GraphRAG のソースコードから概念を読み取る
GraphRAG のソースコードから概念を読み取る
Claude3.5 Sonnet を使って構造を抽出している
ドキュメントがインデックスに保存される際のコア構造を図示します。この図は、データモデルの本質的な部分に焦点を当て、ドキュメントがどのように処理され、保存されるかを示します。
この図は、ドキュメントがインデックスに保存される際のコア構造を示しています。主要なコンポーネントは以下の通りです:
-
メタデータ (Metadata):
- ID: ドキュメントの一意識別子
- ソース (Source): ドキュメントの出所
- タイトル (Title): ドキュメントのタイトル
- タイムスタンプ (Timestamp): ドキュメントの作成または更新日時
-
コンテンツ (Content):
- 生のテキスト (Raw Text): ドキュメントの元のテキスト内容
- テキストユニット (Text Units): ドキュメントを分割した smaller chunks
- 各テキストユニットは以下を含む:
- テキスト
- 埋め込み
- 関連エンティティ
- 関連共変量 (存在する場合)
- 各テキストユニットは以下を含む:
-
埋め込み (Embeddings):
- ドキュメント埋め込み: ドキュメント全体の数値表現
- テキストユニット埋め込み: 各テキストユニットの数値表現
-
関係 (Relationships):
- エンティティ: ドキュメント内で識別された実体や概念
- 各エンティティは以下を含む:
- エンティティ名
- エンティティタイプ
- エンティティの説明
- エンティティの埋め込み
- 各エンティティは以下を含む:
- コミュニティ: ドキュメントが属するグループまたはクラスター
- エンティティ: ドキュメント内で識別された実体や概念
この構造により、以下のことが可能になります:
- 効率的な検索: メタデータと埋め込みを使用して、関連ドキュメントやテキストユニットをすばやく見つけることができます。
- コンテキスト理解: エンティティとその関係を通じて、ドキュメントの内容をより深く理解できます。
- 柔軟なクエリ: テキストユニットレベルでの検索により、大きなドキュメント内の特定の部分にアクセスできます。
- スケーラビリティ: この構造は大量のドキュメントを効率的に処理し、保存することができます。
この構造は、効果的な情報検索と高度な分析を可能にする強力な基盤を提供します。クエリシステムは、この構造を利用して、ユーザーの質問に対して正確で関連性の高い回答を生成することができます。
クエリシステム
この情報を基に、クエリシステムの仕組みを図示します。ただし、提供された情報は主にデータの読み込みと保存に関するものであり、クエリプロセス自体の詳細は含まれていません。そのため、一般的なクエリシステムの構造を推測して図を作成します。
この図は、推測されるクエリシステムの構造を示しています。主要なコンポーネントとプロセスは以下の通りです:
-
クエリ処理 (Query Processor):
- ユーザーのクエリを受け取り、適切な検索方法を決定します。
-
検索方法:
- セマンティック検索: ベクトルストアを使用して意味的に関連する情報を検索します。
- キーワード検索: 転置インデックスを使用して関連文書を検索します。
-
データソース:
- エンティティ、テキストユニット、ドキュメント、関係、コミュニティ、共変量などの情報が含まれます。
- これらのデータは、インデックス作成プロセスで生成されたものです。
-
埋め込み生成:
- エンティティ、テキストユニット、ドキュメントの埋め込みが生成され、ベクトルストアに格納されます。
-
コンテキストビルダー:
- 検索結果から関連情報を収集し、LLMのための適切なコンテキストを構築します。
-
LLM (大規模言語モデル):
- 構築されたコンテキストとユーザーのクエリを使用して、適切な応答を生成します。
-
レスポンス生成:
- LLMの出力を整形し、ユーザーに理解しやすい形式で提供します。
このクエリシステムの構造により、以下のことが可能になります:
- 意味的検索: 埋め込みを使用して、クエリに意味的に関連する情報を見つけます。
- キーワード検索: 従来の検索手法も併用して、関連文書を効率的に検索します。
- コンテキスト理解: 複数のデータソースから情報を収集し、クエリの文脈を理解します。
- 適応的応答: LLMを使用して、ユーザーのクエリに対して柔軟で適切な応答を生成します。
この構造は、インデックス作成プロセスで生成されたデータを効果的に利用し、高度な検索と質問応答機能を提供します。ユーザーのクエリに対して、関連性の高い情報を素早く取得し、理解しやすい形で提供することができます。
クエリシステム with retrieval
提供された情報を元に、クエリシステムの構造をより詳細に図示します。これらのファイルは、各データモデル(エンティティ、関係、テキストユニット、コミュニティレポート、共変量)の取得メソッドを提供しています。この情報を使用して、クエリシステムの図を更新します。
この更新された図は、クエリシステムの構造をより詳細に示しています。主要なコンポーネントとプロセスは以下の通りです:
-
クエリ処理 (Query Processor):
- ユーザーのクエリを受け取り、適切なデータ取得方法を決定します。
-
データ取得メソッド:
- エンティティ取得:
get_entity_by_key,get_entity_by_name,get_entity_by_attribute,to_entity_dataframe - 関係取得:
get_in_network_relationships,get_out_network_relationships,get_candidate_relationships,to_relationship_dataframe - テキストユニット取得:
get_candidate_text_units,to_text_unit_dataframe - コミュニティレポート取得:
get_candidate_communities,to_community_report_dataframe - 共変量取得:
get_candidate_covariates,to_covariate_dataframe
- エンティティ取得:
-
ベクトルストア:
- 各データタイプ(エンティティ、関係、テキストユニット、コミュニティレポート、共変量)に対応するベクトルストアがあります。
-
コンテキストビルダー:
- 各データ取得メソッドから得られた情報を統合し、LLMのための適切なコンテキストを構築します。
-
LLM (大規模言語モデル):
- 構築されたコンテキストとユーザーのクエリを使用して、適切な応答を生成します。
-
レスポンス生成:
- LLMの出力を整形し、ユーザーに理解しやすい形式で提供します。
-
データソース:
- エンティティ、関係、テキストユニット、コミュニティレポート、共変量のデータが含まれます。
この詳細な構造により、システムは以下のような高度な機能を提供できます:
- 多角的な情報検索: 異なるデータタイプから関連情報を効率的に取得します。
- コンテキスト豊富な応答: 複数のデータソースからの情報を統合して、より包括的な応答を生成します。
- 柔軟なクエリ処理: ユーザーのクエリに応じて、適切なデータ取得メソッドを選択します。
- データ間の関連性の活用: エンティティ、関係、テキストユニットなど、異なるデータタイプ間の関連性を利用して、より深い洞察を提供します。
この構造は、インデックス作成プロセスで生成された複雑なデータモデルを効果的に活用し、ユーザーのクエリに対して高度で関連性の高い応答を生成することができます。
Index, Query の PFD
Index と Query のプロセスフロー図(PFD:Process Flow Diagram)をそれぞれ作成します。
まず、Indexのプロセスフロー図を作成します。
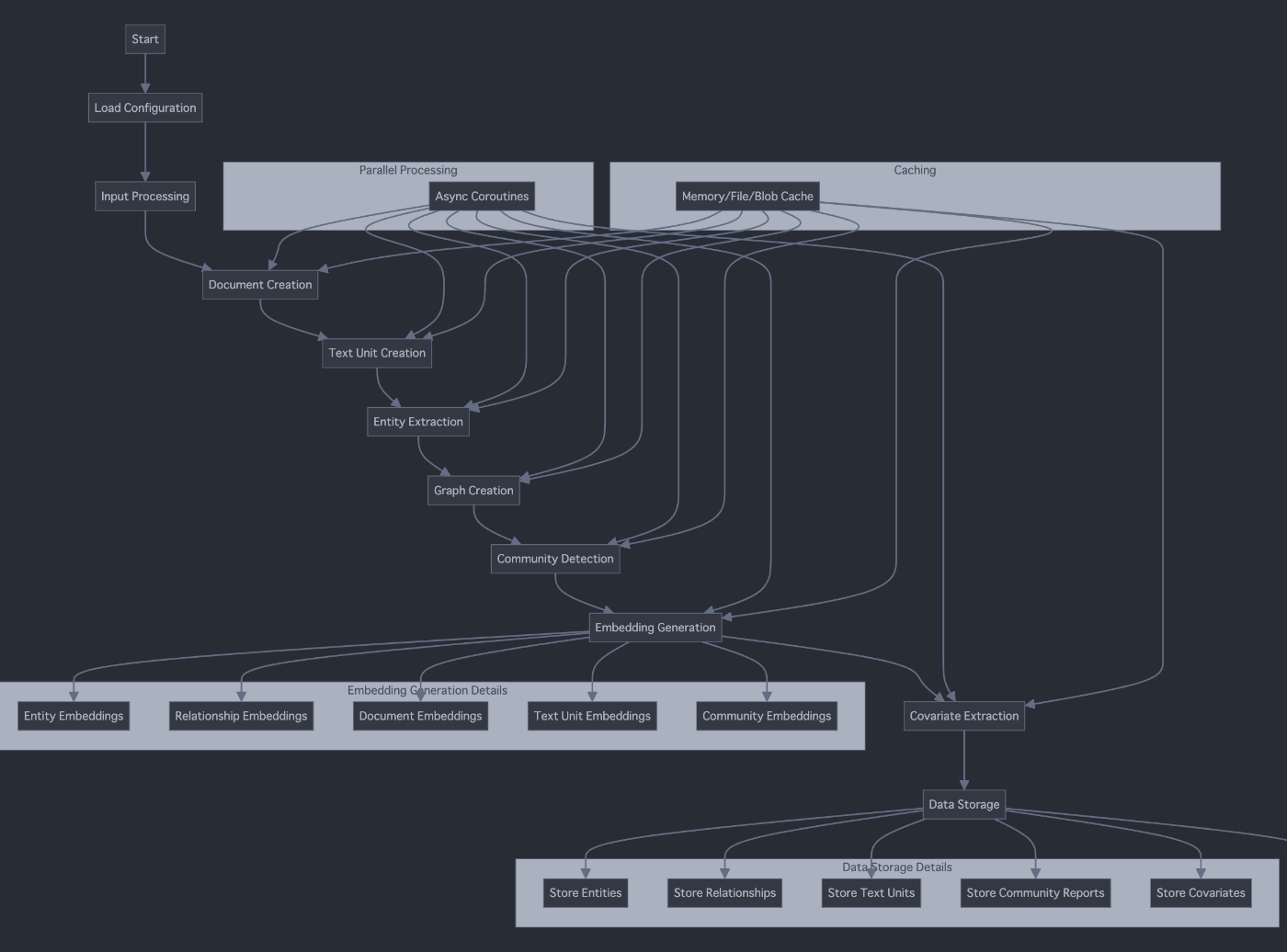
次に、Queryのプロセスフロー図を作成します。
これらの図は、IndexとQueryのプロセスフローを視覚的に表現しています。
-
Index プロセスフロー:
- 設定の読み込みから始まり、入力処理、ドキュメント作成、テキストユニット作成、エンティティ抽出、グラフ作成、コミュニティ検出、埋め込み生成、共変量抽出を経て、最終的にデータストレージに至ります。
- 並列処理とキャッシングが全体のプロセスをサポートしています。
- 埋め込み生成と最終的なデータストレージの詳細も示されています。
-
Query プロセスフロー:
- ユーザークエリの受信から始まり、クエリ処理、各種データ(エンティティ、関係、テキストユニット、コミュニティレポート、共変量)の取得を行います。
- 取得されたデータを使用してコンテキストを構築し、LLM処理を経て応答を生成します。
- 各データ取得プロセスの詳細(例:エンティティ取得における様々な検索方法)も示されています。
- コンテキスト構築の詳細なステップも含まれています。
これらの図は、IndexとQueryの各プロセスの主要なステップと、それらの相互関係を明確に示しています。これにより、システムの全体的な動作とデータの流れをより良く理解することができます。
from typing import List, Dict, Optional, Any
from dataclasses import dataclass
from abc import ABC, abstractmethod
# Data Models
@dataclass
class Document:
id: str
content: str
metadata: Dict[str, Any]
@dataclass
class TextUnit:
id: str
text: str
document_id: str
metadata: Dict[str, Any]
@dataclass
class Entity:
id: str
name: str
type: str
description: Optional[str]
metadata: Dict[str, Any]
@dataclass
class Relationship:
id: str
source_id: str
target_id: str
type: str
metadata: Dict[str, Any]
@dataclass
class Community:
id: str
entities: List[str]
metadata: Dict[str, Any]
@dataclass
class Covariate:
id: str
entity_id: str
type: str
value: Any
metadata: Dict[str, Any]
# Index Process
class Configuration:
def load(self, config_file: str) -> Dict[str, Any]:
pass
class InputProcessor:
def process(self, input_data: Any) -> List[Document]:
pass
class DocumentCreator:
def create(self, processed_data: List[Document]) -> List[Document]:
pass
class TextUnitCreator:
def create(self, documents: List[Document]) -> List[TextUnit]:
pass
class EntityExtractor:
def extract(self, text_units: List[TextUnit]) -> List[Entity]:
pass
class GraphCreator:
def create(self, entities: List[Entity]) -> List[Relationship]:
pass
class CommunityDetector:
def detect(self, entities: List[Entity], relationships: List[Relationship]) -> List[Community]:
pass
class EmbeddingGenerator:
def generate_entity_embeddings(self, entities: List[Entity]) -> Dict[str, List[float]]:
pass
def generate_relationship_embeddings(self, relationships: List[Relationship]) -> Dict[str, List[float]]:
pass
def generate_document_embeddings(self, documents: List[Document]) -> Dict[str, List[float]]:
pass
def generate_text_unit_embeddings(self, text_units: List[TextUnit]) -> Dict[str, List[float]]:
pass
def generate_community_embeddings(self, communities: List[Community]) -> Dict[str, List[float]]:
pass
class CovariateExtractor:
def extract(self, entities: List[Entity], text_units: List[TextUnit]) -> List[Covariate]:
pass
class DataStorage(ABC):
@abstractmethod
def store_entities(self, entities: List[Entity]) -> None:
pass
@abstractmethod
def store_relationships(self, relationships: List[Relationship]) -> None:
pass
@abstractmethod
def store_text_units(self, text_units: List[TextUnit]) -> None:
pass
@abstractmethod
def store_community_reports(self, communities: List[Community]) -> None:
pass
@abstractmethod
def store_covariates(self, covariates: List[Covariate]) -> None:
pass
class IndexProcessor:
def __init__(self):
self.config: Configuration = Configuration()
self.input_processor: InputProcessor = InputProcessor()
self.document_creator: DocumentCreator = DocumentCreator()
self.text_unit_creator: TextUnitCreator = TextUnitCreator()
self.entity_extractor: EntityExtractor = EntityExtractor()
self.graph_creator: GraphCreator = GraphCreator()
self.community_detector: CommunityDetector = CommunityDetector()
self.embedding_generator: EmbeddingGenerator = EmbeddingGenerator()
self.covariate_extractor: CovariateExtractor = CovariateExtractor()
self.data_storage: DataStorage = DataStorage()
def process(self, config_file: str, input_data: Any) -> None:
config = self.config.load(config_file)
processed_data = self.input_processor.process(input_data)
documents = self.document_creator.create(processed_data)
text_units = self.text_unit_creator.create(documents)
entities = self.entity_extractor.extract(text_units)
relationships = self.graph_creator.create(entities)
communities = self.community_detector.detect(entities, relationships)
entity_embeddings = self.embedding_generator.generate_entity_embeddings(entities)
relationship_embeddings = self.embedding_generator.generate_relationship_embeddings(relationships)
document_embeddings = self.embedding_generator.generate_document_embeddings(documents)
text_unit_embeddings = self.embedding_generator.generate_text_unit_embeddings(text_units)
community_embeddings = self.embedding_generator.generate_community_embeddings(communities)
covariates = self.covariate_extractor.extract(entities, text_units)
self.data_storage.store_entities(entities)
self.data_storage.store_relationships(relationships)
self.data_storage.store_text_units(text_units)
self.data_storage.store_community_reports(communities)
self.data_storage.store_covariates(covariates)
# Query Process
class QueryProcessor:
def process(self, query: str) -> Dict[str, Any]:
pass
class Retriever(ABC):
@abstractmethod
def retrieve(self, query: Dict[str, Any]) -> List[Any]:
pass
class EntityRetriever(Retriever):
def retrieve(self, query: Dict[str, Any]) -> List[Entity]:
pass
class RelationshipRetriever(Retriever):
def retrieve(self, query: Dict[str, Any]) -> List[Relationship]:
pass
class TextUnitRetriever(Retriever):
def retrieve(self, query: Dict[str, Any]) -> List[TextUnit]:
pass
class CommunityReportRetriever(Retriever):
def retrieve(self, query: Dict[str, Any]) -> List[Community]:
pass
class CovariateRetriever(Retriever):
def retrieve(self, query: Dict[str, Any]) -> List[Covariate]:
pass
class ContextBuilder:
def build(self, retrieved_data: Dict[str, List[Any]]) -> Dict[str, Any]:
pass
class LLMProcessor:
def process(self, context: Dict[str, Any], query: Dict[str, Any]) -> str:
pass
class ResponseGenerator:
def generate(self, llm_output: str) -> str:
pass
class QueryEngine:
def __init__(self):
self.query_processor: QueryProcessor = QueryProcessor()
self.entity_retriever: EntityRetriever = EntityRetriever()
self.relationship_retriever: RelationshipRetriever = RelationshipRetriever()
self.text_unit_retriever: TextUnitRetriever = TextUnitRetriever()
self.community_report_retriever: CommunityReportRetriever = CommunityReportRetriever()
self.covariate_retriever: CovariateRetriever = CovariateRetriever()
self.context_builder: ContextBuilder = ContextBuilder()
self.llm_processor: LLMProcessor = LLMProcessor()
self.response_generator: ResponseGenerator = ResponseGenerator()
def process_query(self, user_query: str) -> str:
processed_query = self.query_processor.process(user_query)
entities = self.entity_retriever.retrieve(processed_query)
relationships = self.relationship_retriever.retrieve(processed_query)
text_units = self.text_unit_retriever.retrieve(processed_query)
community_reports = self.community_report_retriever.retrieve(processed_query)
covariates = self.covariate_retriever.retrieve(processed_query)
context = self.context_builder.build({
'entities': entities,
'relationships': relationships,
'text_units': text_units,
'community_reports': community_reports,
'covariates': covariates
})
llm_output = self.llm_processor.process(context, processed_query)
response = self.response_generator.generate(llm_output)
return response
# Main execution
class GraphRAG:
def __init__(self):
self.index_processor: IndexProcessor = IndexProcessor()
self.query_engine: QueryEngine = QueryEngine()
def index(self, config_file: str, input_data: Any) -> None:
self.index_processor.process(config_file, input_data)
def query(self, user_query: str) -> str:
return self.query_engine.process_query(user_query)
# Usage
graph_rag = GraphRAG()
graph_rag.index('config.yaml', 'input_data.json')
response = graph_rag.query("User question here")
print(response)
community、entity、community reportの関連性をより明確に表現するために、mermaidを使ってER図(Entity-Relationship Diagram)風の図を作成します。
この図は以下の関連性を示しています:
-
Community と Entity:
- 一つのCommunityは複数のEntityを含むことができます(1対多の関係)。
- これは
containsという関係で表現されています。
-
Community と Relationship:
- 一つのCommunityは複数のRelationshipを含むことができます(1対多の関係)。
- これも
containsという関係で表現されています。
-
Community と Community Report:
- 各Communityは一つのCommunity Reportを持ちます(1対1の関係)。
- これは
has reportという関係で表現されています。
-
Community の階層構造:
- 一つのCommunityは複数のサブCommunityを持つことができます(1対多の関係)。
- これは
has sub-communitiesという関係で表現されています。
-
Entity と Relationship:
- 一つのEntityは複数のRelationshipに参加できます(1対多の関係)。
- これは
participates inという関係で表現されています。
-
各要素の属性:
- Community、Entity、Relationship、Community Reportそれぞれの主要な属性が表示されています。
この図から、以下のような重要な点が読み取れます:
- Communityは階層構造を持ち、EntityとRelationshipをグループ化する役割を果たしています。
- 各Communityには対応するCommunity Reportがあり、そのコミュニティの概要や詳細情報を提供します。
- EntityとRelationshipはグラフの基本構成要素であり、Communityはこれらをより大きな文脈でまとめる役割を果たしています。
- Community Reportは、特定のCommunityに関する集約された情報や分析結果を表現しています。
この構造により、GraphRAGシステムは大規模で複雑なグラフデータを効率的に組織化し、異なるレベルの抽象化(個々のEntity/Relationshipレベルから、Community全体のレベルまで)を提供することができます。
プロンプト
これらのプロンプトは、GraphRAGライブラリの核心部分であるCreator周りのプロセスで使用されています。これらのプロンプトを使用して、LLM(大規模言語モデル)に特定のタスクを実行させています。主要なプロンプトとその目的を説明します:
-
community_report_rating.py:
- GENERATE_REPORT_RATING_PROMPT: このプロンプトは、与えられたテキストの重要性を特定のドメインとペルソナの文脈で評価するために使用されます。0から10のスケールで重要性を評価します。
-
community_reporter_role.py:
- GENERATE_COMMUNITY_REPORTER_ROLE_PROMPT: このプロンプトは、コミュニティ分析を行うためのロール定義を作成するために使用されます。特定のドメインと入力テキストに基づいて、適切なロールを生成します。
-
domain.py:
- GENERATE_DOMAIN_PROMPT: このプロンプトは、与えられたテキストに基づいて、そのテキストが属する適切なドメインを特定するために使用されます。
-
entity_relationship.py:
- ENTITY_RELATIONSHIPS_GENERATION_PROMPT: このプロンプトは、テキストから特定のタイプのエンティティを抽出し、それらの間の関係を特定するために使用されます。
- ENTITY_RELATIONSHIPS_GENERATION_JSON_PROMPT: 上記と同様ですが、出力をJSON形式で生成します。
- UNTYPED_ENTITY_RELATIONSHIPS_GENERATION_PROMPT: 事前に定義されたエンティティタイプを使用せずに、テキストからエンティティと関係を抽出するために使用されます。
-
entity_types.py:
- ENTITY_TYPE_GENERATION_PROMPT: このプロンプトは、与えられたタスクとテキストに基づいて、関連するエンティティタイプを生成するために使用されます。
- ENTITY_TYPE_GENERATION_JSON_PROMPT: 上記と同様ですが、出力をJSON形式で生成します。
これらのプロンプトを使用することで、GraphRAGシステムは以下のような処理を行っています:
- テキストの重要性評価
- コミュニティ分析のためのロール定義
- テキストのドメイン分類
- エンティティと関係の抽出
- エンティティタイプの特定
これらのプロセスは、前に説明したTextUnit、Entity、Relationship、Communityの抽出と密接に関連しています。LLMを使用してこれらのタスクを実行することで、システムは生のテキストデータから構造化された知識グラフを効果的に構築できます。
例えば、ENTITY_RELATIONSHIPS_GENERATION_PROMPTを使用して、TextUnitからEntityとRelationshipを抽出し、ENTITY_TYPE_GENERATION_PROMPTを使用して適切なエンティティタイプを特定します。これらの結果を組み合わせることで、豊富な情報を持つ知識グラフが作成されます。
このアプローチにより、システムは柔軟性と適応性を持ち、様々なドメインや文脈に対応できるようになっています。
Louvain ClusteringとLeiden Clusteringは、ネットワーク内のコミュニティ(密に結合したノードの集合)を検出するためのアルゴリズムです。以下にそれぞれの主な特徴をまとめます:
Louvain Clustering
- グラフクラスタリングの一種で、大規模なネットワークを高速に分割できる
- モジュラリティ(コミュニティ構造の品質を測る指標)の最適化に基づいている
- 階層的なアルゴリズムで、反復的にコミュニティをマージしていく
- 広く使われており、高速で良好な結果を得られることが知られている
- 実行時間はO(n log n)程度と推定される(nはノード数)
Leiden Clustering
- Louvainアルゴリズムの改良版として開発された
- Louvainの短所である「うまく接続されていないコミュニティ」の問題に対処
- コミュニティの接続性を保証する
- 定期的にコミュニティをランダムに小さな接続されたコミュニティに分解する
- Louvainよりも高品質なコミュニティを検出できる
- 実行速度もLouvainと同等かそれ以上に高速
両アルゴリズムの主な違い:
-
接続性の保証:Leidenはコミュニティの接続性を保証するが、Louvainにはその保証がない
-
精度:Leidenの方が一般的により高品質なコミュニティを検出できる
-
安定性:Leidenはより安定した結果を生成する傾向がある
-
実装の複雑さ:Leidenの方がアルゴリズムの実装がやや複雑
どちらのアルゴリズムも、ソーシャルネットワーク分析、生物学的ネットワーク、引用ネットワークなど、様々な分野で広く使用されています。一般的に、Leidenアルゴリズムはより新しく改良されたアルゴリズムであるため、可能であればLeidenを使用することが推奨されますが、具体的な使用ケースや実装の容易さによってはLouvainも依然として有効な選択肢となります。
Louvain法のアルゴリズムは、大規模なネットワークのコミュニティ構造を効率的に検出するための手法です。以下に、その具体的な手順を説明します:
Louvain法のアルゴリズム手順
-
初期化
- 各ノードを独立したコミュニティとして扱う[1][2]
-
第1段階:局所的な最適化
- 各ノードについて、以下の操作を繰り返す:
- 隣接するコミュニティに移動した場合のモジュラリティの変化を計算
- モジュラリティが最大増加するコミュニティに移動
- この過程をモジュラリティの増加が見られなくなるまで繰り返す[2][3]
- 各ノードについて、以下の操作を繰り返す:
-
第2段階:ネットワークの圧縮
- 第1段階で形成されたコミュニティを1つのノードとみなす
- コミュニティ間のエッジの重みを合計し、新たなネットワークを構築[1][2]
-
繰り返し
- 第1段階と第2段階を、モジュラリティの増加が見られなくなるまで繰り返す[2][3]
アルゴリズムの特徴
-
階層的構造:このプロセスにより、ネットワークの階層的なコミュニティ構造が自然に得られる[2]
-
効率性:大規模ネットワークに対しても高速に動作し、計算量はO(n log n)程度と推定される(nはノード数)[3]
-
モジュラリティの最適化:各ステップでモジュラリティを最大化することで、高品質なコミュニティ分割を実現[2][3]
-
柔軟性:異なる解像度のコミュニティ構造を検出可能[3]
Louvain法は、その効率性と有効性から、ソーシャルネットワーク分析、生物学的ネットワーク、引用ネットワークなど、様々な分野で広く使用されています。ただし、「うまく接続されていないコミュニティ」を生成する可能性があるという短所も指摘されており、これに対処するために改良版のLeidenアルゴリズムが開発されています[3]。
GraphML形式は、グラフ構造を記述するためのXMLベースのファイルフォーマットです。主な特徴は以下の通りです:
-
XMLを使用してグラフを記述するため、人間にも機械にも読みやすい形式です[1][3]。
-
グラフの構造的特性を記述する言語コアと、アプリケーション固有のデータを追加するための柔軟な拡張メカニズムで構成されています[4]。
-
以下のようなグラフの表現をサポートしています[4][6]:
- 有向グラフ、無向グラフ、混合グラフ
- ハイパーグラフ
- 階層的グラフ
- グラフィカルな表現
- 外部データへの参照
- アプリケーション固有の属性データ
-
グラフ描画コミュニティの共同努力により、グラフ構造データを交換するための共通フォーマットとして定義されました[6]。
-
基本的な構造は以下の通りです[3][6]:
-
<graphml>要素がファイルのルート - その中に1つ以上の
<graph>要素 -
<graph>要素内に<node>と<edge>要素が含まれる - 各
<node>は一意のid属性を持つ - 各
<edge>はsourceとtarget属性を持ち、エッジの端点を指定する
-
-
追加データは
<key>要素で宣言し、<data>要素に実際の値を含めることができます[3]。 -
多くのグラフ関連ソフトウェアやライブラリ(yEd, Gephi, NetworkX など)でサポートされています[7][9][10]。
GraphML形式は、その柔軟性と拡張性により、グラフデータの保存や交換に広く使用されています。
Node2Vecアルゴリズムは、グラフ構造データからノードの特徴量ベクトル(埋め込み表現)を学習するためのアルゴリズムです。主な特徴は以下の通りです:
-
グラフ上のランダムウォークを用いてノードの近傍をサンプリング
-
サンプリングされた近傍情報を使ってSkip-gramモデル(Word2Vecと同様)で埋め込み表現を学習
-
2つのパラメータp(戻り確率)とq(探索範囲)を導入し、ランダムウォークの挙動を制御
- p: 直前のノードに戻る確率を制御
- q: 遠くのノードへ移動する確率を制御
-
これにより局所的構造(同じコミュニティ内のノード)と大域的構造(構造的に似た役割のノード)の両方を捉えられる
-
学習された埋め込み表現は、ノード分類、リンク予測、クラスタリングなど様々なタスクに利用可能
-
大規模グラフにも適用可能なスケーラブルなアルゴリズム
Node2Vecは、グラフデータの特徴量抽出を効率的に行え、様々な下流タスクに活用できる汎用的な手法として広く使われています。DeepWalkなどの先行研究を拡張し、より柔軟なグラフ探索を可能にした点が特徴です。
Node2Vecアルゴリズム
Node2Vecは、ネットワーク内のノードに対して連続的な特徴表現を学習するためのアルゴリズムフレームワークです。自然言語処理で使用されるword2vecアルゴリズムのアイデアを基に、グラフ構造データに適応させたものです。
主要な概念
-
ランダムウォーク: Node2Vecは、ノードのネットワーク近傍を探索するために偏りのあるランダムウォークを使用します。
-
探索の柔軟性: このアルゴリズムは、ノードの近傍の幅優先探索(BFS)と深さ優先探索(DFS)のバランスを取ります。
-
埋め込み: ノードのネットワーク近傍を保持する低次元ベクトル空間へのノードのマッピングを学習します。
アルゴリズムのステップ
-
パラメータの定義:
- 埋め込みの次元数 (d)
- ソースごとのウォーク長 (l)
- ソースごとのウォーク回数 (r)
- 返戻パラメータ (p)
- インアウトパラメータ (q)
-
遷移確率の計算:
- p と q を使用してランダムウォークに偏りをつける
- p はノードを即座に再訪問する可能性を制御
- q は探索戦略(BFS vs DFS)を制御
-
ランダムウォークの生成:
- 各ノードに対して、長さ l のランダムウォークを r 回生成
- 計算された遷移確率を使用
-
埋め込みの学習:
- Skip-gramモデルを使用してノード表現を学習
- 特定のウィンドウ内のコンテキストノードを予測するように最適化
利点
- ノード間のより高次の近接性を保持
- 異なるネットワーク構造(同類性と構造的等価性)を捉える柔軟性
- 大規模ネットワークにスケーラブル
応用分野
- ノード分類
- リンク予測
- コミュニティ検出
- 推薦システム
数学的基礎
Node2Vecの核となる最適化目的は以下のように表現できます:
最大化 ∑(u∈V) log Pr(N_s(u) | f(u))
ここで:
- V はノードの集合
- N_s(u) はサンプリング戦略 s によって生成されたノード u のネットワーク近傍
- f(u) はノード u の特徴表現
この目的関数は確率的勾配降下法を用いて最適化されます。