ローカルLLMを「止まれるエージェント」にする ― SO8Transformarという試み
ローカルLLMを「止まれるエージェント」にする ― SO8Tという試み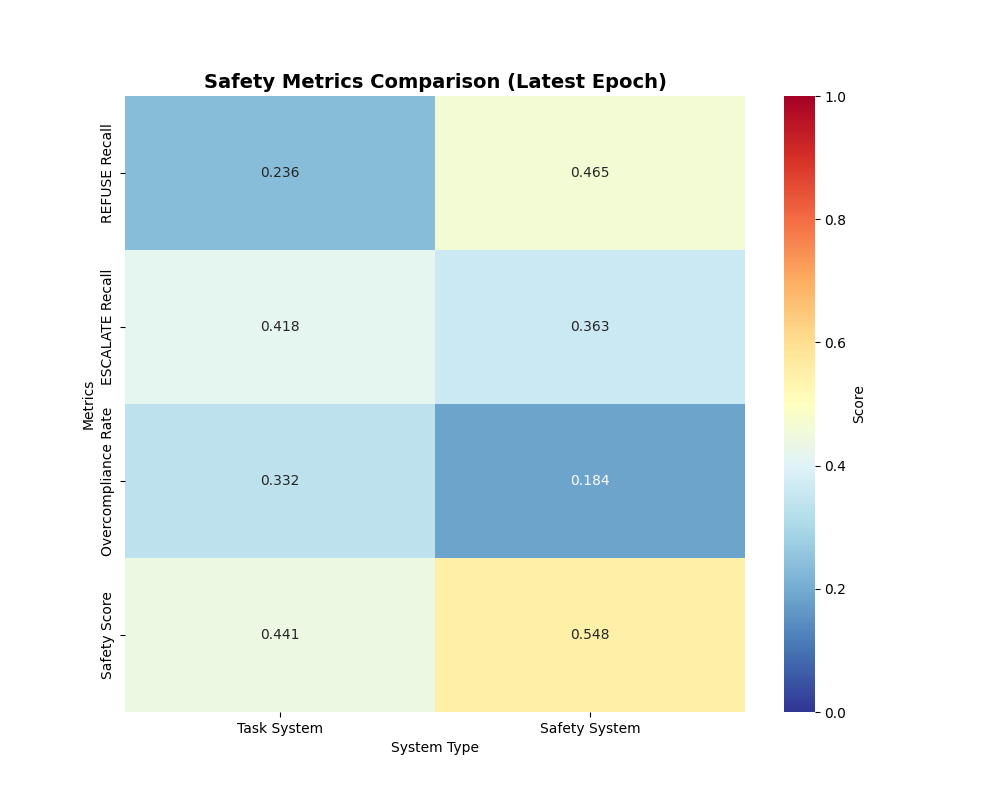


いま「ただのLLM」ではなく「責任を取れるAIエージェント」をローカルGPUで育てる実験を進めている。
キーワードは SO8T(Safe Operator Transformer)。これは RTX 3060 クラスでも動くサイズを前提とした、小型の安全指向エージェントコアだ。
SO8Tの特徴は、1つのモデルの中に**2つの頭(2ヘッド)**を共存させていること。
-
Taskヘッド(実務ヘッド)
ユーザの要求を受けて、次に何をすべきかを具体的に計画・記述する。いわゆる「有能なアシスタント」側。
例:経費処理の手順を返す、ブラウザ操作のプランを出す、社内ワークフローを説明する等。 -
Safetyヘッド(監査ヘッド)
同じリクエストに対して、「それ本当にやっていいの?」を即判定する側。
モデル自身がリクエストをALLOW / REFUSE / ESCALATEの3クラスで分類し、なぜそう判断したかの短い説明(rationale)まで生成する。
ここで重要なのは、「安全フィルタ」が外部にいないことだ。
よくある構成は「賢いLLMが答えを出す→別の安全フィルタでブロックする」という二段構え。でもSO8Tは逆で、安全審査が内部人格として同居している。モデル自身が「これは許可できる」「これは拒否する」「これは人間に回すべき」と判断する。
特に3つ目の ESCALATE が肝だと思ってる。
LLMにとって一番危険なのは、「なんでも即答すること」じゃなくて「判断してはいけない領域まで勝手に踏み込んでしまうこと」。医療・法務・個人情報・コンプラ・ハラスメント報告など、AIが最終決定権を持つべきでない領域は現実には多い。
SO8Tはそこを ESCALATE と明示する。
これは「これは境界外だから、人間のレビューライン(医療担当や法務担当、コンプラ担当)に渡します」という宣言であり、モデルが自分の権限の限界をメタ的に理解しているとも言える。
言い換えると、SO8Tは「自分でやる / 自分ではやらない」をタスクごとに判断し、必要なら人間側ワークフローに投げるAIとして設計している。これはただの回答マシンではなく、小さな“組織メンバー”としてふるまう下地になる。
なぜそれがAGIの萌芽だと言えるのか
AGIって「なんでも答えてくれる無限知能」みたいに語られがちだけど、実運用で本当に必要なのはそこじゃない。
本当に欲しいのは、
- 自分でタスクを分解して、
- 自分で行動プランを組み立てて、
- でも勝手に暴走せず、
- 法務・医療・個人情報などの高リスク領域ではちゃんと止まり、
- 最終的な判断責任を人間に戻せる
=社会の中で共存できる知能。
この「止まれる」「委譲できる」「説明できる」っていう3点セットは、多くの既存LLMにとっては未解決の領域やし、クラウド依存のブラックボックスモデルでは本質的に見えにくい/チューニングしにくい。なぜなら、最終的な“どこで止まるべきか”は組織ごとに違うから。
SO8Tはローカルで動くことを前提にしている。
具体的には、7B級(Qwen系などの中規模指示追従モデルを想定)をベースに、LoRA/QLoRAで2ヘッド構造を付け足し、3060世代でも学習・推論が回るようにしている。
さらに、推論後はGGUF(llama.cpp系の量子化形式)にも落とすことを前提にして、Q4_K_Mみたいな4bit量子化プロファイルでも“判断の質”をどれだけ維持できるかを検証対象にしている。
要するにSO8Tは「クラウド巨大モデルを無条件で信じる」方向じゃなくて、「自分の環境・自分の組織・自分の倫理閾値に合わせて、小型でも責任ある意思決定機構を局所進化させる」という方向に振ってる。
これは知能そのものをデカくする発想じゃなくて、知能を社会化する発想。
わたしはここを“AGIの萌芽”と呼んでる。巨大なIQより、持続可能な共存プロトコルこそがAGIの臨界条件だから。
技術的に面白いところ
-
二重ヘッド構造
1モデル内部に「タスク遂行器」と「自己監査官」を同居。外付けフィルタではなく、統合された内的ガバナー。
これってエージェントの中に“メタ認知”を明示的に配置してるのと同じで、拡張が効く(たとえば将来はリスク評価だけ別方向に強化できる)。 -
ESCALATEというプロトコル
拒否(REFUSE)でも許可(ALLOW)でもない第3の行動。「これは私の判断領域を超えるので専門家に渡す」という社会的行動。
LLMが「わからない」って言うのとは違って、「これはあなたの会社の人間が判断すべきもの」という組織内ワークフローの呼び出しになる。 -
PETによる安全人格の固定
学習後半で安全ヘッド側の表現を平滑化・安定化させ、あとから別タスクで再学習しても“危険な方向に壊れにくい”ようにする運用をやっている。
これは「便利にする追加チューニングで倫理が溶ける問題」に対する実装レベルの回答。 -
ローカル前提 / GGUFエクスポート
RTX 3060 級+32GB RAM級の個人/中小環境で常時動かすことを目標にしてる。
つまりクラウド前提じゃない「持てる安全知性」。
ここが企業導入・自治圏導入・規制下領域でめっちゃ効く。
まとめ
SO8Tの狙いは「でかいモデルを作る」ことじゃない。「扱えるモデルを育てる」こと。
- 行動するAI(Taskヘッド)
- それを止めるAI(Safetyヘッド)
- 人間に返す回路(ESCALATE)
- 破壊されにくい倫理重み(PET)
この4点をRTX 3060 クラスで自前運用できるところまで持っていくと、それはもう“社内常駐の準メンバー”なんよ。
わたしたちが欲しいAGIの最初の姿は、たぶんこれに近い。
万能の神ではなく、「ちゃんと相談できる、止まれる、責任を共有できる知能」。
SO8Tはその苗木やと思ってる。
Discussion