GitHubリポジトリを爆速で全文検索
GitHubリポジトリを爆速で全文検索
概要
MeilisearchでGitHubリポジトリに対して全文検索できるようにしてみました。
100行程度のコードで簡単にできるので共有します。
- 500ファイルぐらいなら100ミリ秒で検索できる!
- コードは最小限で、すぐ試せる
- ファイルの取捨選択や成型や検索方法も好きにカスタマイズできる
全文検索エンジンを使ったちょっとした実験として、休日のお昼に試してみるのはいかがでしょう?
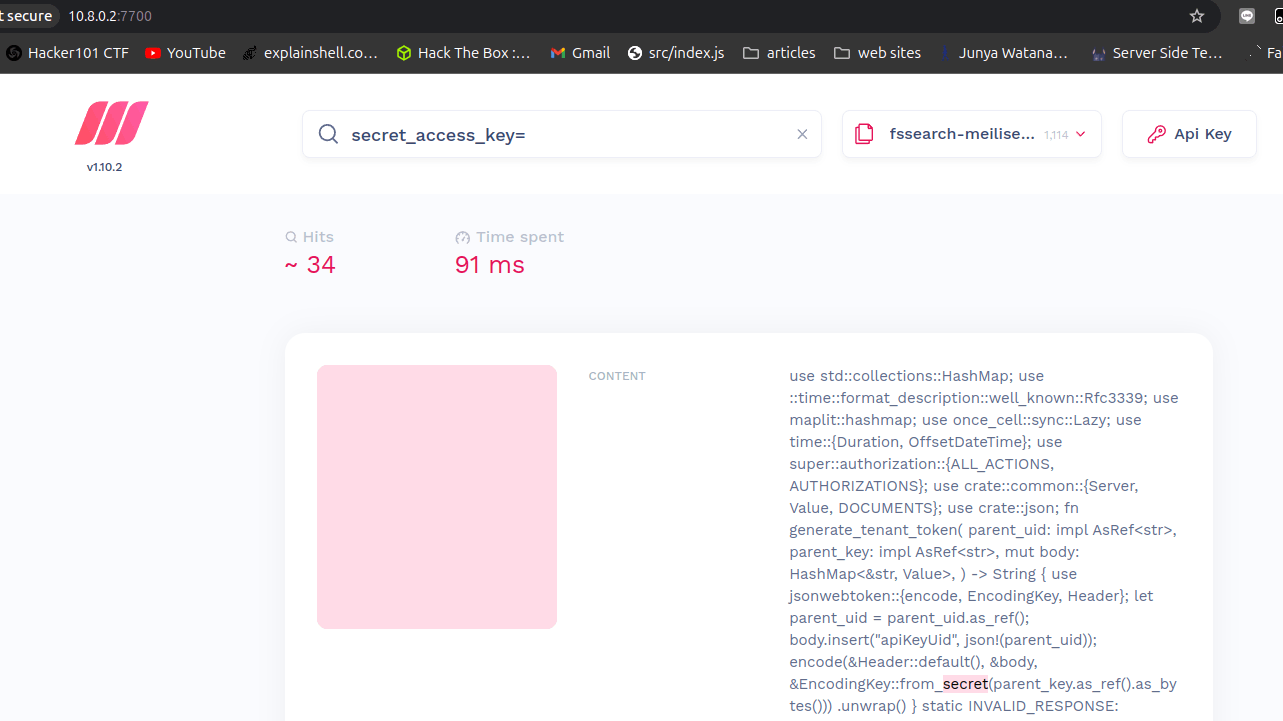
Meilisearchのソースコードに対して全文検索を行うとこんな感じです👇
githubで検索した場合はこちら👇

インフラ準備
- pipで必要な物をインストール (省略)
- dockerとdocker-composeをインストール (省略)
services:
meilisearch:
environment:
- MEILI_MASTER_KEY=meili-master-key
image: getmeili/meilisearch:latest
ports:
- 7700:7700
volumes:
- ./meili-data:/meili_data
docker-compose.yamlというファイルにこれを書いてdocker compose up
構成図
ドメイン!
プロジェクトの中核となる「ドメイン」は、特定の技術(ElasticSearchやMeilisearchなど)に依存しない、純粋なビジネスロジックを表現する部分です。
たとえば「コンテンツを収集して検索できるようにする」という機能は、「どこかにコンテンツがある」「コンテンツを検索用に加工できる」「どこかの検索システムに登録できる」ことだけを前提に設計できます。コンテンツがGitリポジトリにあるのかデータベースにあるのか、ipynbファイルの加工なのか他の形式の加工なのか、検索システムがElasticSearchなのかMeilisearchなのかは、この時点では考えなくて良いのです。
このように技術的な実装から切り離すことで、仕様変更に強く、テストが書きやすく、コードの意図が明確になります。以下のコードは、そのドメインレイヤーの実装です。
Indexer
- インデックス作成処理全体を制御
- FileProcessor で処理して Uploader で検索エンジンに登録
class Indexer:
def __init__(self, processor: FileProcessor, uploader: Uploader):
self.processor = processor
self.uploader = uploader
def index(self) -> None:
documents = self.processor.process()
if documents:
self.uploader.upload(documents)
FileProcessor
- ドキュメントのリストを生成
- Collector でコンテンツを収集し、Formatter で検索用データに変換
class FileProcessor:
def __init__(self, collector: Collector, formatter: Formatter):
self.collector = collector
self.formatter = formatter
def process(self) -> list[dict]:
documents = []
for filepath, content in self.collector.collect():
document = self.formatter.format(filepath, content)
documents.append(document)
return documents
Collector
- コンテンツの収集を担当
- ファイルパスとコンテンツのペアを生成
class Collector(Protocol):
def collect(self) -> Iterable[Tuple[str, str]]:
"""
コンテンツの収集を行う
Returns:
Iterable[Tuple[str, str]]: (filepath, content)のタプルのイテラブル
"""
...
Formatter
- 収集したコンテンツを検索用データに変換
class Formatter(Protocol):
def format(self, filepath: str, content: str) -> dict:
"""
コンテンツを検索用データに変換する
Args:
filepath: ファイルパス
content: ファイルの内容
Returns:
dict: 検索用のドキュメント
"""
...
Uploader
- 検索エンジンへのデータを一括登録
class Uploader(Protocol):
def upload(self, documents: list[dict]) -> None:
"""
検索エンジンにデータを登録する
Args:
documents: アップロード対象のドキュメントリスト
"""
...
DI
全文検索システムの組み立て方を簡単に説明しましょう!
以下のような関数を追加することで、システムの各部品を簡単に組み立てることができます:
def create_indexer(collector: Collector, formatter: Formatter, uploader: Uploader) -> Indexer:
processor = FileProcessor(collector, formatter)
return Indexer(processor, uploader)
この関数を使うと、例えばGitHubリポジトリを検索したい場合は:
# 必要な部品を用意
git_collector = GitCollector("https://github.com/user/repo.git")
doc_formatter = DocumentFormatter()
search_uploader = MeilisearchUploader("http://localhost:7700", "your-key", "docs")
# 組み立てる
indexer = create_indexer(git_collector, doc_formatter, search_uploader)
# 実行
indexer.index()
このように、必要な部品を選んで渡すだけで、簡単にシステムを組み立てることができます!
実は、この設計手法には専門用語があります。これは「依存性の注入(Dependency Injection、DI)」と呼ばれる設計パターンです。
DIの良いところは:
- 部品を簡単に交換できる(例:GitCollectorをLocalCollectorに変更するだけ)
- テストが書きやすい(本物のGitHubの代わりにモックを使える)
- 再利用性が高い(同じIndexerを別の用途に転用できる)
このような柔軟な設計により、全文検索システムを様々な用途に合わせてカスタマイズできるようになっています。
アダプタ実装!
前章で示したドメインを、実際の技術を使って実装していきます。ここでは具体的に:
コンテンツの収集にはGitを
コンテンツの加工にはDocumentFormatterを
検索エンジンにはMeilisearchを
使用しています。
先ほどのドメインレイヤーで定義したインターフェース(Collector、Formatter、Uploader)に対して、それぞれの具体的な実装(GitCollector、DocumentFormatter、MeilisearchUploader)を提供します。この方式のメリットは、例えばGitをクラウドストレージに置き換えたい場合、新しいCloudStorageCollectorクラスを作るだけで、他のコードは一切変更する必要がないという点です。
また、これらの実装をopen-webuiのパイプラインとして統合することで、ブラウザから簡単に利用できるUIを提供しています。以下が各実装のコードです:
GitCollector
Git リポジトリからコンテンツを収集する Collector です:
- Git Python ライブラリを使用してファイル情報を取得
- ローカルおよびリモートの Git リポジトリに対応
- globで不要なファイルは除外
import os
import git
from typing import Optional, Iterable, Tuple, List
import tempfile
import shutil
from fnmatch import fnmatch
class GitCollector:
def __init__(self, repo_path: str, ignore_patterns: List[str] = []):
"""
Args:
repo_path: GitリポジトリのパスまたはURL
- ローカル: '/path/to/repo' や 'C:\\path\\to\\repo'
- リモート: 'https://github.com/user/repo.git' や 'git@github.com:user/repo.git'
ignore_patterns: 除外するファイルのglobパターンのリスト
例: ['*.pdf', 'test/**/*.py', 'tmp/*']
"""
self.is_remote = repo_path.startswith(
('http://', 'https://', 'git@', 'ssh://'))
if self.is_remote:
self.temp_dir = tempfile.mkdtemp()
self.repo = git.Repo.clone_from(repo_path, self.temp_dir)
self.repo_path = self.temp_dir
else:
self.repo_path = repo_path
self.repo = git.Repo(repo_path)
self.temp_dir = None
self.ignore_patterns = ignore_patterns or []
def _should_ignore(self, file_path) -> bool:
return any(fnmatch(file_path, pattern) for pattern in self.ignore_patterns)
def _read_file_content(self, file_path) -> Optional[str]:
"""ファイルの内容を読み込む。バイナリファイルの場合はNoneを返す"""
try:
with open(os.path.join(self.repo_path, file_path), 'r', encoding='utf-8') as f:
return f.read()
except (UnicodeDecodeError, IOError):
return None
def collect(self) -> Iterable[Tuple]:
"""Git管理下のファイルとその内容を収集する(ignore_patternsに一致するファイルは除外)"""
tracked_files = [item[0] for item in self.repo.index.entries]
for file_path in tracked_files:
if not self._should_ignore(file_path):
content = self._read_file_content(file_path)
if content is not None:
yield file_path, content
def __del__(self):
"""デストラクタ: リモートの場合、一時ディレクトリを削除"""
if self.temp_dir and os.path.exists(self.temp_dir):
shutil.rmtree(self.temp_dir)
DocumentFormatter
今のところ Jupyter Notebook ファイルに特化した Formatter です:
- ノートブックの実行結果を削除
- 不要なメタデータ(実行時間など)を除去
- セル情報だけを抽出して検索用データに変換
- ほかに成形したファイルがあればここでやる
import os
import uuid
import json
class DocumentFormatter:
def _normalize_source(self, source):
"""ソースコードの内容を正規化する"""
if isinstance(source, list):
# リストの場合は各要素を結合して1つの文字列にする
return ''.join(source)
return source
def _clean_notebook_content(self, content: str) -> str:
"""ipynbファイルから不要なメタデータを削除し、日本語を正規化する"""
try:
notebook = json.loads(content)
# セルの内容だけを抽出し、不要なメタデータを削除
cleaned_cells = []
for cell in notebook.get('cells', []):
# sourceの内容を正規化
source = self._normalize_source(cell.get('source', []))
cleaned_cell = {
'cell_type': cell.get('cell_type'),
'source': source # リストではなく文字列として保存
}
# outputsは実行結果なので削除(画像データなども含まれる)
if cell.get('cell_type') == 'code':
cleaned_cell['outputs'] = []
cleaned_cells.append(cleaned_cell)
# 最小限の情報だけを持つノートブックを作成
cleaned_notebook = {
'cells': cleaned_cells,
'nbformat': notebook.get('nbformat', 4),
'nbformat_minor': notebook.get('nbformat_minor', 0),
'metadata': {
'kernelspec': notebook.get('metadata', {}).get('kernelspec', {})
}
}
# ensure_ascii=Falseで日本語をそのまま出力
return json.dumps(cleaned_notebook, ensure_ascii=False, indent=2)
except json.JSONDecodeError:
return content
def format(self, filepath: str, content: str) -> dict:
"""検索用ドキュメントを作成する"""
ext = os.path.splitext(filepath)[1][1:] or 'no-extension'
# ipynbファイルの場合は内容をクリーニング
if ext == 'ipynb':
content = self._clean_notebook_content(content)
return {
'id': str(uuid.uuid4()),
'filepath': filepath,
'content': content,
'ext': ext
}
MeilisearchUploader
Meilisearch への登録を担当する Uploader です:
- Meilisearch Client を使用して一括登録
- インデックスの作成と更新
import meilisearch
class MeilisearchUploader:
def __init__(self, host: str, api_key: str, index_name: str):
self.client = meilisearch.Client(host, api_key)
self.index = self.client.index(index_name)
# 検索可能なフィールドとフィルタリング属性を設定
self.index.update_settings({
'searchableAttributes': [
'content',
'filepath'
],
'filterableAttributes': [
'ext'
]
})
def upload(self, documents: list[dict]) -> None:
"""ドキュメントをMeilisearchにアップロードする"""
if documents:
self.index.add_documents(documents)
print(f"Indexed {len(documents)} files successfully")
else:
print("No text files found to index")
まとめ (ソースコードあり)
最終的なソースコードは以下のようになります
from infra import searchengine
import json
import uuid
import shutil
import tempfile
from fnmatch import fnmatch
from typing import Optional, Iterable, Tuple, List
import git
import os
import meilisearch
from typing import Protocol, Iterable
from typing import Tuple
# Interfaces
class Collector(Protocol):
def collect(self) -> Iterable[Tuple[str, str]]:
"""
コンテンツの収集を行う
Returns:
Iterable[Tuple[str, str]]: (filepath, content)のタプルのイテラブル
"""
...
class Formatter(Protocol):
def format(self, filepath: str, content: str) -> dict:
"""
コンテンツを検索用データに変換する
Args:
filepath: ファイルパス
content: ファイルの内容
Returns:
dict: 検索用のドキュメント
"""
...
class Uploader(Protocol):
def upload(self, documents: list[dict]) -> None:
"""
検索エンジンにデータを登録する
Args:
documents: アップロード対象のドキュメントリスト
"""
...
# Domain Classes
class FileProcessor:
def __init__(self, collector: Collector, formatter: Formatter):
self.collector = collector
self.formatter = formatter
def process(self) -> list[dict]:
documents = []
for filepath, content in self.collector.collect():
document = self.formatter.format(filepath, content)
documents.append(document)
return documents
class Indexer:
def __init__(self, processor: FileProcessor, uploader: Uploader):
self.processor = processor
self.uploader = uploader
def index(self) -> None:
documents = self.processor.process()
if documents:
self.uploader.upload(documents)
def create_indexer(collector: Collector, formatter: Formatter, uploader: Uploader) -> Indexer:
processor = FileProcessor(collector, formatter)
return Indexer(processor, uploader)
class MeilisearchUploader:
def __init__(self, host: str, api_key: str, index_name: str):
self.client = meilisearch.Client(host, api_key)
self.index = self.client.index(index_name)
# 検索可能なフィールドとフィルタリング属性を設定
self.index.update_settings({
'searchableAttributes': [
'content',
'filepath'
],
'filterableAttributes': [
'ext'
]
})
def upload(self, documents: list[dict]) -> None:
"""ドキュメントをMeilisearchにアップロードする"""
if documents:
self.index.add_documents(documents)
print(f"Indexed {len(documents)} files successfully")
else:
print("No text files found to index")
class GitCollector:
def __init__(self, repo_path: str, ignore_patterns: List[str] = []):
"""
Args:
repo_path: GitリポジトリのパスまたはURL
- ローカル: '/path/to/repo' や 'C:\\path\\to\\repo'
- リモート: 'https://github.com/user/repo.git' や 'git@github.com:user/repo.git'
ignore_patterns: 除外するファイルのglobパターンのリスト
例: ['*.pdf', 'test/**/*.py', 'tmp/*']
"""
self.is_remote = repo_path.startswith(
('http://', 'https://', 'git@', 'ssh://'))
if self.is_remote:
self.temp_dir = tempfile.mkdtemp()
self.repo = git.Repo.clone_from(repo_path, self.temp_dir)
self.repo_path = self.temp_dir
else:
self.repo_path = repo_path
self.repo = git.Repo(repo_path)
self.temp_dir = None
self.ignore_patterns = ignore_patterns or []
def _should_ignore(self, file_path) -> bool:
return any(fnmatch(file_path, pattern) for pattern in self.ignore_patterns)
def _read_file_content(self, file_path) -> Optional[str]:
"""ファイルの内容を読み込む。バイナリファイルの場合はNoneを返す"""
try:
with open(os.path.join(self.repo_path, file_path), 'r', encoding='utf-8') as f:
return f.read()
except (UnicodeDecodeError, IOError):
return None
def collect(self) -> Iterable[Tuple]:
"""Git管理下のファイルとその内容を収集する(ignore_patternsに一致するファイルは除外)"""
tracked_files = [item[0] for item in self.repo.index.entries]
for file_path in tracked_files:
if not self._should_ignore(file_path):
content = self._read_file_content(file_path)
if content is not None:
yield file_path, content
def __del__(self):
"""デストラクタ: リモートの場合、一時ディレクトリを削除"""
if self.temp_dir and os.path.exists(self.temp_dir):
shutil.rmtree(self.temp_dir)
class DocumentFormatter:
def _normalize_source(self, source):
"""ソースコードの内容を正規化する"""
if isinstance(source, list):
# リストの場合は各要素を結合して1つの文字列にする
return ''.join(source)
return source
def _clean_notebook_content(self, content: str) -> str:
"""ipynbファイルから不要なメタデータを削除し、日本語を正規化する"""
try:
notebook = json.loads(content)
# セルの内容だけを抽出し、不要なメタデータを削除
cleaned_cells = []
for cell in notebook.get('cells', []):
# sourceの内容を正規化
source = self._normalize_source(cell.get('source', []))
cleaned_cell = {
'cell_type': cell.get('cell_type'),
'source': source # リストではなく文字列として保存
}
# outputsは実行結果なので削除(画像データなども含まれる)
if cell.get('cell_type') == 'code':
cleaned_cell['outputs'] = []
cleaned_cells.append(cleaned_cell)
# 最小限の情報だけを持つノートブックを作成
cleaned_notebook = {
'cells': cleaned_cells,
'nbformat': notebook.get('nbformat', 4),
'nbformat_minor': notebook.get('nbformat_minor', 0),
'metadata': {
'kernelspec': notebook.get('metadata', {}).get('kernelspec', {})
}
}
# ensure_ascii=Falseで日本語をそのまま出力
return json.dumps(cleaned_notebook, ensure_ascii=False, indent=2)
except json.JSONDecodeError:
return content
def format(self, filepath: str, content: str) -> dict:
"""検索用ドキュメントを作成する"""
ext = os.path.splitext(filepath)[1][1:] or 'no-extension'
# ipynbファイルの場合は内容をクリーニング
if ext == 'ipynb':
content = self._clean_notebook_content(content)
return {
'id': str(uuid.uuid4()),
'filepath': filepath,
'content': content,
'ext': ext
}
collector = GitCollector('https://github.com/riccox/meilisearch-ui', ignore_patterns=[
"*.min.css",
"*-min.css",
"*.sum",
"known_hosts",
"cdk.json"
])
formatter = DocumentFormatter()
uploader = MeilisearchUploader(
'http://meilisearch:7700', searchengine.MEILI_MASTER_KEY, 'fssearch-poc3')
create_indexer(collector, formatter, uploader).index()
- 500ファイル程度なら100ミリ秒で高速検索
- シンプルな構成で理解・カスタマイズが容易
- Meilisearchを使用した効率的な全文検索
※当方はdevcontainerなのでコンテナのアドレスがコンテナ名になってますが、普通にホストで実行する場合はlocalhost:7700に変更する必要あると思われる
Discussion