブロック数 : 12
- 語彙サイズ : 40,000
- バッチサイズ : 64
- コンテキストサイズ : 512
- パラメータ数 : 117M
ファインチューニング
フレームワーク
事前学習が完了したら、ターゲットとなる下流タスクでモデルパラメータを更新するファインチューニングを行います。
以下の尤度を最大化するようにモデルを更新します。
ここで、
基本的にはこれで以上ですが、論文中ではファインチューニング時の尤度最大化の式に言語モデルの目的関数
入力データの取り扱い
ファインチューニングでは、入力が連続したトークン列であることが想定されます。
下流タスクによっては直感的にはこの入力形式とはならないように思われるタスクもありますが、Fig.2 のように Delim というスペシャルトークンを用いて複文を一つのトークン列に変換することでモデルが処理可能な形として入力します。
こうすることで、タスクごとにアーキテクチャを大きく変更することなく、ファインチューニングを行うことができます。
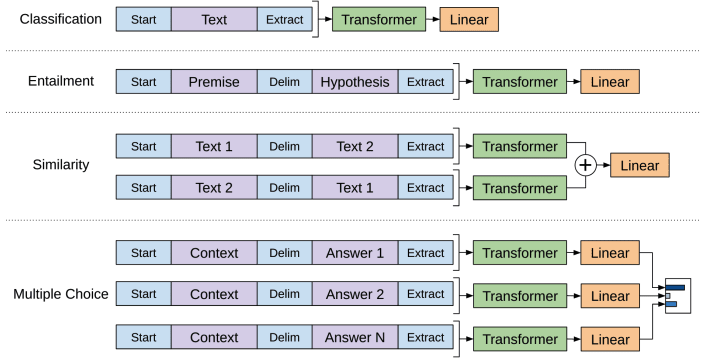
Fig.2.(左): ファインチューニングのための下流タスクごとの入力データ変換。Improving Language Understanding by Generative Pre-Training より引用。
具体的な下流タスクごとには以下の通りです。
- 分類タスク(Classification): 入力が一つのテキストであるという想定なのでこれはシンプルです。
- 含意関係認識(Entailment): "前提"と"仮説"の2文が入力として必要になりますが、これを
Delimというスペシャルトークンを挟んで連結することで一つのトークン列として入力します。 - 類似性タスク(Similarity): 類似性を測るタスクでは、2文の間に順序というものは存在しません。そこで、順序を入れ替えた2つの入力トークン列を独立してTransformerに入力し、それぞれの出力を要素ごとに和を取り線形層に渡します。
- QAや常識推論などの多肢選択式タスク(Multiple Choice): それぞれの選択肢ごとにコンテキスト文書と質問を連結したトークン列を用意し、
Delimで選択肢を連結した入力をTransformerに独立に通します。得られたそれぞれの出力をsoftmaxで正規化します。
実験・分析
実験では、事前学習したGPTを様々なタスクでファンチューニングした際の性能を、既存の教師ありモデルと比較しています。
NLI, QA, Commonsense Reasoning, Semantic Similarity, Classificationの多くのタスクで当時のSOTAを達成しました。
ここでは、この実験結果の後に記載されているAnalysisにある、ファンチューニングにおける性能とTransformerの層数の関係と、ゼロショットにおける性能と事前学習量の関係の分析に焦点を当てたいと思います。
ファンチューニングにおける性能とTransformerの層数の関係
Fig.3 では、下流タスクでのファインチューニングにおいて、転送する層数を変化させた際のtrainセットとdevセットでの精度の変化を示しています。
ここからは、層数を大きくするほど精度が向上する傾向が見て取れ、事前学習モデルの各層がターゲットタスクを処理する上での有用な情報を含んでいることを示唆していると述べられています。
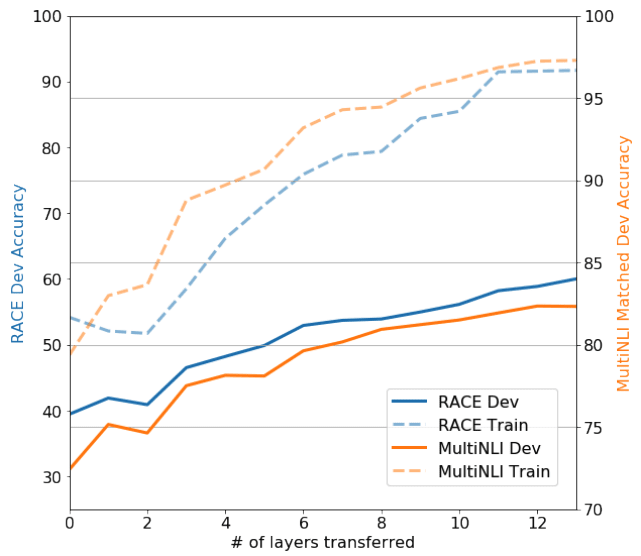
Fig.3. ファンチューニングにおける性能とTransformerの層数の関係。Improving Language Understanding
by Generative Pre-Training より引用。
ゼロショットにおける性能と事前学習量の関係
Fig.4 は、Transformerの言語モデルによる事前学習が進むにつれ、ゼロショット性能が向上していく様子を示したものです。
比較対象としているLSTMよりも着実に性能向上を示しており、ここから事前学習における生成的なアプローチが下流タスクに関連する様々な特徴を学習することを示唆していると述べています。
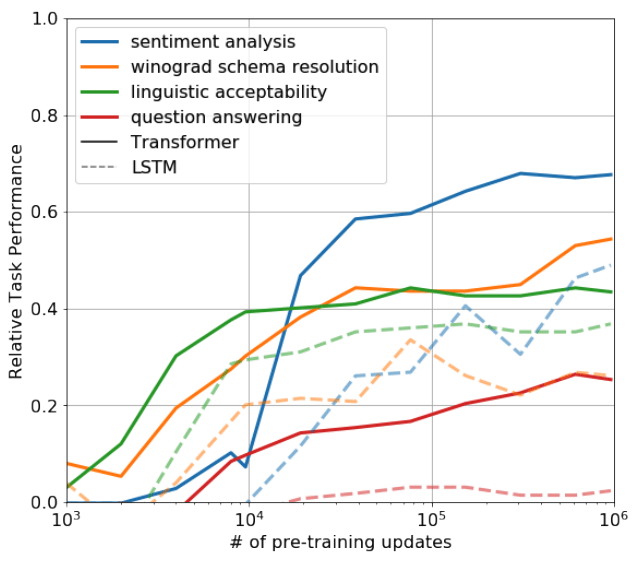
Fig.4. 事前学習量とゼロショット性能の関係。実線がGPTにおける各タスク(色)のゼロショット性能。比較対象として点線がLSTMにおける各タスク(色)のゼロショット性能。Improving Language Understanding by Generative Pre-Training より引用。
モデルを巨大化していくことの可能性 → GPT-2へ
上記二つの分析から、層数を増やすこと、学習量を増やすことでの性能向上の可能性が垣間見えました。
OpenAIはこの結果を足がかりに、モデルを大きくしていく方向に舵を切り、GPT-2以降の発展につながっていったのだと想像します。
GPT-2
Language Models are Unsupervised Multitask Learners [Radford et al., 2019]
GPTから1年後(といいつつ、GPTが2018年6月でGPT-2が2019年2月発表なので1年経っていません)、GPT-2が発表されました。
GPTは事前学習後ファインチューニングをすることで様々なタスクで高性能を謳っていたものでしたが、GPT-2はタイトル("Unsupervised Multitask Learners")にあるように教師なしで様々なタスクで当時のSOTAを達成しました。
この時期から、OpenAIが悪用の危険性があるとしてモデルの公開を控える対応をしたことなどもあり、大規模言語モデルが "ヤバそう" という雰囲気が多くの人々の間に広がっていった印象です。
モデルアーキテクチャ
初代GPTと多くの部分が同じですが、一部異なります。
Fig.5 の左図がGPT-2、右図がGPTです。違いは、正規化層(Layer Normalization)の位置です。
オリジナルのTransformerおよびGPTでは、正規化層はAttentionと残差接続の後に置かれていました。しかし、Attentionや残差接続の前に正規化層を置く形が学習が安定するということが知られるようになり、GPT-2もその形に変更されました。
あとは、Transformerの最終ブロックの出力の後に正規化層が追加されました。
アーキテクチャとしての変更は以上です。
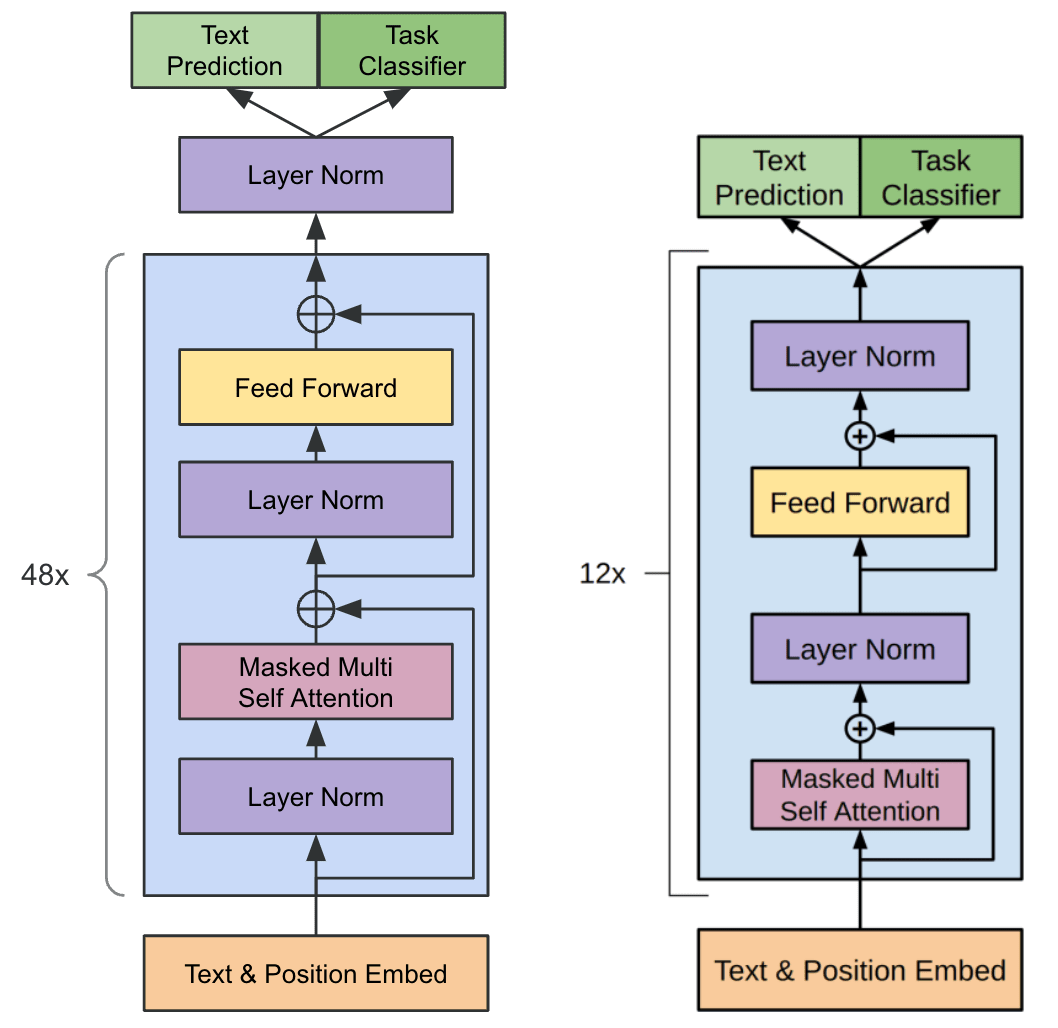
Fig.5.(左): GPT-2のモデルアーキテクチャ。GPTのモデルアーキテクチャ図を参考に自作。(右): 比較としてGPTのモデルアーキテクチャ。Improving Language Understanding by Generative Pre-Training より引用。
事前学習
事前学習用コーパス
GPT-2の事前学習用にはWebTextというコーパスが構築されました。
Common Crawlなど既存のWebクロールコーパスは大量のテキストを取得できるものの、内容を理解できない質の悪いデータも多く質の面で問題があると言われています。
そこでGPT-2では、Reddit上で3karma以上獲得している投稿内でリンクされているページをスクレイピングして取得するという形を取り、多少でも人の目が入っているテキストの取得をする工夫を入れることで、コーパスの質の確保を目指しました。
重複削除などクリーニング作業が行われ、最終的に約40GBのコーパスとなりました(参考: GPTの事前学習データであるBooksCorpusは約4.5GB)。
モデル仕様
GPTよりスケールアップしています。(カッコ内はGPT時の値)
- Transformerブロック数 : 48(12)
- 語彙サイズ : 50,257(40,000)
- バッチサイズ : 512(64)
- コンテキストサイズ : 1024(512)
- パラメータ数 : 1542M(117M)
実験
GPTは事前学習後ファインチューニングを行うことで多くのタスクで当時のSOTAというお話でしたが、GPT-2ではゼロショットで多くのタスクで当時のSOTAを達成しました。
いくつかのタスクについてもう少し見ていきます。
言語モデルタスク
Fig.6 に様々な言語モデルタスクにおけるGPT-2の各モデル(パラメータサイズの異なる4つのモデルを構築)と当時のSOTAの結果が比較されています。
GPT-2最大モデル(1542M)では、ゼロショットで、8個の評価用データセットのうち7個で当時のSOTAを上回りました。
LAMBADA(LAnguage Modeling Broadened to Account for Discourse Aspects)は、contextとtarget sentenceが与えられ、target sentenceの最後の単語を予測するタスクで、contextが最低50トークンと比較的長めで長距離依存関係を捉える能力が問われます。
GPT-2最大モデルでは、当時のSOTAがパープレキシティ99.8というところを8.63という大幅な改善を見せています。
ちなみに、パープレキシティとは、言語モデルにおいては次の単語を予測する上で何単語まで絞ることができたかの指標として利用されるもので、値が小さいほど予測単語を絞り込めているということで言語モデルの性能としては高いことになります(今回の結果では、既存のSOTAモデルが100単語ほどまでしか絞り込めていなかったのが、GPT-2最大モデルでは9単語程度まで絞り込めるようになっているということです)。
一方、1BW(One Billion Word Benchmark)では、先行研究を上回れませんでした。
論文中では、最も大きなデータセットであり、文レベルでのシャッフルが入っており長距離依存情報が除かれてしまっていることが要因と思われる、と記述されています。

Fig.6. 様々な言語モデルタスクでのゼロショット性能。Language Models are Unsupervised Multitask Learners より引用。
常識推論
Winograd Schema Challengeという常識推論の能力を測るデータセットでの評価が行われています。
これは、以下のように与えられた文と質問に対して、2つの選択肢から適切な回答を選択するタスクです。以下の例では、トロフィーとスーツケースがどのような関係か(スーツケースの中にトロフィーを入れるという関係)を理解することが必要です。
Q: The tropy would not fit in the brown suitcase because it was too big. What was too big?
Answer0: the trophy, Answer1: the suitcase
結果はfig.7 のようになっており、762M以上のモデルで、ゼロショットで当時のSOTAを上回りました。
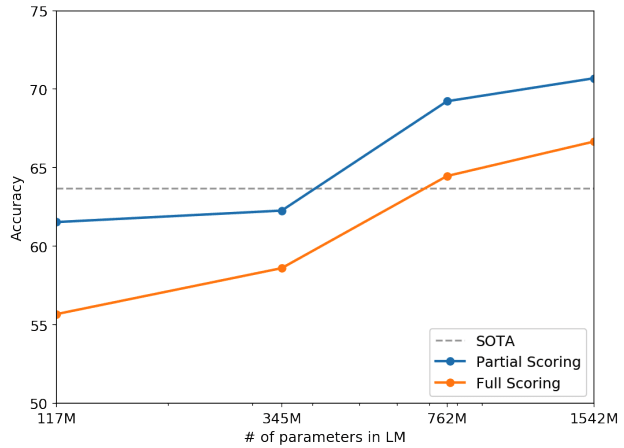
Fig.7. モデルパラメータごとのWinograd Schema Challengeにおける精度変化。Language Models are Unsupervised Multitask Learners より引用。
要約
ここからはSOTAを上回れていない結果になります。
Fig.8 に要約タスクの結果を示します。GPT-2での単純な精度は芳しくなく、ヒントとして記事の最後に “TL;DR;”と追加して要約作成を促すようにすることで(GPT-2 TL;DR:)記事からランダムに3つの文章を選択する(Random-3)よりもかろうじて良くなる程度です。
ただこのヒントがない状態(GPT-2 no hint)からヒントを与えるだけで大きく精度が上がる結果から、自然言語で言語モデルに対してタスク固有の動作を呼び出すことができることが実証されたと述べられています。
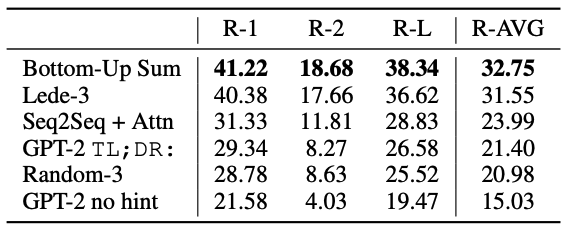
Fig.8. CNNとDaily Mail datasetにおける要約タスクの精度。Bottom-UP Sumが当時のSOTA。Language Models are Unsupervised Multitask Learners より引用。
翻訳
英語-フランス語の結果が報告されています。
英語からフランス語への翻訳では、BLUEスコアが 5 ということで、単純に単語を置換する翻訳よりも精度が低い結果です。
フランス語から英語への翻訳では、BLUEスコア 11.5 ということで、英→仏より多少良いですが、当時の教師なし機械翻訳手法のSOTA(BLUEスコア: 33.5)に遠く及んでいません。
しかし、GPT-2の事前学習に利用したWebTextコーパス内にはフランス語のテキストは10MBのみで、先行研究のモデルで利用されているコーパスより500倍小さいということで、ここまで精度が出たことが驚きだと述べています。
GPT-3
Language Models are Few-Shot Learners [Brown et al., NeurIPS2020]
GPT-3は2020年6月に発表されました。
この少し前に同じくOpenAIから、Transformerの性能はパラメータ数、データセットサイズ、計算予算の3変数の冪乗則に従うというスケーリング則が報告されました。
GPT-3はこのスケーリング則の研究で確認された現象をさらに2オーダー拡大して、性能が向上し続けるかどうかを経験的に検証したものです。
モデルアーキテクチャ
基本的にGPT-2と同じですが、Attention部分にSparse Transformerと同様の"locally banded sparse attention"を利用していると述べられています。
Sparse Transformerは通常のTransformerではトークン数の2乗に比例するメモリ使用量が必要となるattentionにおいて、特定の位置以外は注意を向けない制約を加えることで省メモリ化を実現する手法です。
省メモリ化により、より長い系列を扱えるようになり、計算も高速化し、精度もそれほど落ちないとされています。
テキストに対しては、Fig.9 の(c)にあるような直前n個と固定された点にattentionを向ける方法が有効とされており、詳細は述べられていませんが、GPT-3でもこれと同様のattentionスキーマが採用されているものと思われます。

Fig.9. 標準的なTransformerのattentionとSparse Transformerのattention。元論文は画像に対する研究であり、上段は6x6の画像に対する2つのattention head。下段は行を出力、列を入力とした時のconnectivity matrix。Generating Long Sequences with Sparse Transformers より引用。
事前学習
事前学習用コーパス
事前学習コーパスとしては、重複削除などのクリーニングを施したCommonCrawlに加えて、GPT-2で利用されたWebTextの拡張版、インターネット上の本のコーパス(Books1, Books2)、英語版Wikipediaが利用されました。
全体で、約570GBのコーパスです(参考: GPT-2は40GB)。
モデル仕様
GPT-2からさらにスケールアップしています。(カッコ内はGPT-1, GPT-2の値)
- Transformerブロック数 : 96(12, 48)
- コンテキストサイズ : 2048(512, 1024)
- パラメータ数 : 175B(117M, 1.5B)
実験
GPT-2では主にゼロショット性能を評価していましたが、GPT-3ではファインチューニングとゼロショットの間をより系統的に整理し、実験を行なっています。
- Fine-Tuning : 目的のタスク用の数千規模のラベル付きデータで訓練することで事前学習モデルの重みを更新。
- Few-Shot : 推論時にモデルに目的タスクの例をいくつか提示するが、重みの更新は行わない。
- One-Shot : Few-Shotと同様だが、1件のみ例を提示。
- Zero-Shot : 例は示さずにタスクの説明のみを自然言語で提示。
ここでもいくつかのタスクに絞って結果を見ていきます。
言語モデルタスク
Fig.10 は、GPT-2でもあったLAMBADAでの評価です。
パープレキシティで載っているSOTAはGPT-2の値ですが、そこからGPT-3はさらに改善し、Few-Shotで1.92という値を達成しています。
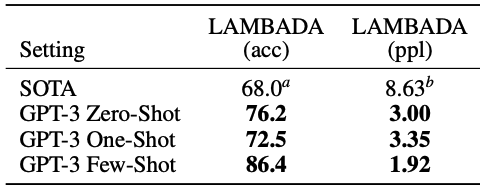
Fig.10. 言語モデルタスクでの性能。Language Models are Few-Shot Learners より引用(一部抜粋)。
翻訳
GPT-2の際はまだまだという状態であった翻訳タスクですが、GPT-3では可能性を感じる結果を見せています。
他言語(フランス語、ドイツ語、ルーマニア語)から英語への翻訳では、Few-ShotでSOTAと同等かそれ以上を達成。英語から他言語への翻訳ではまだSOTAには及ばないという状況です。
GPT-3の事前学習データは英語が93%、英語以外が7%という構成とのことで、英語への生成側の方が得意というのは理解できるように思います。
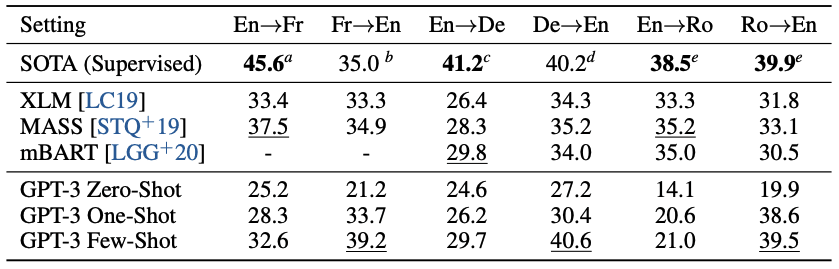
Fig.11. 翻訳タスク性能。Language Models are Few-Shot Learners より引用。
ニュース生成
GPT-3が生成する文章はもう人間が書いたものと区別がつかなくなっています。
Fig.12 はその結果を示しており、モデルサイズが大きくなるに従って、人間はニュース記事がモデルによって作成されたものか人間が書いたものか区別がつかなくなっています。
GPT-3 175Bでは、Mean accuracyが52%ということでほぼチャンスレートとなっています。
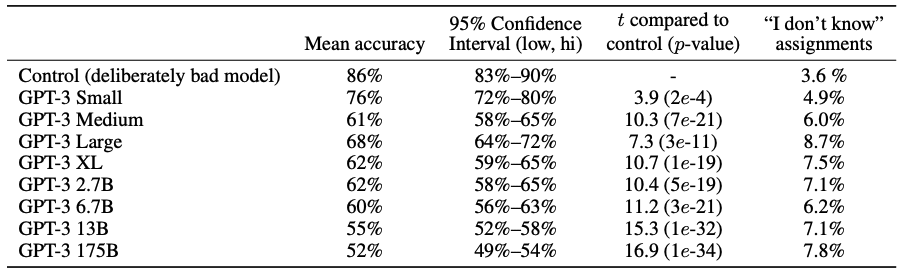
Fig.12. 短い(約200単語)ニュース記事がモデル生成されたものであるかどうかの人間の識別精度。Language Models are Few-Shot Learners より引用。
GPT-4
GPT-4 Technical Report [OpenAI, 2023]
2023年3月14日にGPT-4が発表されました。
GPT-4に関しては、大規模言語モデルの競争環境と安全性を考慮して、モデルのアーキテクチャや使用したハードウェア、学習環境、データセット、学習方法などの詳細は非公開とされました。
ですのでここでは、Technical Reportで報告されている実験結果をいくつか紹介します。
実験報告
予測可能なスケーリング
GPT-4のような巨大モデルでは、モデル固有の調整を行うことは困難であるため、1000倍~10000倍少ない計算量で訓練した小さいモデルから、GPT-4の性能を予測できることは大きな意味を持ちます。
OpenAIはこれを可能とするインフラと最適化手法を開発したと報告しています。
Fig.13 のように、GPT-4より小さいモデルに対して観察されたHumanEvalデータセットでの性能のプロットを点線で結ぶと、GPT-4の性能が予測され、実際に近い精度だったことが示されています。
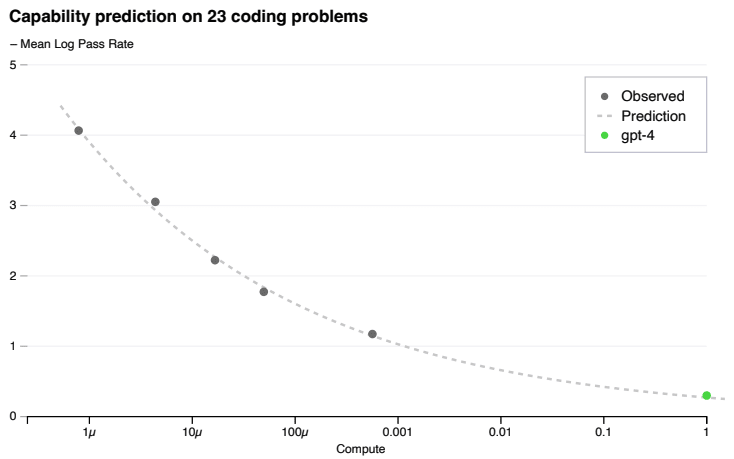
Fig.13. GPT-4とそれより小さいモデルのHumanEvalデータセットにおける性能。小さいモデルの性能からGPT-4の性能が予測できる。GPT-4 Technical Report より引用。
各種試験問題での性能
人間用にデザインされた、各種試験問題でのスコアが報告されました。
Fig.14 は実際のスコアと受験者内でのパーセンタイル、Fig.15 はGPT-3.5からの性能向上幅を視覚的に示したものです。
司法試験の模擬試験(Uniform Bar Exam)では、GPT-3.5(GPT-3とGPT-4の間にリリースされたモデル)が下位10%の成績だったのが、GPT-4では上位10%に入るスコアでした。
生物学オリンピックの問題(USABO Semifinal Exam 2020)では、GPT-3.5が下位30%だったのが、GPT-4では上位1%に入る成績でした。
一方、GPT-4でも低スコアのタスクも存在し、競技プログラミング(Codeforces Rating)や高校生向けの英語試験の小論文問題(AP English Literature)などは下位10%以下のスコアしか出せていません。
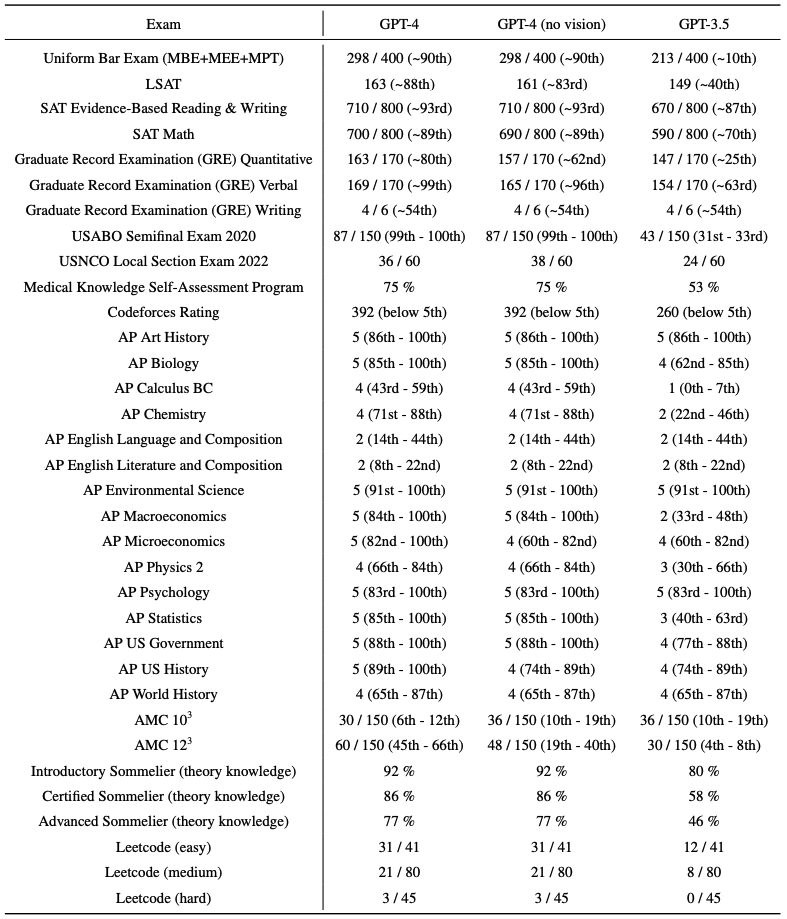
Fig.14. 人間用にデザインされた、学術・専門試験における性能。実際のスコアと受験者の中でのパーセンタイルが報告されている。GPT-4 Technical Report より引用。
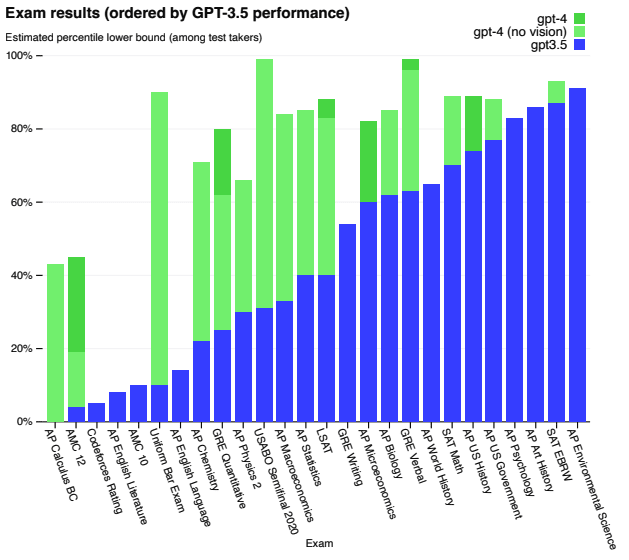
Fig.15. GPT-3.5からの性能向上幅。GPT-4 Technical Report より引用。
他言語での性能
Fig.16 は、汎用言語モデルのマルチタスク性能を測定するためのベンチマークであるMMLUベンチマークをさまざまな言語に翻訳し、GPT-4での性能を調査したものです。
Fig.16 の青で示されたものがGPT-3.5での英語の精度で、多くの言語がGPT-4でその精度を上回っていることがわかります(GPT-4の日本語での精度は79.9%、GPT-3.5の英語は70.1%)。
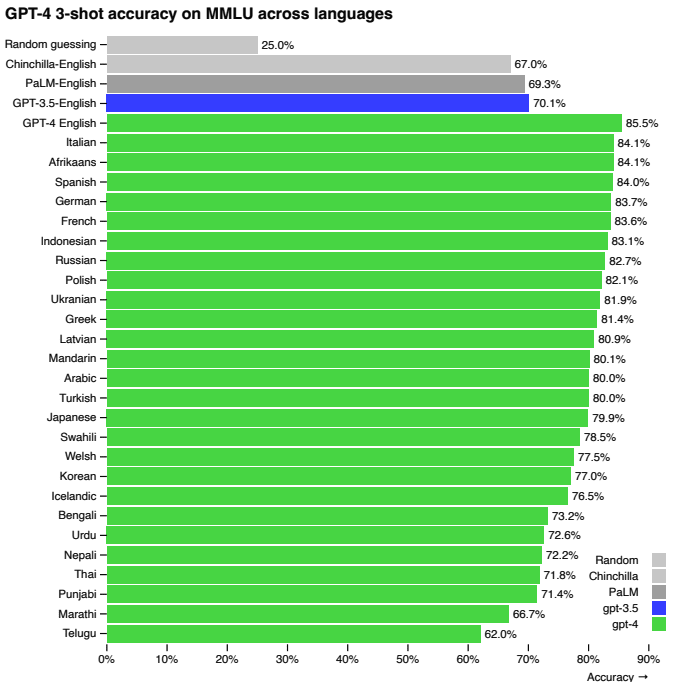
Fig.16. MMLUベンチマークにおける、さまざまな言語でのGPT-4の性能とGPT-3.5を含む既存モデルの英語での性能の比較。GPT-4 Technical Report より引用。
マルチモーダル
また、GPT-3からGPT-4への大きな進化として、画像の入力に対応しマルチモーダルの処理を行えるようになったことも挙げられます。
いくつか例を示します。
Fig.17 は棒グラフとそれに対する指示を与え、グラフの解析をさせています。
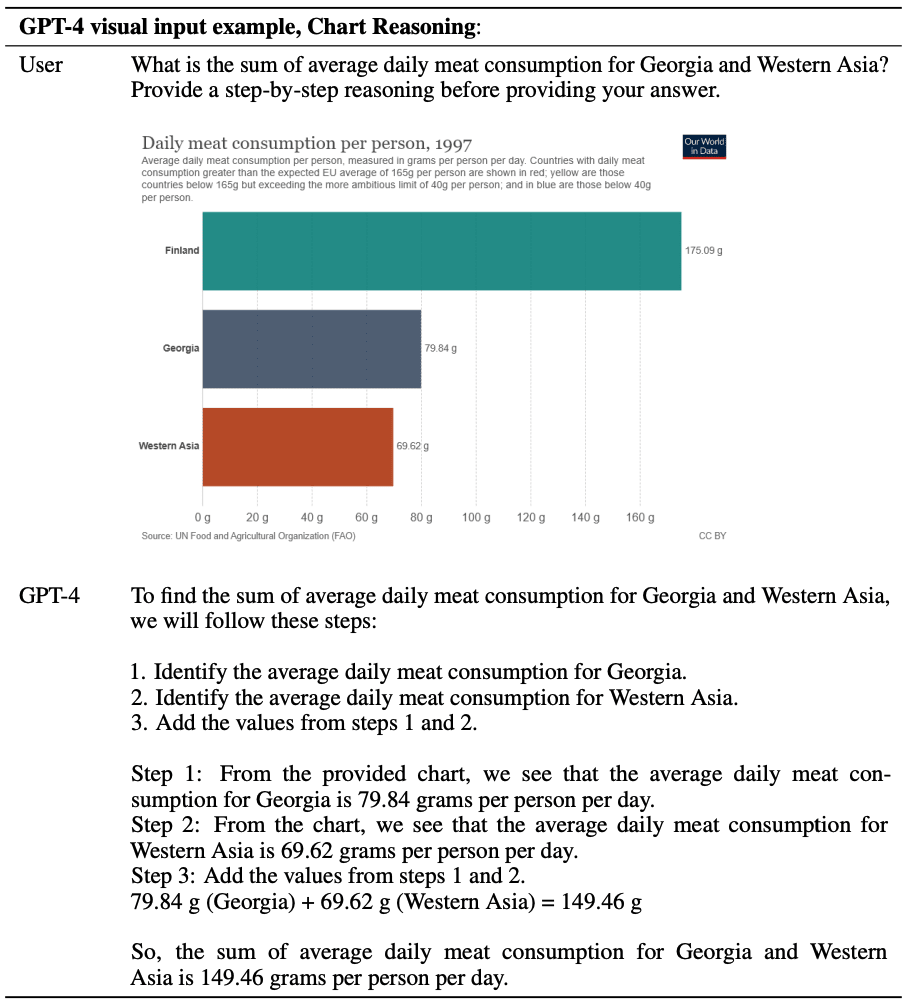
Fig.17. 棒グラフとともに、"グルジアと西アジアの1日の平均肉消費量の合計はいくつですか?答えを出す前に、step-by-stepで理由づけをしてください。"という指示を与えている。GPT-4 Technical Report より引用。
Fig.18 は論文を画像として与え、要約や画像内のある特定の図に対して説明をさせています。

Fig.18. 論文の要約。GPT-4 Technical Report より引用。
Fig.19 はチキンナゲットとともに、"時々、宇宙から見た地球の写真を見ると、その美しさに驚かされます。"という文が添えられた画像に対して、"このミームを説明してください"と指示が出されています。
GPT-4はチキンナゲットが世界地図に似せて並べられていることを理解し、ユーモアを説明しています。

Fig.19. ミームの理解。GPT-4 Technical Report より引用。
課題
GPT-4は非常に高い能力を持ちますが、それでもこれまでのGPTモデルと同様の限界があります。
ありもしない事実をでっち上げるようなHallucinationや、単純な推論ミス、ユーザーからの虚偽の前提に基づく発言に騙される、最新(学習データが2021年9月10日までのデータなのでそれ以降)の事象に対する知識の不足、といったものです。
RLHF(後述するInstructGPTで使われている、生成モデルの出力を人間のフィードバックに基づいてチューニングする技術)や、ChatGPTではプラグインの導入などによりこれらの影響を軽減する努力が行われています。
ここまで、GPTからGPT-4までの変遷を追ってきました。
ここからは実際に大規模言語モデルを利用するにあたって必要となる技術である、人間のフィードバックに基づいてモデルをチューニングするRLHFを適用したInstructGPT、1GPUで大規模言語モデルの推論を行うための技術FlexGen、大規模言語モデルのファインチューニングのコストを大幅に削減するLoRAについてお話しします。
InstructGPT
Training language models to follow instructions with human feedback [Ouyang et al., NeurIPS2022]
GPT-4の課題のところでも少し述べましたが、大規模言語モデルは事実をでっち上げたり、偏向、有害なテキストの生成、ユーザーの指示に従わないなど、意図しない挙動を示すことがあります。
これは、言語モデルの目的である「インターネット上のWebページの次のトークンを予測する」と、「ユーザーの指示に親切かつ安全に従う」という目的が異なることが大きな要因の一つです。
InstructGPTは、GPT-3に対してRLHF(Reinforce Learning from Human Feedback)という強化学習手法を応用して、人間に好まれるような出力をするようファインチューニングして構築されたものです。
アプローチ
InstructGPT構築はFig.20 に示す3ステップで行われます。
step-by-stepに見ていきましょう。
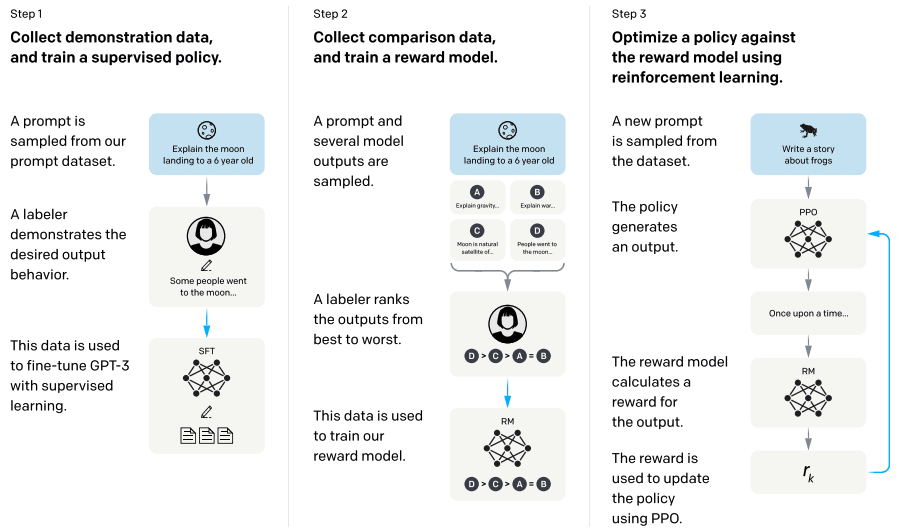
Fig.20. InstructGPT構築アプローチの全体像。Training language models to follow instructions with human feedback より引用。
ステップ1:プロンプトデータの収集とSFTモデルの構築
人間に好まれるような出力をするモデルを構築するにあたり、まず人間がどのような出力を好ましいと思っているのかのデータ収集が必要です。
UpworkとScaleAIを通じて40人のラベラーを雇い、プロンプトに対する望ましい出力を作成してもらいます。
入力となるプロンプトは、大半がOpenAIの商用の言語モデルAPIに投げられたものから収集されています。
ここで作成されたプロンプトとその返答のデータセットをSFTモデルの学習に利用します。
SFTモデルはGPT-3をベースに上記プロンプトデータセットで教師ありファインチューニングをしたモデルです。
ステップ2:Reward Modelの構築
ステップ1で構築したSFTモデルを利用し、入力プロンプトに対し複数の出力をさせます。
それら出力に対し、人間にとって好ましい出力かという観点でラベラーに出力をランクづけしてもらいます。
これがReward Modelデータセットです。
このRMデータセットを利用し、Reward Modelを構築します。
ステップ1で構築したSFTモデル(6Bのモデルを利用しているそうです)の最終層を除いて、スカラー(プロンプトに対する出力を入力としたときの報酬となる値)を出力するモデルを構築します。
RMデータセットにおいてあるプロンプトに対してランクづけされている回答群からペアを作成し、そのペアのランクの上下を正しく予測できるようモデルを学習します。これがReward Modelです。
損失関数は以下の通りです。
ここで、
ステップ3:PPOに基づく強化学習
SFTモデルをPPO(Proximal Policy Optimization)に基づく強化学習でファインチューニングします。
SFTモデルをベースに入力プロンプトに対して出力された返答に対し、Reward Modelが報酬を返します。
この報酬を最大化するよう学習します。
目的関数は以下の通りです。
ここで、
これは初期の実験(
一般にこの現象は "alignment tax" と呼ばれ、強化学習によるファインチューニングにより、事前学習時の性能が後退することを指しています。
この問題を回避するために、事前学習勾配を目的関数に効かせることで、事前学習時の性能を保つことができたとのことです。
以上により構築されるのがInstructGPTで、人間にとって好ましい出力をするようになることが期待されます。
評価
ラベラーはInstructGPTの出力を有意に好む
Fig.21 はステップ1の段階のSFTの175Bモデルよりも各モデル(GPT-3, SFT, PPO, PPO-ptx(InstructGPT))の出力がどの程度好まれたか、モデルサイズごとに比較したものです。
PPO, PPO-ptxモデルは1.3BのモデルでSFTの175Bモデルより好まれるという結果となりました。
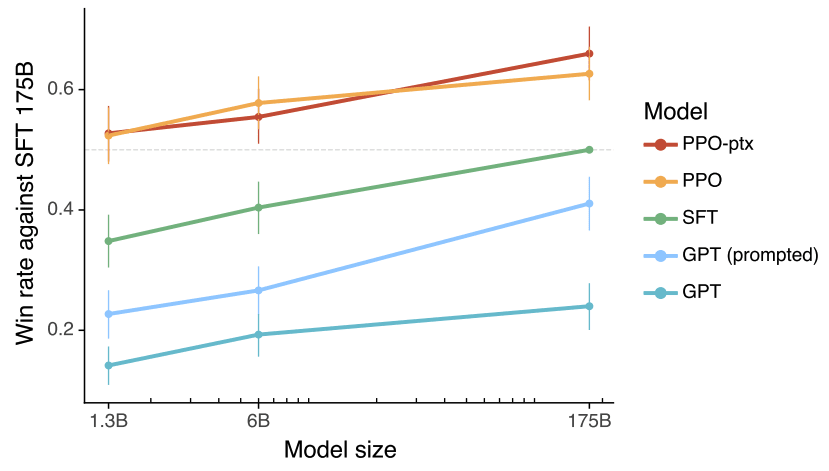
Fig.21. SFT 175Bモデルよりも各モデルの出力が好ましいとラベラーが判定した率の比較。Training language models to follow instructions with human feedback より引用。
人間の好みに汎化している
出力の好みは人によって変わる可能性があります。今回のモデルがステップ1, 2でデータを作成したラベラーにとって好ましいモデルであっても、それが広く一般の人間にとって好ましい出力になっているかわかりません。
そこで、ステップ1, 2でデータ作成をしていないラベラー(Heldout workers)に出力を評価してもらったところ、こちらでもFig.21 と同様の結果が得られた(Fig.22)ことから、データ作成に関わったラベラーの好みに過学習しているわけではないと述べています。
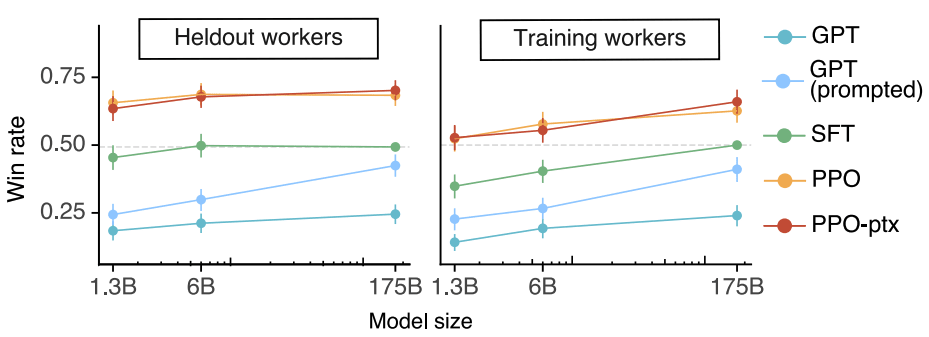
Fig.22. データ作成に関わっていない評価者(Heldout workers)が、SFT 175Bモデルよりも各モデルの出力が好ましいと判定した率の比較。Training language models to follow instructions with human feedback より引用。
さまざまな軸での評価
データ作成時は「人間の好み」という観点でしか見ていませんでしたが、このデータを学習したInstructGPTの出力は、プロンプトで定義された出力制約(ex. 「2段落以内で回答してください」など)により従ったり、事実のでっち上げが少ないといった傾向が見られたようです(Fig.23)。
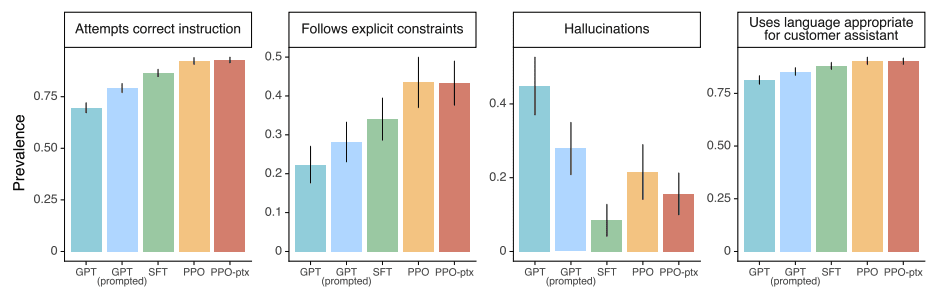
Fig.23. 正しい指示を試みるか、明示的に示された制約に従うか、事実のでっち上げが少ないか、カスタマーアシスタントにふさわしい言葉遣いか、の観点での評価。Training language models to follow instructions with human feedback より引用。
他言語への汎化
今回のステップ1, 2のデータ作成は基本的に英語に対して行われておりデータ内の99%以上が英語だと述べられています。
にもかかわらず、英語以外の言語のプロンプトに対してもより質の高い出力をするようになっているということです(Fig.24)。

Fig.24. フランス語での指示や、プログラミングコードの処理に対するGPT-3とInstructGPTの出力比較。Training language models to follow instructions with human feedback より引用。
FlexGen
High-throughput Generative Inference of Large Language Models with a Single GPU [Sheng et al., 2023]
通常、GPT-3など大規模言語モデルを読み込み推論に利用するには、大きな計算機資源と複雑な並列化戦略が必要になります。
FlexGenは、LLMの用途としてベンチマーキングや情報抽出、データラングリング、フォーム処理といった、大量のトークンを一括で推論する必要があるものの、トークン生成の速度はそれほど重視しない設定である、スループット指向の生成推論においてリソース要件を削減するものです。
手法
メインアイディアは、CPUやディスクにオフロードすることです。
Fig.25 のように一般的な計算機はメモリ階層が3段階であり、上位の階層は高速だが希少で、下位の階層は低速だが豊富にあります。
この豊富にあるCPUやDiskにLLMの一部をオフロードすることで、レイテンシは犠牲にするが、大きなバッチ入力を実現します。
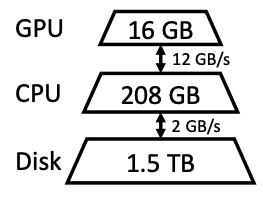
Fig.25. 一般的な計算機のメモリ階層(図の数値は本論文で実験に利用している Google Cloud NVIDIA T4 GPUインスタンス)。High-throughput Generative Inference of Large Language Models with a Single GPU より引用。
オフロード戦略
問題設定
このオフロードを伴う生成推論をグラフトラバーサル問題として定式化します。
Fig.26 のような計算グラフを考えます。
一つの正方形(ノード)はあるレイヤーのあるバッチの計算、同じ色の正方形は同じレイヤーの重みを共有します。
以下の制約上で、正方形をトラバースする(全て訪問する)有効なパスを定義します。
- ある正方形は、同じ行の左隣の正方形がすべて計算された場合にのみ、計算することができる。
- あるデバイス上で正方形を計算するためには、そのすべての入力(重み、活性値、キャッシュ)が同じデバイスにロードされている必要がある。
- 計算後の正方形は、活性値とKVキャッシュの2つの出力を生成。活性値は右の兄弟が計算されるまで保存しておく必要がある。KVキャッシュは、同じ行の一番右の正方形が計算されるまで保存しておく必要がある。
- デバイスに保存されているテンソルサイズの合計が、そのメモリ容量を超えることはできない。
ゴールは、計算コストとデバイス間でテンソルを移動する際のI/Oコストを含む総実行時間を最小化する有効なパスを見つけることです。
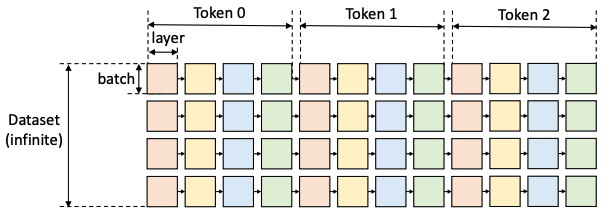
Fig.26. LLM推論の計算グラフ。High-throughput Generative Inference of Large Language Models with a Single GPU より引用。
計算スケジュール
トラバースする方法として、既存のシステムは全てFig.27 の上段にある row-by-rowスケジュールです。
この方法のメリットは、1バッチ分の生成を最速で終わらせることができ、行の直後にKVキャッシュを解放できる点です。
一方デメリットとして、連続する2つの正方形は重みを共有しないため、重みを繰り返しロードする必要があり、膨大なI/Oコストが発生します。
FlexGenで提案するのは、列で走査していく、column-by-columnスケジュールです。
この方法では、列内の正方形は重みを共有しているので、重みをGPUに残して再利用することができます。
一方、活性値とKVキャッシュのロード/アンロードが必要になり、列を一度に最後まで走査することはできません。
CPUとディスクのメモリが一杯になる時点で停止するための設計が必要になります。
しかしこの設計は複雑になるため、本論文では最適ではありませんが、指定したブロックサイズで折り返す、zig-zag blockスケジュールを採用しています(Fig.27 下段)。
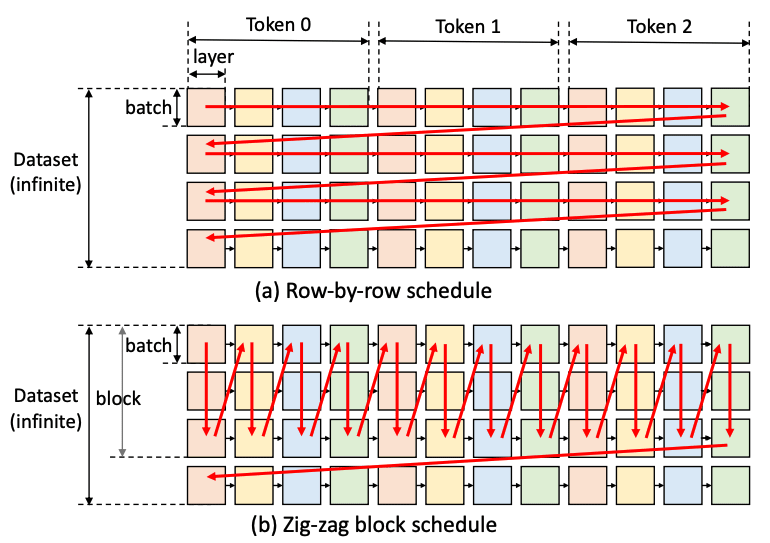
Fig.27. LLM推論の計算グラフ。High-throughput Generative Inference of Large Language Models with a Single GPU より引用。
近似による推論スループットの向上
大規模言語モデルは慎重な近似に対してロバストであり、一部の近似を許すことで精度の低下はほとんどないまま、推論の処理速度を大幅に向上することができると述べています。
本論文では、LLMの重みとKVキャッシュの両方を再学習やキャリブレーションなしに4ビットに圧縮する手法(Q-BERT)と、自己注意機構のスパース性を利用したSparse Attentionを取り入れています。
これらはFlexGenが様々な近似手法をシームレスに繋ぐことができる一般的なフレームワークであることを強調する目的で行っているもののようです。
評価
Fig.28 は、モデルとしてOPTの6.7Bから175Bを利用し、1GPUで達成できる最大生成スループットを検証したものです。
OPT-6.7Bでは、Accelerate、FlexGenはモデル全体を1つのGPUに収められたため、GPUのみを使用し、DeepSpeedはメモリのオーバーヘッドが大きくGPUに収めることができず、CPUオフロードを使用したと述べています。
OPT-30Bでは、全システムがCPUオフロードを使用。
DeepSpeedとAccelerateはKVキャッシュをGPUに保存するため、あまり大きなバッチサイズを使用できていません。
FlexGenはほとんどの重みとすべてのKVキャッシュをCPUにオフロードするため、GPUバッチサイズを大きくできていると述べています。
OPT-175Bでは、全システムがディスクへのオフロードを開始しました。
既存システムでは最大2のバッチサイズしか使用できませんでしたが、FlexGenではGPUバッチサイズ32、ブロックサイズ32×8を使用でき、69倍のスループットを達成しました。
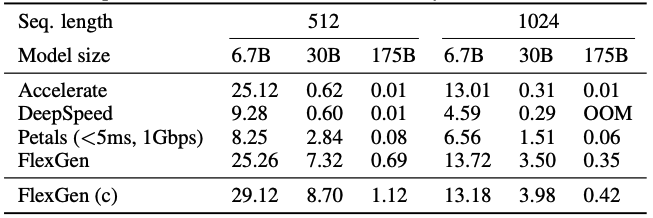
Fig.28. 様々なシステムでの1GPUで達成できる最大生成スループットの検証。High-throughput Generative Inference of Large Language Models with a Single GPU より引用。
LoRA
LoRA: Low-Rank Adaptation of Large Language Models [Hu et al., ICLR2022]
大規模言語モデルはFew-Shotで様々なタスクに対応できることで注目されていますが、ファインチューニングができるのであればファインチューニングをした方が精度は高いです(Fig.29)。

Fig.29. GPT-3のFew-Shotとファインチューニングでの精度比較。LoRA: Low-Rank Adaptation of Large Language Models より引用。
ファインチューニングの欠点は、生成物が元のモデルと同じサイズのパラメータを持つため、読み込み、保存が大変だということです。
例えば、GPT-3 175BのファインチューンングのためのGRAM消費量は1.2TB、チェックポイントサイズは350GBになります。
LoRAは、事前学習済みの重みは固定し、低ランク行列で間接的に下流タスクの訓練を行う手法で、学習パラメータ数とタスク切り替えのオーバーヘッドを大幅に削減しました。
手法
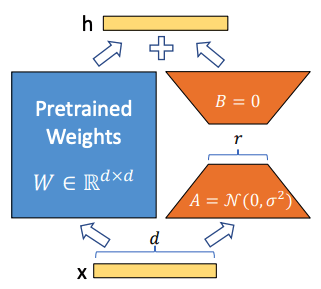
Fig.30. LoRAにおけるパラメータの再調整。オレンジ色のA, Bのみを学習する。LoRA: Low-Rank Adaptation of Large Language Models より引用。
LoRAでは、Fig.30 の青色の事前学習済みの重みは固定し、オレンジ色の2つの低ランク行列を導入し、パラメータの更新式を以下で定義します。
ここで、
初期化は、
そして、フォワードパスはベースが
以上です。非常にシンプルですね。
効果
LoRAの適用により、メモリとストレージの使用量を削減できます。
具体的には、GPT-3 175Bでは、ファインチューニング中のGRAM消費量を1.2TBから350GBに削減、タスク個別のファインチューニングのチェックポイントサイズを350GBから35MBに削減できると報告しています。
また、モデルの全パラメータではなく、LoRAの重みを交換するだけでタスクの切り替えをより低コストで行えます。
さらに、GPT-3 175Bでは大部分のパラメータについて勾配を計算する必要がないため、フルのファインチューニングと比較してトレーニング時25%のスピードアップを確認したと報告されています。
実験
既存手法との下流タスク精度比較
精度の面でどうなのか、既存の軽量なファインチューニング手法やフルのファインチューニングとの下流タスクの精度比較がされています。
Fig.31 はGPT-3 175Bモデルに対する様々なファインチューニングにおける下流タスクの精度比較です。フルのファインチューニングと比較して学習可能パラメータ数が4.7M(4万分の1近く)と非常に少ない設定のLoRAでも、下流タスクの精度が同等かそれ以上になっていることがわかります。
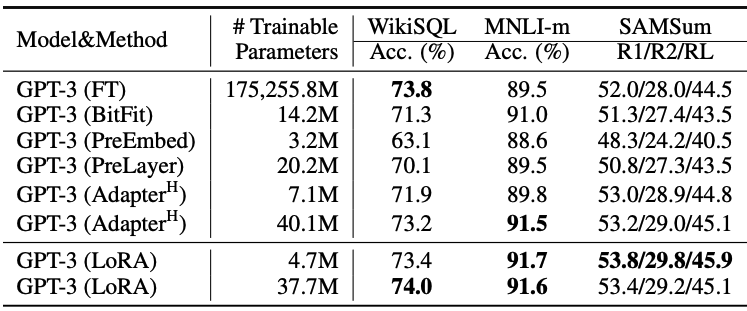
Fig.31. GPT-3 175Bにおける、既存の軽量なファインチューニング手法やフルのファインチューニングとの下流タスクの精度比較。LoRA: Low-Rank Adaptation of Large Language Models より引用。
学習可能パラメータ数と精度の関係
既存手法であるPrefix Tuning系のアプローチは、学習可能パラメータに対し性能が不安定であることが報告されていました。
LoRAはFig.32 に示すように、学習可能パラメータ数によらず性能が安定しています(ピンクの下三角)。
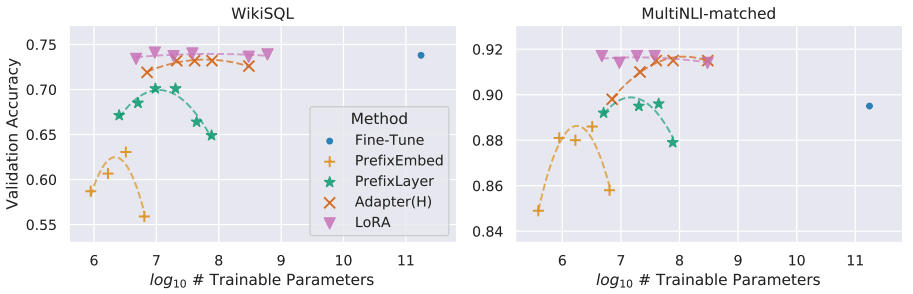
Fig.32. 学習可能パラメータごとのファインチューニング時の精度変化。LoRA: Low-Rank Adaptation of Large Language Models より引用。
どの層をファインチューニングするのが効果的か
原理的にはLoRAはニューラルネットワーク上の重み行列の任意のサブセットに適用可能ですが、本研究はAttentionの重みへの適用に限定しており、その中でも、限られた予算の中で、どの重み(query, key, value, output)に適用するのが効果的か報告されています。
Fig.33 にあるように、様々な層に低ランクでLoRAを適用した場合が最も効果的なようです。

Fig.33. GPT-3における、異なるタイプのattention重みに対してLoRAを適用した際の精度比較。LoRA: Low-Rank Adaptation of Large Language Models より引用。
ランクの大きさと精度の関係
Fig.34 にランクの大きさと精度の関係が示されていますが、
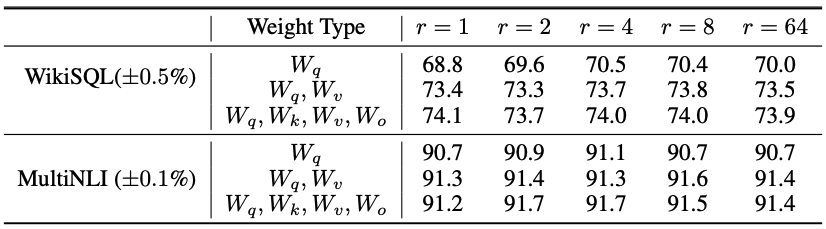
Fig.34. GPT-3における、様々なランクでLoRAを適用した際の精度比較。LoRA: Low-Rank Adaptation of Large Language Models より引用。
LoRAは実際に大規模言語モデルに適用され公開されているもの(Alpaca-LoRAなど)や、後続手法(AdaLoRAやQLoRAなど)が活発に研究されている印象で、今後も発展が期待されます。
終わりに
以上、『ChatGPT(とその周辺)の技術』のお話でした。
ChatGPTの登場で一気に世界が変わったと感じる今、ここに至る変遷とその周辺技術を一部ですがまとめました。
発展スピードが凄まじくすぐに情報が古くなる昨今ですが、この流れを作ったChatGPTの周辺を俯瞰する上で少しでも本記事が役立ちましたら幸いです。
参考文献
- Improving Language Understanding by Generative Pre-Training [Radford et al., 2018]
- Language Models are Unsupervised Multitask Learners [Radford et al., 2019]
- Language Models are Few-Shot Learners [Brown et al., NeurIPS2020]
- Scaling Laws for Neural Language Models [Kaplan et al., 2020]
- Generating Long Sequences with Sparse Transformers [Child et al., 2019]
- GPT-4 Technical Report [OpenAI, 2023]
- Training language models to follow instructions with human feedback [Ouyang et al., NeurIPS2022]
- High-throughput Generative Inference of Large Language Models with a Single GPU [Sheng et al., 2023]
- LoRA: Low-Rank Adaptation of Large Language Models [Hu et al., ICLR2022]
お知らせ
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。

Discussion