文字コードの基礎・種類
文字コードとは
文字コードとは、「文字」や「記号」をコンピューターで扱うために、文字に個別に割り当てた「固有の数値」を指します。
コンピューターは 0 と 1 の組み合わせでしか理解できないので、「あいうえお」という文字を表現したい場合はコンピューターが理解できるコードで処理する必要があるのです。
例えば「あ」という文字を表現したい場合、「10001」という番号が割り当てられていたら、最終的には 2 進数に変換されてコンピュータで処理されます。
このような「文字に数値を割り当てたもの」を文字コードと呼びます。
文字コードの種類
文字コードにはそれぞれ種類があり、日本語を表す文字コードは JIS 、 Shift_JIS 、 UTF-8 などがあります。
- ASCII ( アスキー )
- 米国規格協会 ( ANSI ) によって定められた、基本的な文字コード
- アルファベットと数字、あとはいくつかの記号のみで、1 文字を 7 ビットで表す
- ASCIIコード表
- EBCDIC(エビディック)
- IBM 社が定めた文字コードで、8 ビットを使って 1 文字を表す
- 大型の汎用コンピュータなどで使用される
- シフト JIS コード [S-JIS]( エスジス )
- ひらがなや漢字、カタカナなどが扱える日本語の文字コード
- ACSII のコード体系の文字と混合させて使用できるようになっている
- Windows でも使用されており、1 文字を 2 バイトで表す
- 文字コード表
- EUC ( イーユーシー )
- UNIX という OS 上でよく使用される日本語の文字コードで、拡張 UNIX コードとも呼ばれる
- 基本的には 1 文字を 2 バイトで表しますが、補助漢字などでは 3 バイト使用する
- Unicode ( ユニコード )
- 各国のありとあらゆる文字を 1 つのコード体系で表そうとした文字コード
- 当初は 1 文字を 2 バイトで表していたが、文字数が足りなくなり 3 バイト、4 バイトと拡張されている
- ISO/IEC 10646 として国際標準となっている
- IT用語辞典 e-Words | Unicodeとは - IT用語辞典
Unix 系 OS 上のシェルでできるバイナリ体験例
テスト用にファイルを作成。
$ echo "hoge" > test.txt
$ echo "fuga" >> test.txt
$ cat test.txt
hoge
fuga
$ od -c test.txt
0000000 h o g e \\n f u g a \\n
0000012
8 進数で表示。
$ od test.txt
0000000 067550 062547 063012 063565 005141
0000012
1 バイト単位の 16 進数で表示。
$ od -tx1 test.txt
0000000 68 6f 67 65 0a 66 75 67 61 0a
0000012
2 バイト単位の 16 進数で表示。
$ od -x test.txt
0000000 6f68 6567 660a 6775 0a61
0000012
1 バイト単位の 10 進数で出力。
$ od -tu1 test.txt
0000000 104 111 103 101 10 102 117 103 97 10
0000012
2 バイト単位の 10 進数で出力。
$ od -tu2 test.txt
0000000 28520 25959 26122 26485 2657
0000012
UTF-8 などを進数に変換
-
VSCode で 16 進数に変換
-
8〜16 進数を 2 進数(8、10 進数も可)に変換
- Mac : Command + Space =>「計算機」と検索 => 表示をクリック => プログラマに変更
追記(2021-05-17)
文字コードの種類として一括りで紹介しましたが、その中でも符号化文字集合と符号化方式に区分されるようです。
符号化文字集合とは、日本後のひらがなやカタカナ、英語やドイツ語などの文字をどのように表現して使えるかをリスト化したようなものです。
符号化方式とは、符号化文字集合を表現するために、実際にコンピュータが利用できるデータ列(バイト、ビット)に変換する方式です。
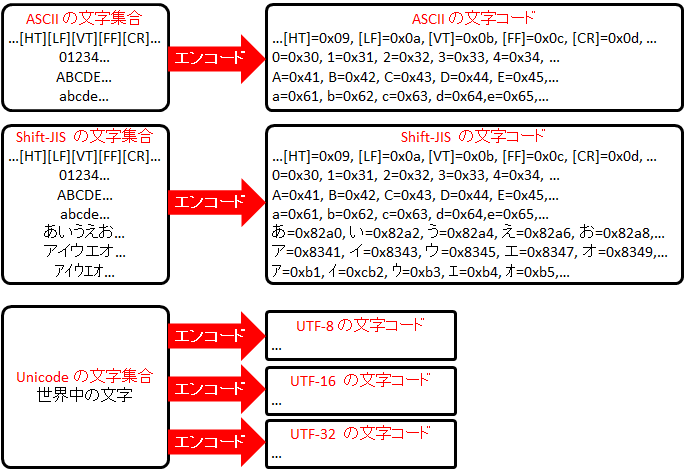
文字コード考え方から理解するUnicodeとUTF-8の違い | ギークを目指して より引用
Unicode は符号化文字集合で、 UTF-8 や UTF-16 は符号化方式となります。
ただし、サーバのパラメータ等では charset = UTF-8 と書かれたりするように、符号化文字集合 ( charset ) と符号化方式 ( character encoding ) を同じ意味で使うこともあります。
この 2 つの違いを理解しましょう。
参考
Discussion