はじめに
Azureの無料サービスには、AI検索、AI翻訳、AI音声、ボットサービスなど、AIに関するサービスが多く含まれます。
今回はその中で、AIを使用した画像解析サービスである「Azure AI Vision」について試してみました。
Azure AI Vision でできること
Azure AI Visionは、Microsoftが提供するクラウドベースのAIサービスです。画像やビデオの分析を簡単かつ効率的に行い、強力な機械学習とディープラーニングのアルゴリズムを利用して、視覚データから有用な情報を抽出することができます。10,000種類以上の対象物(例:人、動物、建物、自然現象など)を認識できるため、幅広い業界で活用することが可能です。
Azure AI Vision には、主に以下の機能があります。
| 機能 | 説明 |
|---|---|
| 画像分析 | 画像内のオブジェクトやシーン、テキストなどを自動的に検出し、キャプションをつけて分類します。 目視で行っていたタグ付けを自動化可能です。 |
| 空間分析 | 物理的な領域内の人々の存在と動きをリアルタイムで把握します。セキュリティカメラの映像から異常行動を検出したり、顧客行動を分析することが可能です。 |
| 光学式文字認識(OCR) | 画像内のテキストを抽出し、デジタルデータに変換します。スキャンした書類や手書きのメモなどをデジタル化可能。言語や書き方が混在していても対応可能。 |
| 顔認識 | 画像やビデオ内の人物の顔を検出し認識します。入退室管理や、顧客の年齢層や性別を分析するマーケティング活動などに活用可能。 |
今回はこれらの機能から、「画像分析」「光学式文字認識(OCR)」「顔認識」を実際に試してみましたので、その説明をします。
Azure AI Vision の料金
アカウントを作成した日から12か月以内であれば、1か月あたり5,000件のトランザクションまでは無料で使用することができます。
従量課金制となっていますので、無料分を超えた場合は使用した分だけ料金が発生します。
Azure AI Vision を使ってみよう
Azure AI Vision には画像分析、ビデオ分析、OCRなどいくつかの機能がありますが、今回は「画像分析」について、以下の Microsoft Learn の手順に沿って実施していきます。
1. サンプルの画像ファイルを用意する
https://aka.ms/mslearn-images-for-analysis にアクセスし、 image-analysis.zip をダウンロードします。
ダウンロードしたファイルは任意のフォルダに解凍しておきます。
ご自分で用意した画像を使用したい場合は、あらかじめ用意しておきます。
今回は、無料の写真素材をこちらのサイトからダウンロードして使用しました。
2. Azure AI Foundry ポータルでプロジェクトを作成する
Azure AI Foundry ポータル にアクセスし、Azure サブスクリプションを持っていれば、そのアカウントでサインインします。
Azure サブスクリプションを持っていない場合は、アカウントを作成します。

サインインしたら、画面の下部にある「Azure AI サービスの詳細」をクリックします。

「Azure AI サービス」のページが開くので、「Vision と ドキュメント」をクリックします。

「Vision + Document」のページが開くので、「image」タブをクリックし、「Image captioning」をクリックします。
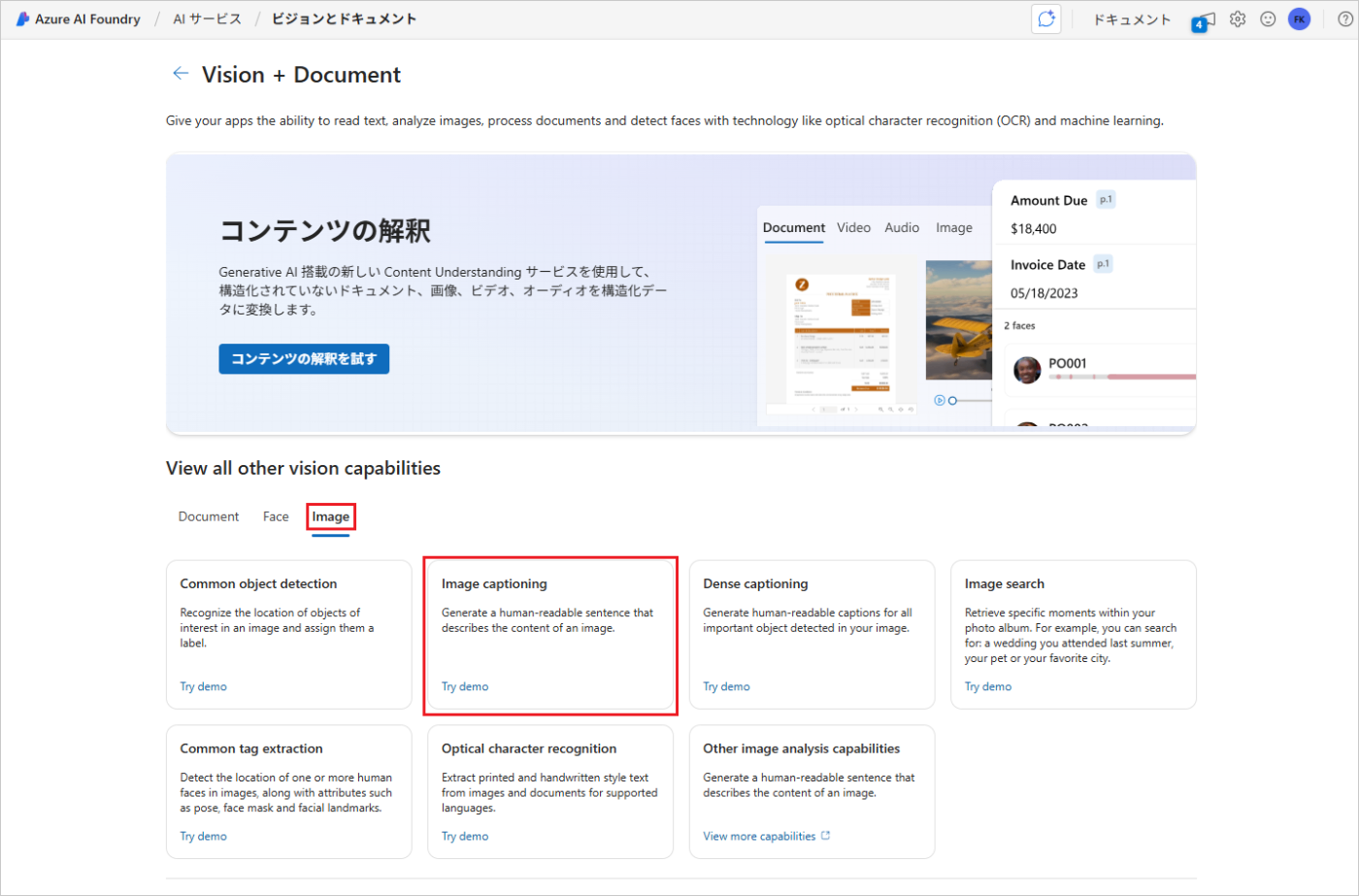
「Add captions to images」のページが開くので、「Select a hub」ボタンをクリックします。

「ハブの選択」ウィンドウが表示されるので、「新しいハブの作成」をクリックします。

「新しいハブの作成」画面で以下の値を設定し、「次へ」をクリックします。
ハブ名やリソースグループはアカウント名から自動的に生成されますので、基本的にはすべてデフォルトの値で問題ありません。
- ハブ名:ハブ名の有効な名前を入力(デフォルト値でOK)
- サブスクリプション:自分のサブスクリプション名(デフォルト値でOK)
- リソースグループ:既存のリソースグループを選択、または作成する(デフォルト値でOK)
- 場所:いずれかの場所を選択する
- Azure AI サービスの接続:有効な名前で新しいAzure AI サービスリソースを作成する(デフォルト値でOK)
- Azure AI 検索に接続する:接続をスキップする
「場所」のリストに日本がないため、ここでは「Southeast Asia」を選択しました。

内容を確認し、「作成」ボタンをクリックします。

しばらく待つと、「作業を続けるためにはプロジェクトが必要です」というウィンドウが表示されます。プロジェクト名を入力し(こちらもデフォルト値のままでOKです)、「プロジェクトの作成」ボタンをクリックします。

これでAzure AI Foundry ポータルでプロジェクトを作成することができました。

3. 画像のキャプションを生成する
左側のメニューから「AIサービス」をクリックします。

「Vision と ドキュメント」をクリックします。
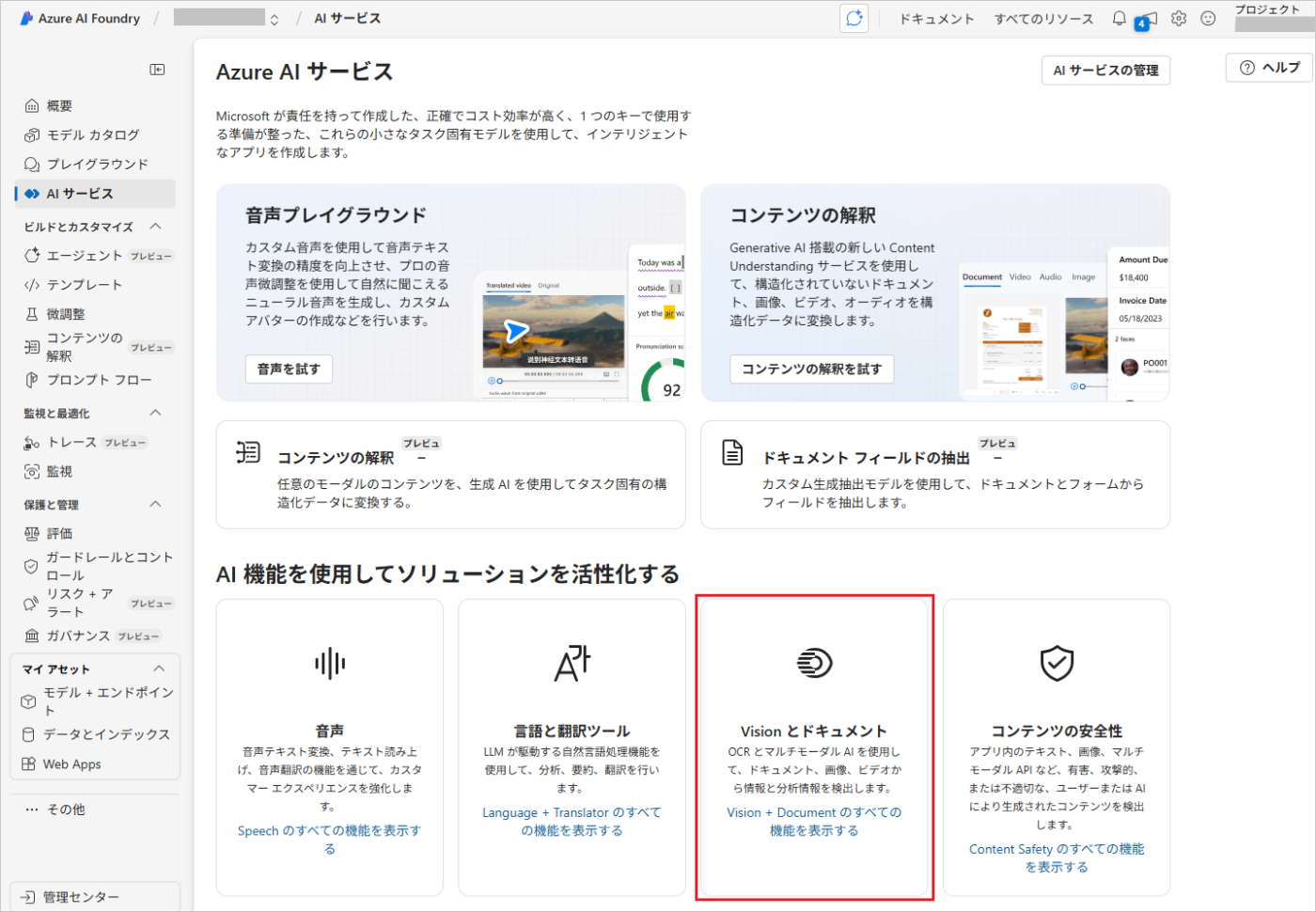
「image」タブをクリックし、「Image captioning」をクリックします。

「Connected Azure AI Services」で、先ほどハブの作成のところで作成したAzure AI サービスが選択されていることを確認します。
※ハブの作成画面で入力したAzure AIサービスは「ai-kureritest_ai-XXXX」でしたが、この画面では「ai-kureritestaiXXXXXXXXXX~(southeastasia)」となっていました。多少違っていますが、リストには1つしか表示されないため、このまま進めます。

「Browse for a file」リンクをクリックし、事前に用意した画像をアップロードします。
画像ファイルをアップロードすると、画面の右側にある「Detected Attributes」にキャプションが表示されます。
ここで表示されるキャプションは「画像の内容を説明する、人間が読める単一の英語の文章」となっています。

4. 高密度キャプションを生成する
次に、同じ画像を使用して高密度キャプションを生成します。
ページ上部の「←」をクリックし、「Vision + Document」のページに戻ります。

「Vision + Document」のページで「image」タブをクリックし、「Dense captioning」をクリックします。

先ほどと同様に、「Browse for a file」リンクをクリックし、事前に用意した画像をアップロードします。
「Detected Attributes」に複数のキャプションが表示されます。
高密度キャプションは、画像の中の「1つ1つのもの(オブジェクト)」を見つけて、それぞれに「どんなものか」「何をしているか」を説明文(キャプション)として付けてくれる機能です。
また、リスト内のいずれかのキャプションにマウスオーバーすると、画像内で検出されたオブジェクトごとにキャプションが生成されていることを確認できます。

5. 画像のタグ付け
次に、タグ抽出機能について確認していきます。
ページ上部の「←」をクリックし、「Vision + Document」のページに戻ります。
「Vision + Document」のページで「image」タブをクリックし、「Common tag extraction」をクリックします。

「Browse for a file」リンクをクリックし、事前に用意した画像をアップロードします。
「Detected Attributes」に画像から抽出されたタグのリストと、それぞれの信頼度スコアが表示されます。
タグのリストには「camel(ラクダ)」「dessert(砂漠)」のような物体(オブジェクト)だけでなく、「ancient history(古代の歴史)」「wonders of the world(世界の不思議)」のような、ちょっと詩的なタグも含まれています。

6. オブジェクト検出
最後に、オブジェクト検出について確認します。
ページ上部の「←」をクリックし、「Vision + Document」のページに戻ります。
「Vision + Document」のページで「image」タブをクリックし、「Common object detection」をクリックします。

ここで、「Region not supported: You need to create an AI Services resource in supported region to start using this application.」と表示されました。ハブの作成で選択した「Southeast asia」リージョンではオブジェクト抽出機能が利用できないようです。
「Create a new AI Services resource」をクリックし、新しいリソースを作成します。

リージョンに「East US」を選択し、「作成して接続」をクリックします。

作成したAzure AI サービスが選択されていることを確認し、事前に用意した画像をアップロードします。
「Detected Attributes」に画像から検出されたオブジェクトのリストと、それぞれの信頼度スコアが表示されます。

7. 光学式文字認識(OCR)
Microsoft Learning のサイトではここまでの手順が記載されていますが、せっかくなので 光学式文字認識(OCR) と、顔認識 についても試してみたいと思います。
ページ上部の「←」をクリックし、「Vision + Document」のページに戻ります。
「Vision + Document」のページで「document」タブをクリックし、「OCR/Read」をクリックします。

「Browse for a file」リンクをクリックし、事前に用意した画像をアップロードします。
今回は手書きのメモをスマホのカメラで撮影した画像を使用しました。
画像をアップロードしたら「Run analysis」をクリックします。

日本語と英単語が混在していたり、文字の色が違っていても問題なく読み取れていることがわかります。

8. 顔認識
次に顔認識を試してみます。
ページ上部の「←」をクリックし、「Vision + Document」のページに戻ります。
「Vision + Document」のページで「face」タブをクリックし、「Detect faces in an image」をクリックします。

「Browse for a file」リンクをクリックし、事前に用意した画像をアップロードします。
今回はマスクをして正面を向いている人と、マスクをして横を向いている人がいる画像を使用しました。
正面を向いていれば、マスクをしていても顔として認識されていることがわかります。

タグを日本語で出力することはできるか?
Azure AI Foundry Portal ではタグが英語で出力されますが、実際に利用する場合は日本語で出力したいと思うことも多いですよね。
Azure AI Foundry Portal にはタグを日本語で出力することはできないようです。(2025年10月現在)
しかし、Azure AI Vision Studio というものがあり、こちらでは出力する言語を選択することができ、タグを日本語で出力することができました。

AI Vision StudioはAzure AI Visionサービス専用の体験型でもポータルの位置づけで、画像解析等の結果をGUIで確認することができるものです。
つまり、
- AI Vision Studio は「Azure AI Foundry Portal」の中の Vision 機能を単体で触れる体験サイト
- Foundry Portal はその上位概念で、Visionを含めたすべてのAIを連携できる統合プラットフォーム
ということのようです。
まとめ
今回は無料で利用できる Azure AI サービスのうち、 AI Vision を試してみました。
Azure AI Foundry Portal を使用することで手軽にAIの画像解析を試すことができますので、どのような機能があるのか・どういった解析ができるのかを確認するのに非常に便利だと感じました。
また、 Azure AI Foundry Portal は GUI ベースのツールですが、プログラムからAIサービスを呼び出すことももちろんできます。
Azure AI Foundry Portal から「</>View Code」をクリックすると、 Python と C# のコードを確認することができます。


Azure にはまだまだAI関連のサービスがたくさんありますので、今後は他のサービスについても調べてみたいと思います。

Discussion