NYC Taxi Dataでメダリオンアーキテクチャを実装する
概要
- NYC Taxi Dataを使用しMicrosoft Fabric上にメダリオンアーキテクチャを実装する。
- FabricのNotebook上から該当のデータをダウンロードして加工、可視化を行う。
- データ加工はData Factoryなどで行えますが、今回はなるべくコピペで実装できるようにnotebookでコードファーストで実装します。
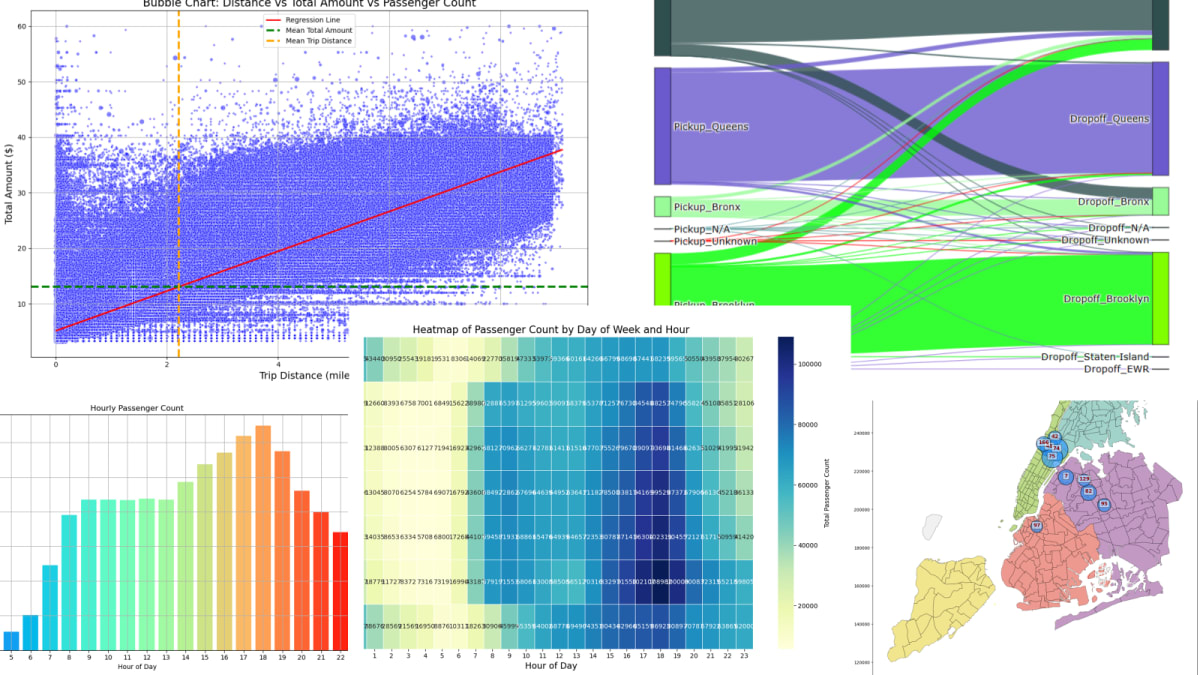
- 最終的に以下のような可視化を行います。
メダリオンアーキテクチャとは
- データ品質の向上:データを複数の層(ブロンズ、シルバー、ゴールド)に分けることで、データの品質と信頼性を段階的に向上させます。
- インサイトの迅速化:整備されたデータを利用することで、ビジネスユーザーやアナリストが迅速にインサイトを得られ、意思決定のスピードが向上します。
-
各レイヤーにおける役割まとめ
- ブロンズ層:データエンジニアが生データを収集し、保存。
- シルバー層:データエンジニアがデータのクレンジング、データアナリストがビジネスロジックの適用。
- ゴールド層:データアナリストが詳細な集約とロジックの適用を行い、ビジネスパワーユーザーがカスタムレポートやダッシュボードを作成。
- データガバナンスの強化:企業内で各役割がどのような作業をするのか以下に示します。このように分けることでデータガバナンスが強化され、コンプライアンスやセキュリティの管理が容易になります。
各レイヤーの役割と担当者
-
ブロンズ層 (Bronze Layer)
役割:生データ(Raw Data)の格納
担当者:データエンジニア
説明:- データエンジニアがデータソースから取得した生データをそのまま保存します。この層ではデータのクレンジングや変換は行わず、データの元の形式を保ちます。
-
シルバー層 (Silver Layer)
役割:クリーンデータ(Cleaned Data)の格納
担当者:データエンジニア、データアナリスト
説明:- データエンジニアがブロンズ層のデータをクレンジングし、ノイズを取り除き、必要なスキーマを適用します。
- データアナリストがクリーンデータをさらに分析し、ビジネスロジックを適用して、より詳細なクレンジングと変換を行います。
-
ゴールド層 (Gold Layer)
役割:ビジネス対応データ(Business-Ready Data)の格納と利用
担当者:データアナリスト、ビジネスパワーユーザー、ビジネスユーザー、データサイエンティスト
説明:- データアナリストが最終的なデータの集約とクレンジングを行い、ビジネスインテリジェンス(BI)ツールで使用可能な状態にします。
- ビジネスパワーユーザーがPower BIを使ってデータを分析、カスタムレポートやダッシュボードを作成します。高度な分析スキルを持ち、自分でデータを操作しながら、詳細なレポートを作成します。
- ビジネスユーザーはPower BIで提供されたレポートやダッシュボードを利用して、日常の業務や意思決定を行います。
※これが全てではありません。
使用するデータ
-
NYC Taxi Dataとは
- NYC taxi dataとは、ニューヨーク市タクシー&リムジン委員会 (TLC) が提供する、ニューヨーク市のタクシー運行情報を収集したデータセットで、乗車開始・終了地点、時間、料金などの詳細が含まれています。どのようなデータが含まれているかはnotebookを通じて見ていきます。
- 利用されている乗り物には、Yellow Taxi、Green Taxi、フォーハイヤー車両、リムジン、UberやLyftなどのライドシェア車両があります。今回はGreen Taxiのデータを使用します。

TLC Trip Records User Guideより引用
-
Green Taxiとは
- NYC といえばYellow Taxiが有名ですが、中心部から外れた場所はTaxiがほとんど運行しておらず、タクシーを利用したくても利用できない問題がありました。
- Green Taxiは、マンハッタンの中心部以外のエリア、特にブロンクス、ブルックリン、クイーンズ、スタテンアイランド、およびマンハッタンの96丁目以北でのタクシーサービスの需要を満たすために生まれました。
- 以下の図の緑の部分がGreen Taxiの運行範囲です。黄色はYellow Taxiの範囲です。
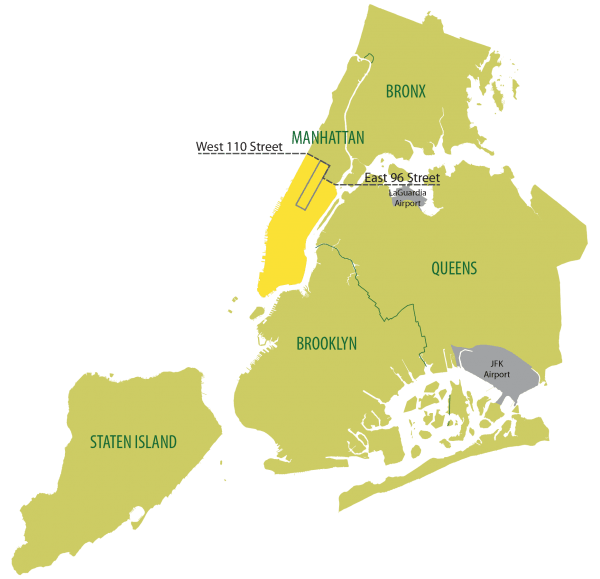
緑の範囲:TLC Trip Records User Guideより引用
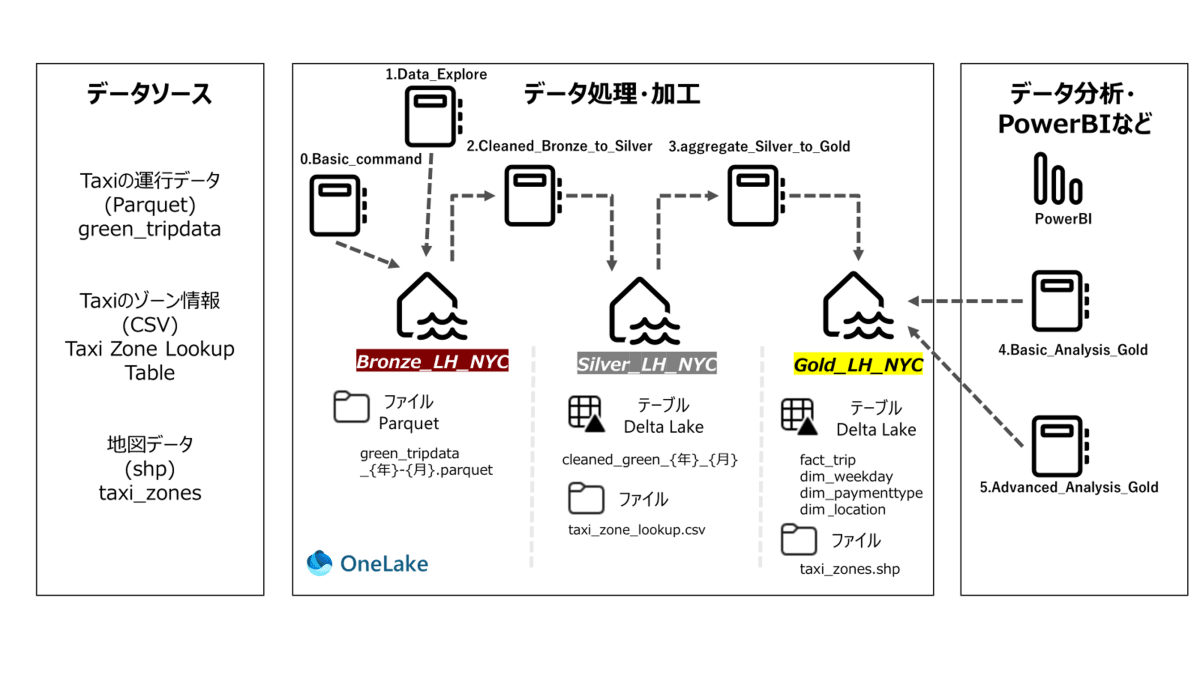
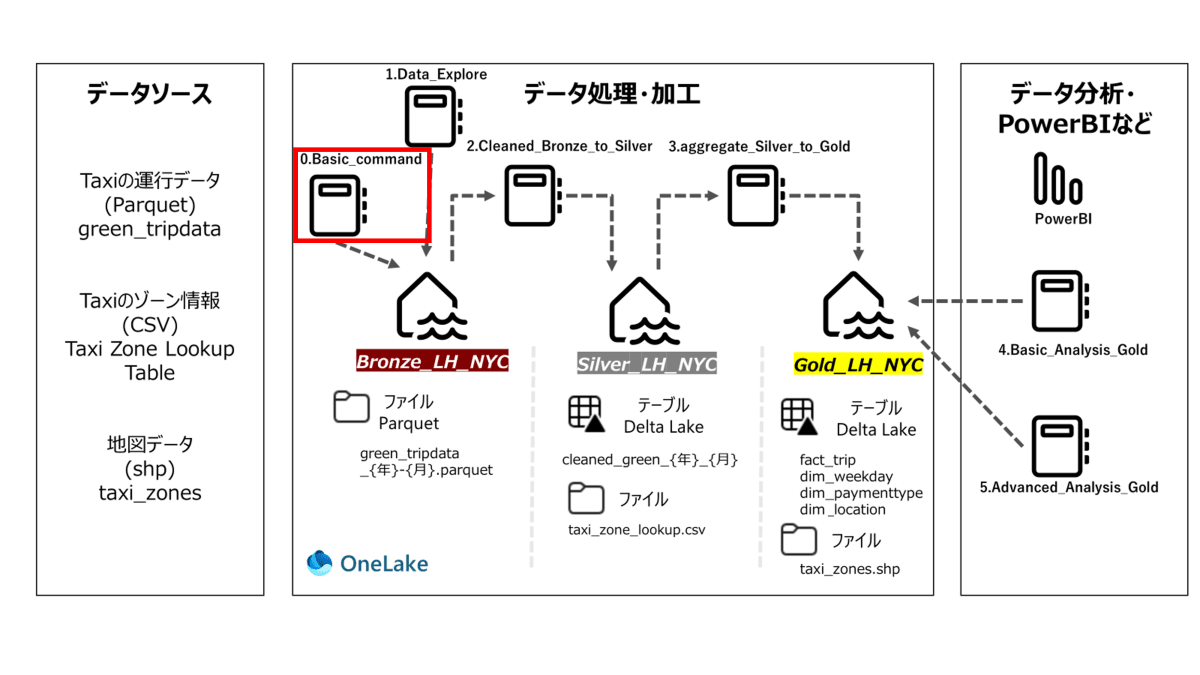
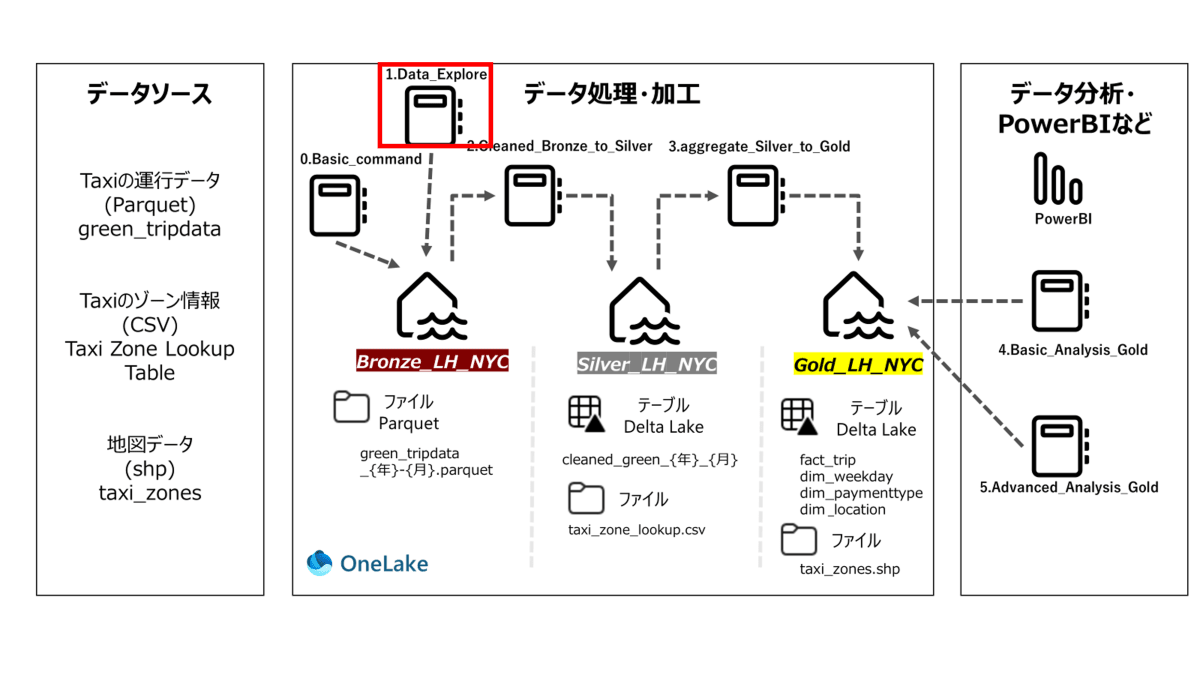
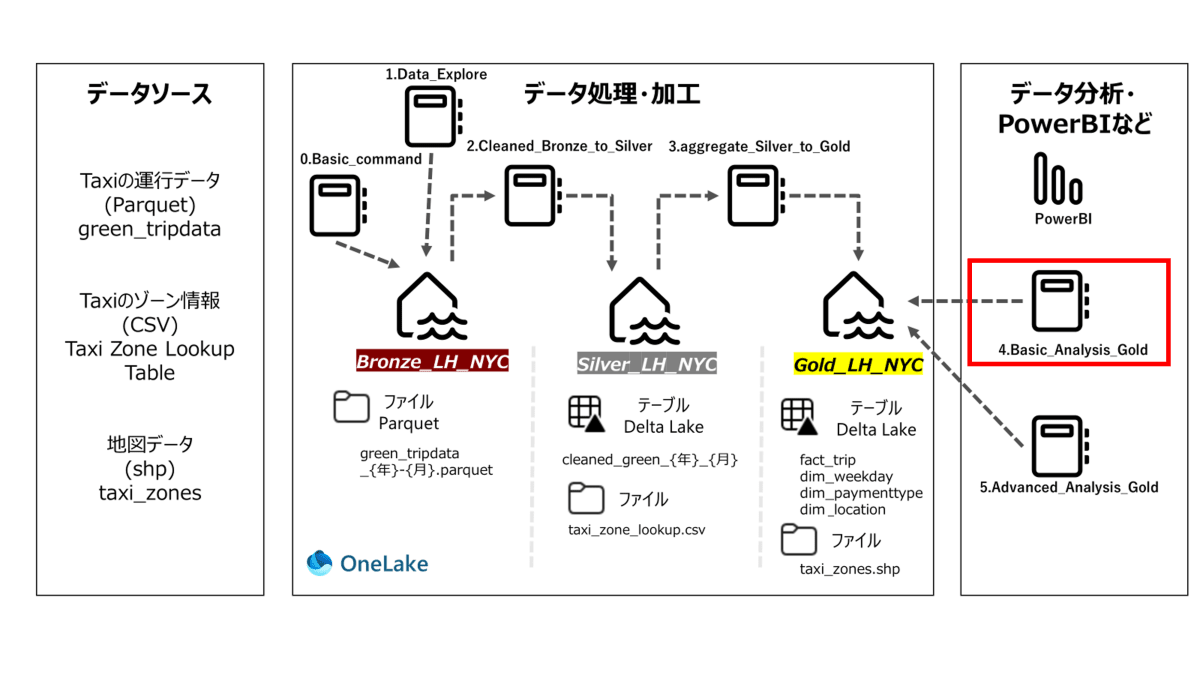
Green Taxi Dataでのメダリオンアーキテクチャ概要
- 以下はアーキテクチャ概要で、データソースやnotebook、テーブル名が記載されています。
- 各章の最初に使用するNotebookを赤枠で示します。
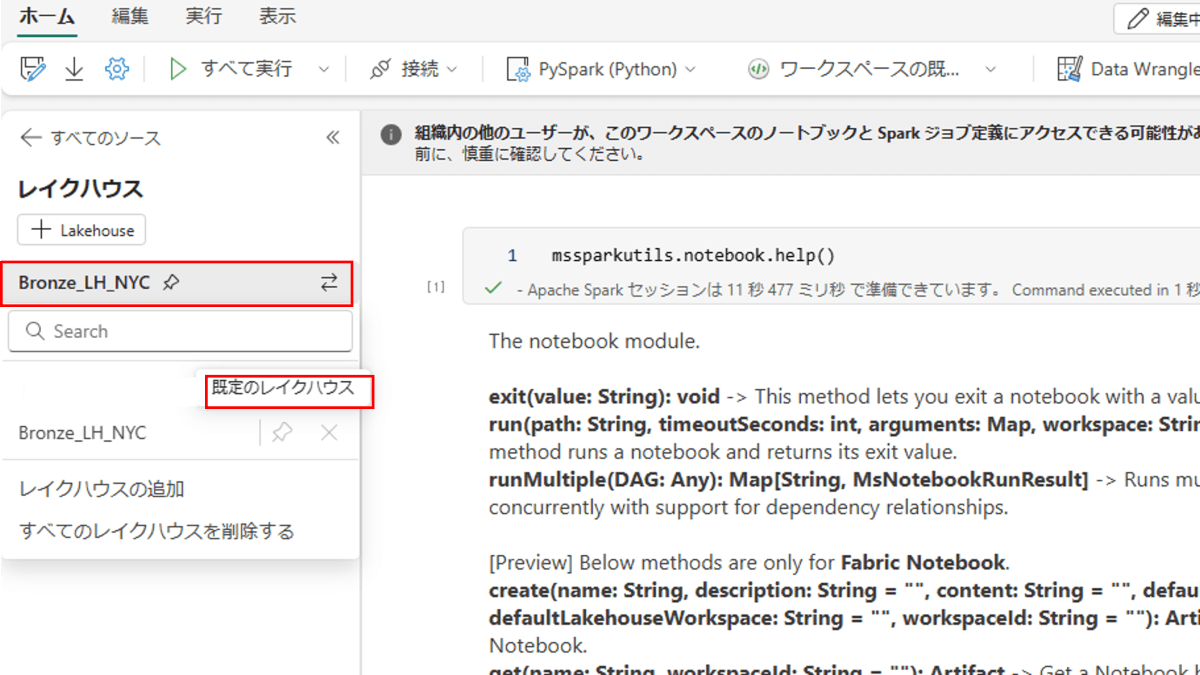
レイクハウスとnotebook
- Notebookは全部で0-5まで作成します。コードをコピーして実行ください。
- ワークスペースの系列ビューからNotebookがどこのレイクハウスに紐づいているかグラフィカルに表示できます。(既定のレイクハウス)
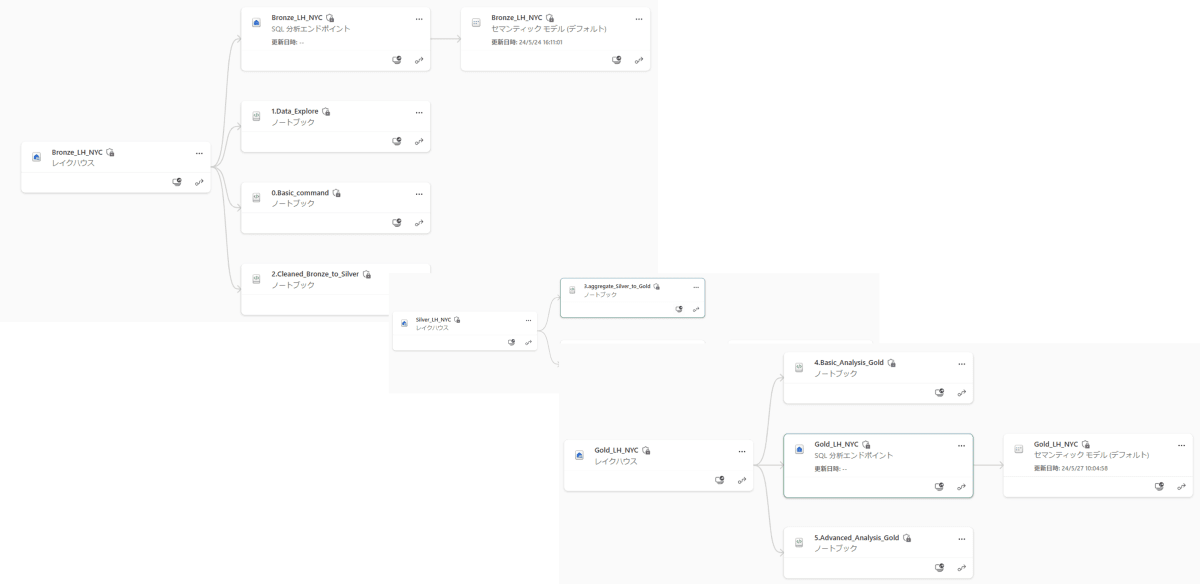
- こちらにマスターのnotebookを用意してますので、notebookをインポートして実行することも可能です。その場合既定のレイクハウスの設定に注意してください。
(補足)既定のレイクハウスとは?
-
Fabric上のnotebookは一つのレイクハウスを「既定のレイクハウス」として登録できます。
-
登録されたレイクハウスはマウントされ、ローカルのパス(/lakehouse/default/Files/など)を使用して読み書き可能になります。
-
これから実施するnotebookでは、既定のレイクハウスが設定されていないと動作しない箇所があるので注意してください。
-
章ごとにnotebookを作成し、どのレイクハウスを既定にするかを章の最初に記載しています。
0.基本コマンド
- Notebook名: 0.Basic_command
-
既定のレイクハウス: Bronze_LH_NYC
目的
- Notebook上からFabricのリソースを操作し、使用するファイルをWEBからダウンロード。
内容
-
もし環境がない場合は、無料試用版のサインアップから環境を準備してください。60日間無償で使用できます。
-
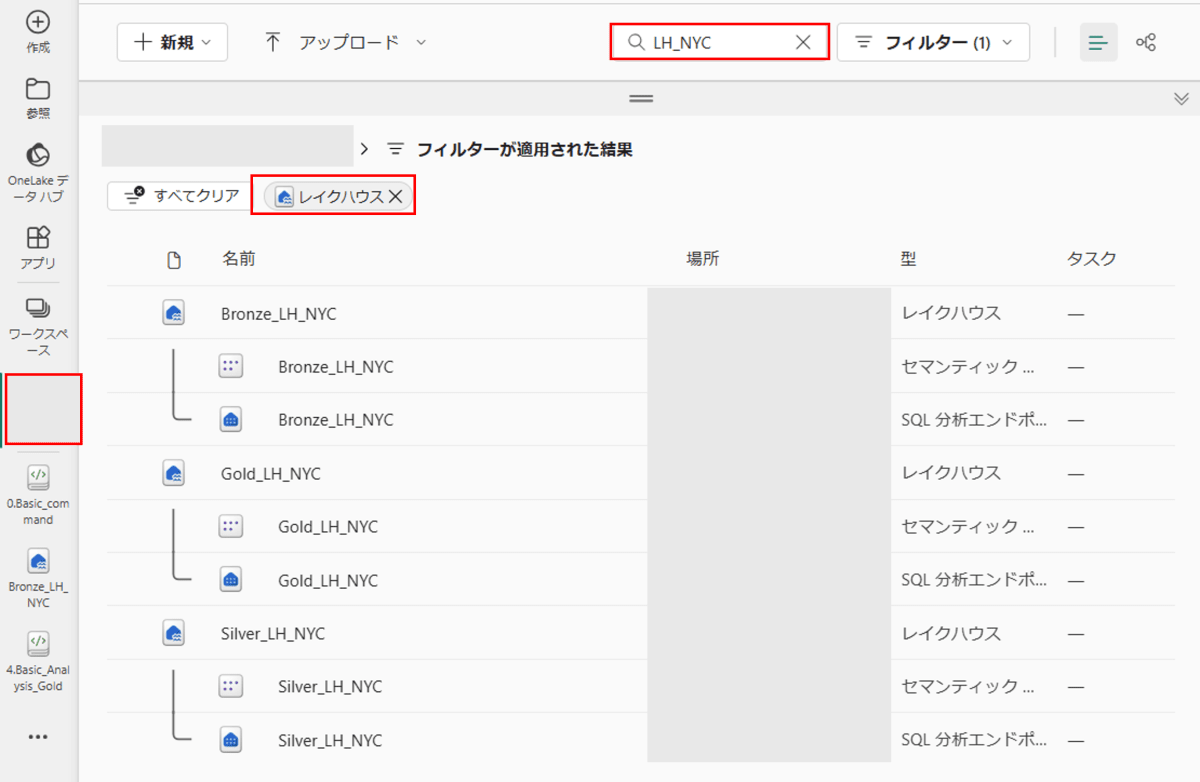
任意のワークスペースで空のレイクハウス[Bronze_LH_NYC]を作成
-
(補足)レイクハウス等の作成方法が不明な方はこちらを参考ください。
-
Bronze_LH_NYCのレイクハウスから[ノートブックを開く]>[新しいノートブック]を選択します。

-
notebookの名前を[0.Basic_command]に変更します。

- Microsoft Spark Utilities (MSSparkUtils)を使用して、レイクハウスのファイル システムなどを操作します。
- Notebook上から2019年から2021年までのNYC Taxi dataをダウンロードして該当のフォルダに格納します。
Notebook
基本コマンド
#mssparkutilsのヘルプ
mssparkutils.notebook.help()

#ディレクトリの作成
mssparkutils.fs.mkdirs('Files/map')
出力:
True
- Files以下にmapディレクトリが作成されていることを確認

#一覧取得、WorkspaceIDを調べる
mssparkutils.fs.ls("Files/")
出力:
[FileInfo(path=abfss://{WorkspaceID}@yyyy.dfs.fabric.microsoft.com/zzz/Files/map, name=map, size=0)]
- 出力にWorkspaceIDが表示されますのでメモしておきます。
#ディレクトリの削除
mssparkutils.fs.rm('Files/map')
出力:
True
- メモをしたWorkspaceIDを代入します。
#レイクハウス アーティファクトの一覧表示
mssparkutils.lakehouse.list("WorkspaceID")
出力:
{'id': 'xxxx',
'type': 'Lakehouse',
'displayName': 'Bronze_LH_NYC',
'description': '',
'workspaceId': 'xxxx',
'properties': {'abfsPath': 'abfss://xxxx@yyy.dfs.fabric.microsoft.com/zzz'}}]
使用するデータのダウンロード
#Webからダウンロードする方法を学びます。
#https://d37ci6vzurychx.cloudfront.net/trip-data/green_tripdata_2023-01.parquetをWebからダウンロードしてFiles/に保存する
#既定のレイクハウスがノートブックに自動的にマウントされます。 マウントポイントは "/lakehouse/default/"
import requests
url = "https://d37ci6vzurychx.cloudfront.net/trip-data/green_tripdata_2023-01.parquet"
response = requests.get(url)
with open('/lakehouse/default/Files/green_tripdata_2023-01.parquet', 'wb') as file:
file.write(response.content)
- 指定したURLはこちらで公開されている以下のファイルを指しています。
- 月間データはhttps://d37ci6vzurychx.cloudfront.net/trip-data/green_tripdata_{対象の年}-{対象の月}.parquetで公開されているようです。

- コマンド実行後、Files以下に該当のファイルがダウンロードされていることを確認します。

#Bronzeレイヤーの作成
mssparkutils.fs.mkdirs('Files/Bronze')
#過去に実施したファイルがある場合、以下でクリーンアップ
#初回の場合はスキップ可能
mssparkutils.fs.rm('Files/Bronze', True)
# 2019年から2021年までの各年と各月のフォルダを
# 'Files/Bronze' ディレクトリに作成する
years = [2019,2020,2021]
for year in years: # yearsリスト内の各年を順番に処理
for month in range(1, 13): # 各年の各月(1月から12月)を順番に処理
folder_path = f"Files/Bronze/{year}/{month}" # 年と月に基づいてフォルダパスを生成
mssparkutils.fs.mkdirs(folder_path) # 指定されたフォルダパスにフォルダを作成
# 2019年から2021年までの各年と各月のデータファイルをダウンロードし、
# 'Files/Bronze' ディレクトリに保存する
years = [2019, 2020, 2021]
for year in years: # yearsリスト内の各年を順番に処理
for month in range(1, 13): # 各年の各月(1月から12月)を順番に処理
month_str = f"{month:02d}" # 月を2桁の文字列にフォーマット
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/green_tripdata_{year}-{month_str}.parquet"
response = requests.get(url) # 指定されたURLからデータを取得
if response.status_code == 200: # データの取得が成功した場合
folder_path = f"/lakehouse/default/Files/Bronze/{year}/{month}" # 保存先のフォルダパスを生成
with open(folder_path + f"/green_tripdata_{year}-{month_str}.parquet", 'wb') as file:
file.write(response.content) # ダウンロードしたデータをファイルに書き込む
print(f"Downloaded and saved: {folder_path}") # 保存成功のメッセージを表示
else:
print(f"Failed to download: {url}") # ダウンロード失敗のメッセージを表示
出力:
Downloaded and saved: /lakehouse/default/Files/Bronze/2019/1
↓
Downloaded and saved: /lakehouse/default/Files/Bronze/2021/12まで

# ファイルがあることをlsコマンドで確認
mssparkutils.fs.ls("Files/Bronze/2019/1")
[FileInfo(path=abfss://xxx@yyy.dfs.fabric.microsoft.com/zzz/Files/Bronze/2019/01/green_tripdata_2019-01.parquet, name=green_tripdata_2019-01.parquet, size=11071980)]
- 先ほどメモしたWorkspaceIDを以下のWorkspaceIDに代入します。
# 'Silver_LH_NYC' という名前のLakehouseを作成
mssparkutils.lakehouse.create("Silver_LH_NYC","","WorkspaceID")
{'id': 'xxx',
'type': 'Lakehouse',
'displayName': 'Silver_LH_NYC',
'description': '',
'workspaceId': 'xxx',
'properties': {'abfsPath': 'abfss://xxx@yyy.dfs.fabric.microsoft.com/zzz'}}
- 同様にメモしたWorkspaceIDを以下のWorkspaceIDに代入します。
# 'Gold_LH_NYC' という名前のLakehouseを作成
mssparkutils.lakehouse.create("Gold_LH_NYC","","WorkspaceID")
{'id': 'xxx',
'type': 'Lakehouse',
'displayName': 'Gold_LH_NYC',
'description': '',
'workspaceId': 'xxx',
'properties': {'abfsPath': 'abfss://xxx@yyy.dfs.fabric.microsoft.com/zzz'}}
- Workspaceの全体からSilver_LH_NYCとGold_LH_NYCのレイクハウスが作成されていることがわかります。
まとめとTips
- コマンドを使用してレイクハウスを操作
- Files/Bronze以下に必要なファイルをダウンロード
- Silver_LH_NYCとGold_LH_NYCのレイクハウスを作成
1.データ探索の基礎
- Notebook名: 1.Data_Explore
- 既定のレイクハウス: Bronze_LH_NYC
目的
- ダウンロードしたTaxiデータを探索し、加工してクリーニングするための基礎を学ぶ
内容
- ParquetファイルからSpark DataFrameへデータのロード
- データの概要確認
- データのクリーニング
- 分析に不要な列の削除
- Null値の削除→すべての列
-
データ範囲の適正化
- lpep_pickup_datetime/lpep_dropoff_datetimeに該当期間ではないデータが入っていることがあるので適正な期間に修正
- PULocationID/DOLocationID→1-265の範囲に限定
- payment_type→1-5に限定
- trip_distance/total_amount→0以上
- 0は何らかの理由で予約がキャンセルされた可能性があることを意味します。
- passenger_count→1-6人に限定、0は乗客がいなかったり、6人以上の乗客はミスの可能性が高いです。
-
外れ値を削除
- trip_durationに対しzスコアを計算しクリーニング
- trip_distanceに対しIQR法でクリーニング
- total_amountに対しtrimmingでクリーニング
Notebook
1-1. ParquetファイルからSpark DataFrameへデータのロード
from pyspark.sql.functions import col, expr, sum, month, count, year, dayofmonth, hour, minute, dayofweek, unix_timestamp, avg, stddev
# Sparkを使用して、指定されたParquetファイルを読み込みます。この操作により、dfというSpark DataFrameが作成されます。
df = spark.read.parquet("Files/Bronze/2019/1/green_tripdata_2019-01.parquet")
display(df)
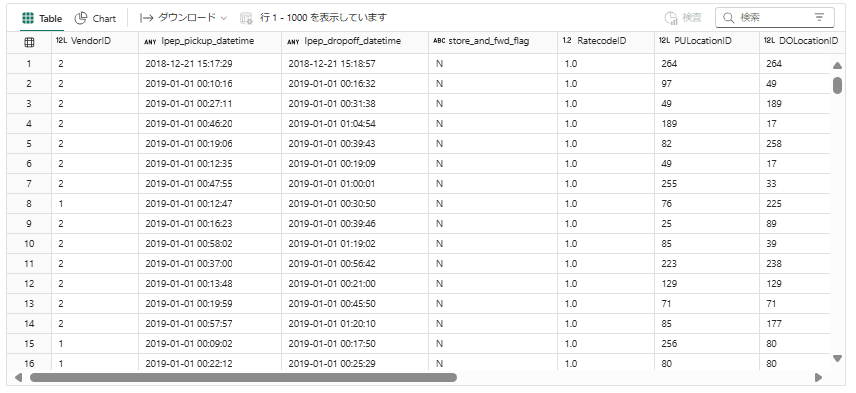
1-2. Dataの概要確認
#データフレームのスキーマを表示します。
df.printSchema()
root
|-- VendorID: long (nullable = true)
|-- lpep_pickup_datetime: timestamp_ntz (nullable = true)
|-- lpep_dropoff_datetime: timestamp_ntz (nullable = true)
|-- store_and_fwd_flag: string (nullable = true)
|-- RatecodeID: double (nullable = true)
|-- PULocationID: long (nullable = true)
|-- DOLocationID: long (nullable = true)
|-- passenger_count: double (nullable = true)
|-- trip_distance: double (nullable = true)
|-- fare_amount: double (nullable = true)
|-- extra: double (nullable = true)
|-- mta_tax: double (nullable = true)
|-- tip_amount: double (nullable = true)
|-- tolls_amount: double (nullable = true)
|-- ehail_fee: double (nullable = true)
|-- improvement_surcharge: double (nullable = true)
|-- total_amount: double (nullable = true)
|-- payment_type: double (nullable = true)
|-- trip_type: double (nullable = true)
|-- congestion_surcharge: double (nullable = true)
- 以下日本語に直したカタログです。重要な項目は太字にしています。
| フィールド名 | 説明 |
|---|---|
| VendorID | レコードを提供したLPEPプロバイダーを示すコード。1= Creative Mobile Technologies, LLC; 2= VeriFone Inc. |
| lpep_pickup_datetime | メーターが開始された日時。 |
| lpep_dropoff_datetime | メーターが終了された日時。 |
| Passenger_count | 車両内の乗客の数。ドライバーが入力する値です。 |
| Trip_distance | タクシーメーターによって報告された経過したトリップ距離(マイル)。 |
| PULocationID | メーターが開始されたTLCタクシーゾーン。 |
| DOLocationID | メーターが終了されたTLCタクシーゾーン。 |
| RateCodeID | トリップ終了時に適用される最終的な料金コード。1= 標準料金、2= JFK、3= Newark、4= NassauまたはWestchester、5= 交渉料金、6= グループ乗車 |
| Store_and_fwd_flag | データがリアルタイムで送信されたかのフラグ、このフラグは、車両がサーバーに接続されていないため、レコードが車両のメモリに保持されたかどうかを示します。Y= 保持して転送されたトリップ、N= 保持されていないトリップ |
| Payment_type | 乗客がトリップを支払った方法を示す数値コード。1= クレジットカード、2= 現金、3= 無料、4= 紛争、5= 不明、6= 無効トリップ |
| Fare_amount | メーターによって計算された時間と距離に基づく料金。 |
| Extra | その他の追加料金とサーチャージ。現在、$0.50と$1のラッシュアワーおよび深夜料金のみが含まれます。 |
| MTA_tax | メーターレートに基づいて自動的に発生する$0.50のMTA税。 |
| Improvement_surcharge | 乗車時に課される$0.30の改善サーチャージ。この改善サーチャージは2015年から課されています。 |
| Tip_amount | チップの金額 - クレジットカードのチップには自動的に値が入りますが、現金のチップは含まれません。 |
| Tolls_amount | トリップで支払われたすべての通行料の合計。 |
| Total_amount | 乗客に請求された合計金額。現金のチップは含まれません。 |
| Trip_type | 乗車が乗客の呼び止めと配車のどちらであるかを示すコード。配車は、使用中のメーター料金に基づいて自動的に割り当てられますが、運転手が変更できます。 1= Streetで拾う 2= 配車 |
| Congestion Surcharge | 渋滞料金 |
- データカタログの参考URL
#レコード数の確認
record_count = df.count()
print(f"Total number of records: {record_count}")
出力:
Total number of records: 672105
# 各列の基本統計情報を表示。
display(df.describe())
# count: 各列に含まれる非NULLエントリの数。
# mean: 各列の平均値。
# stddev: 各列の標準偏差。
# min: 各列の最小値。
# max: 各列の最大値。

1-3. Dataのクリーニング
#データフレームから分析に不要な列を取り除き、データ量を減らします。
df_drop = df.drop("VendorID","store_and_fwd_flag","RateCodeID","extra", "mta_tax", "tolls_amount", "ehail_fee","improvement_surcharge","fare_amount","tip_amount","Trip_type","congestion_surcharge")
#データの確認。列が削除されていることを確認します。
display(df_drop)

#レコード数の確認
record_count = df_drop.count()
print(f"Total number of records: {record_count}")
出力:
Total number of records: 672105
Null値を削除
# dropnaメソッドを使用して、df_dropデータフレームからNULL値(欠損値)が含まれている行を削除します。
df_drop_na = df_drop.dropna()
#レコード数の確認
record_count = df_drop_na.count()
print(f"Total number of records: {record_count}")
Total number of records: 630526
# 欠損値の数をカウント
# 各列の欠損値(NULL値)の数をカウント
null_counts = df_drop_na.select([sum(col(c).isNull().cast("int")).alias(c) for c in df_drop_na.columns])
# df_drop_na.columnsでデータフレームのすべての列名を取得します。
# リスト内包表記を使用して、各列に対して以下の処理を行います:
# 1. col(c).isNull()で、列cの値がNULLであるかどうかをチェックします。
# 2. .cast("int")で、ブール値を整数にキャストします(NULLであれば1、そうでなければ0)。
# 3. sum()で、列内のすべてのNULL値の合計を計算します。
# 4. alias(c)で、結果の列名を元の列名に設定します。
# 欠損値の数を表示
display(null_counts)
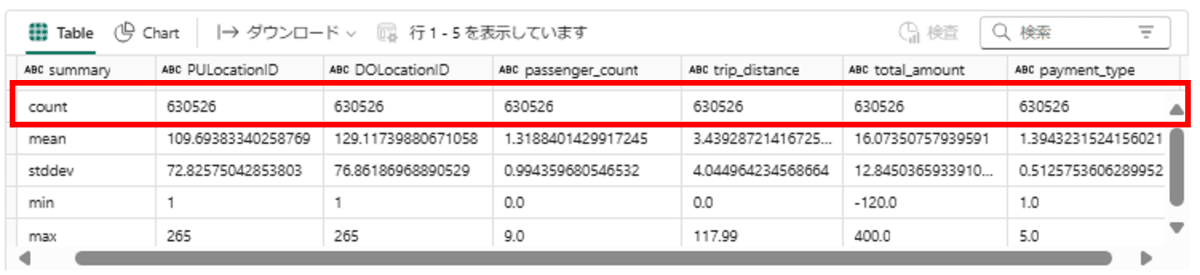
- すべて0でNull値がないことを確認

# df_drop_naの基本統計情報を表示
# count数がすべて同じであることがわかります。
display(df_drop_na.describe())
データ範囲の適正化
該当の期間にデータをフィルター
#lpep_pickup_datetime/lpep_dropoff_datetimeに該当期間ではないデータが入っていることがあるので適正な期間に修正
#例えば、2019年1月のデータに2019年2月の期間のデータが入っていることもあります。
df_filtered = df_drop_na
# 月ごとの分布を計算
# df_filteredデータフレームを以下のキーでグループ化します:
# 1. lpep_pickup_datetime列の月を抽出して"pickup_month"としてエイリアスを設定
# 2. lpep_dropoff_datetime列の月を抽出して"dropoff_month"としてエイリアスを設定
month_distribution = df_filtered.groupBy(
month(col("lpep_pickup_datetime")).alias("pickup_month"),
month(col("lpep_dropoff_datetime")).alias("dropoff_month")
).agg(
# 各グループの行数をカウントし、その結果に"count"としてエイリアスを設定
count("*").alias("count")
)
#display関数を使用して、計算されたmonth_distributionデータフレームを表示します。これにより、各ピックアップ月とドロップオフ月の組み合わせごとのレコード数を視覚的に確認できます。どちらも1月のものが該当のものです。
display(month_distribution)
- 1月(赤枠)のデータが一番多いですが、1月以外のデータが含まれていることがわかります。
- 1月のデータのみに適正化していきます。

#filterメソッドを使用して、df_filteredデータフレームから特定の条件を満たす行をフィルタリングします。
#lpep_pickup_datetime列の月が1月であること。lpep_dropoff_datetime列の月が1月であること
df_filtered_month = df_filtered.filter((month(col("lpep_pickup_datetime")) == 1) & (month(col("lpep_dropoff_datetime")) == 1))
# 1月のデータで月ごとの分布を計算
month_distribution = df_filtered_month.groupBy(
# lpep_pickup_datetime列の月を抽出して"pickup_month"としてエイリアスを設定
month(col("lpep_pickup_datetime")).alias("pickup_month"),
# lpep_dropoff_datetime列の月を抽出して"dropoff_month"としてエイリアスを設定
month(col("lpep_dropoff_datetime")).alias("dropoff_month")
).agg(
# 各グループの行数をカウントし、その結果に"count"としてエイリアスを設定
count("*").alias("count")
)
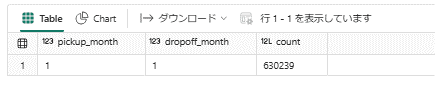
#display関数を使用して、計算されたmonth_distributionデータフレームを表示します。これにより、各ピックアップ月とドロップオフ月の組み合わせごとのレコード数を視覚的に確認できます。どちらも1月のものが該当のものです。
display(month_distribution)
- 1月のデータのみになっています
#レコード数の確認
record_count = df_filtered_month.count()
print(f"Total number of records: {record_count}")
出力:
Total number of records: 630239
datetimeを年、月、日、時間、分、曜日に分ける
# lpep_pickup_datetimeを年、月、日、時間、分、曜日に分ける
# dayofweek関数は曜日を1(=日曜日)から7(=土曜日)で返します。
df_filtered_month = df_filtered_month.withColumn("pickup_year", year(col("lpep_pickup_datetime"))) \
.withColumn("pickup_month", month(col("lpep_pickup_datetime"))) \
.withColumn("pickup_day", dayofmonth(col("lpep_pickup_datetime"))) \
.withColumn("pickup_hour", hour(col("lpep_pickup_datetime"))) \
.withColumn("pickup_minute", minute(col("lpep_pickup_datetime"))) \
.withColumn("pickup_weekday", dayofweek(col("lpep_pickup_datetime")))
# lpep_dropoff_datetimeとの差分を計算し、trip_durationとして追加
df_filtered_month = df_filtered_month.withColumn("trip_duration",
(unix_timestamp(col("lpep_dropoff_datetime")) - unix_timestamp(col("lpep_pickup_datetime"))) / 60)
# lpep_pickup_datetimeとlpep_dropoff_datetimeを削除
df_filtered_month = df_filtered_month.drop("lpep_dropoff_datetime")
#レコード数の確認
record_count = df_filtered_month.count()
print(f"Total number of records: {record_count}")
出力: 前回のレコード数と変化ありません。
Total number of records: 630239
display(df_filtered_month.describe())
df_filtered_month.printSchema()
root
|-- lpep_pickup_datetime: timestamp_ntz (nullable = true)
|-- PULocationID: long (nullable = true)
|-- DOLocationID: long (nullable = true)
|-- passenger_count: double (nullable = true)
|-- trip_distance: double (nullable = true)
|-- total_amount: double (nullable = true)
|-- payment_type: double (nullable = true)
|-- pickup_year: integer (nullable = true)
|-- pickup_month: integer (nullable = true)
|-- pickup_day: integer (nullable = true)
|-- pickup_hour: integer (nullable = true)
|-- pickup_minute: integer (nullable = true)
|-- pickup_weekday: integer (nullable = true)
|-- trip_duration: double (nullable = true)
その他データのフィルター
- データ型と列名の変換
- PULocationID/DOLocationID→1-265の範囲に限定
- payment_type→1-5に限定
- trip_distance/total_amount→0以上、0は何らかの理由で予約がキャンセルされた可能性があることを意味します。
- passenger_count→1-6人に限定、0は乗客がいなかったり、6人以上の乗客はミスの可能性が高いです
# フィルタリングされた1月のデータの型、列名の変換
df_filtered_month = df_filtered_month.selectExpr(
"cast(lpep_pickup_datetime as timestamp) as pickup_datetime", # lpep_pickup_datetime列をtimestamp型に変換
"cast(PULocationID as int) as pickup_LocationID",
"cast(DOLocationID as int) as dropoff_LocationID",
"cast(payment_type as int) as payment_type",
"cast(passenger_count as int) as passenger_count",
"cast(trip_distance as double) as trip_distance",
"cast(total_amount as double) as total_amount",
"cast(pickup_year as int) as pickup_year",
"cast(pickup_month as int) as pickup_month",
"cast(pickup_day as int) as pickup_day",
"cast(pickup_hour as int) as pickup_hour",
"cast(pickup_minute as int) as pickup_minute",
"cast(pickup_weekday as int) as pickup_weekday",
"cast(trip_duration as double) as trip_duration"
)
# データの値を制限
df_filtered_numbers = df_filtered_month.filter(
(col("pickup_LocationID").between(1, 265)) &
(col("dropoff_LocationID").between(1, 265)) &
(col("payment_type").between(1, 5)) &
(col("passenger_count").between(1, 6)) &
(col("trip_distance") > 0) &
(col("total_amount") > 0) &
(col("pickup_year").between(2019, 2021)) & # pickup_yearに対するフィルタリング条件
(col("pickup_month").between(1, 12)) & # pickup_monthに対するフィルタリング条件
(col("pickup_day").between(1, 31)) & # pickup_dayに対するフィルタリング条件
(col("pickup_hour").between(0, 23)) & # pickup_hourに対するフィルタリング条件
(col("pickup_minute").between(0, 59)) & # pickup_minuteに対するフィルタリング条件
(col("trip_duration") > 0) # trip_durationに対するフィルタリング条件
)
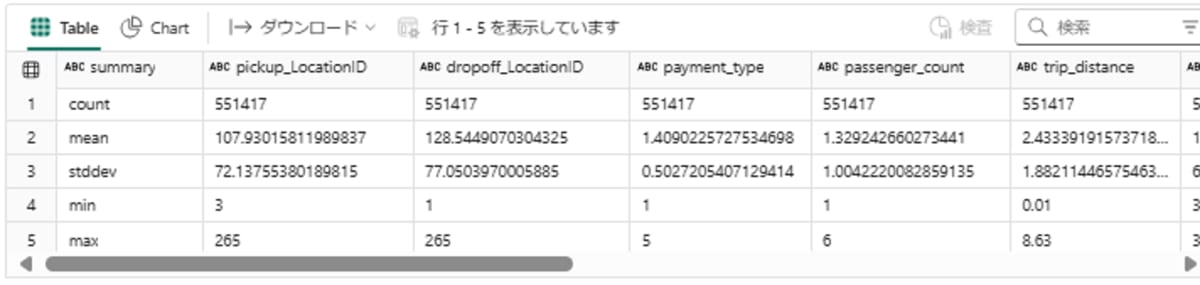
# df_filtered_numbersの基本統計情報を表示。trip_distance, total_amount, trip_durationマイナスが無いことを確認
display(df_filtered_numbers.describe())
df_filtered_numbers.printSchema()
root
|-- pickup_datetime: timestamp (nullable = true)
|-- pickup_LocationID: integer (nullable = true)
|-- dropoff_LocationID: integer (nullable = true)
|-- payment_type: integer (nullable = true)
|-- passenger_count: integer (nullable = true)
|-- trip_distance: double (nullable = true)
|-- total_amount: double (nullable = true)
|-- pickup_year: integer (nullable = true)
|-- pickup_month: integer (nullable = true)
|-- pickup_day: integer (nullable = true)
|-- pickup_hour: integer (nullable = true)
|-- pickup_minute: integer (nullable = true)
|-- pickup_weekday: integer (nullable = true)
|-- trip_duration: double (nullable = true)
- データ型が変更されていることを確認します。
#レコード数の確認
record_count = df_filtered_numbers.count()
print(f"Total number of records: {record_count}")
出力:
Total number of records: 612544
# passenger_countごとにグループ化し、その出現回数をカウント
value_counts_df = df_filtered_numbers.groupBy("passenger_count").count().orderBy(col("passenger_count").asc())
display(value_counts_df)

外れ値を削除
- 外れ値を削除する方法にはいくつかのアプローチがありますが今回はZスコア、IQR法、トリミングを使用して外れ値を削除していきます。
- 目的に合わせて適切なクリーニングの方法を選択してください。
trip_durationのZスコアとは
-
Zスコアとは
- Zスコア(標準得点)は、データポイントが平均からどれだけの標準偏差離れているかを示します。
- Zスコアが2の場合:データポイントは平均から上位または下位2.5%に位置します(全データの95%がこの範囲内に収まり、5%のデータを除外します)
- Zスコアが3の場合:データポイントは平均から上位または下位0.15%に位置します(全データの99.7%がこの範囲内に収まります)
- 今回はZスコアを2として計算します。
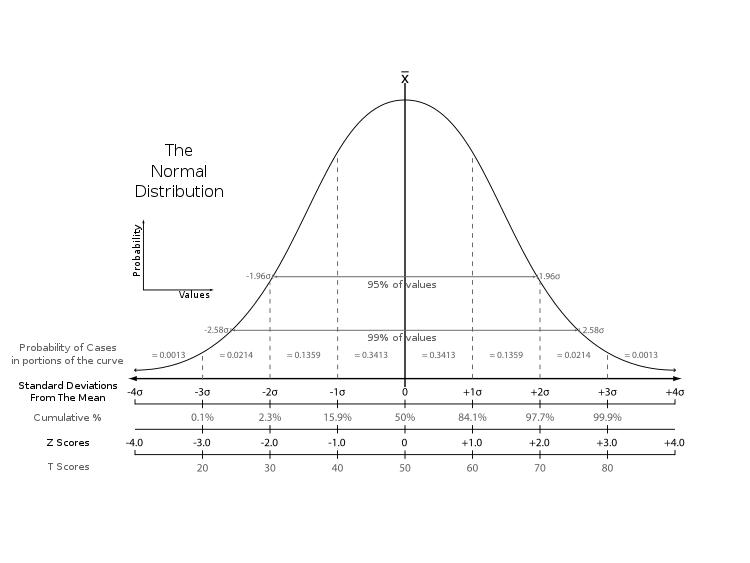
wikipedia:標準得点より
## zscoreを計算
# 平均と標準偏差の計算
stats = df_filtered_numbers.select(avg(col('trip_duration')).alias('mean'), stddev(col('trip_duration')).alias('stddev')).collect()
mean_trip_duration = stats[0]['mean']
stddev_trip_duration = stats[0]['stddev']
# 異常値の除去(Zスコアがまたは-2を超える値を除去)
df_filtered_numbers = df_filtered_numbers.filter((col('trip_duration') - mean_trip_duration) / stddev_trip_duration <= 2) \
.filter((col('trip_duration') - mean_trip_duration) / stddev_trip_duration >= -2)
trip_distanceに対しIQR法でクリーニング
- IQR法は、データセットの外れ値を検出するための方法です。四分位範囲(IQR)を使い、第1四分位数(Q1)と第3四分位数(Q3)を基に外れ値の範囲を決定します。
- これにより、極端に小さいまたは大きい値を特定して取り除くことができます。
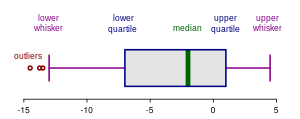
wikipedia:箱ひげ図
# IQRを計算して外れ値の範囲を決定
# trip_distance列の第1四分位数(Q1)と第3四分位数(Q3)を近似的に計算
quantiles = df_filtered_numbers.approxQuantile("trip_distance", [0.25, 0.75], 0.01)
Q1, Q3 = quantiles[0], quantiles[1]
# 四分位範囲(IQR)を計算
IQR = Q3 - Q1
# 外れ値を検出するための下限と上限を計算
# 外れ値を検出するための下限 (lower_bound) を Q1 - 1.5 * IQR で計算します。
lower_bound = Q1 - 1.5 * IQR
# 外れ値を検出するための上限 (upper_bound) を Q3 + 1.5 * IQR で計算します。
upper_bound = Q3 + 1.5 * IQR
# 外れ値をフィルタリング
# trip_distance列の値が下限以上かつ上限以下の行をフィルタリング
df_iqr= df_filtered_numbers.filter(
(col("trip_distance") >= lower_bound) &
(col("trip_distance") <= upper_bound)
)
total_amountに対しTrimmingでクリーニング
- データセットから極端な値を完全に除去して、分析結果の信頼性を向上させる
- 今回は上下0.5%の極端なデータを削除
df_trimming = df_iqr
# total_amount列上位0.5%と下位0.5%の境界値を計算
bounds = df_trimming.approxQuantile("total_amount", [0.005, 0.995], 0.0)
# 境界値を取得
lower_bound = bounds[0] # 下位0.5%の境界値
upper_bound = bounds[1] # 上位0.5%の境界値
# 境界値を超える外れ値をフィルタリング
df_trimming = df_trimming.filter((col("total_amount") >= lower_bound) & (col("total_amount") <= upper_bound))
# 境界値を表示
print(f"Lower bound: {lower_bound}, Upper bound: {upper_bound}")
Lower bound: 3.8, Upper bound: 37.88
display(df_trimming.describe())
#レコード数の確認
record_count = df_trimming.count()
print(f"Total number of records: {record_count}")
Total number of records: 551417
- 最終的なデータカタログ
| フィールド名 | 説明 |
|---|---|
| lpep_pickup_datetime | メーターが開始された日時。 |
| Passenger_count | 車両内の乗客の数。ドライバーが入力する値です |
| Trip_distance | タクシーメーターによって報告された経過したトリップ距離(マイル) |
| PULocationID | メーターが開始されたTLCタクシーゾーン |
| DOLocationID | メーターが終了されたTLCタクシーゾーン |
| Payment_type | 乗客がトリップを支払った方法を示す数値コード。1= クレジットカード、2= 現金、3= 無料、4= 紛争、5= 不明、6= 無効トリップ |
| Total_amount | 乗客に請求された合計金額。現金のチップは含まれません |
| pickup_year | ピックアップした年 |
| pickup_month | ピックアップした月 |
| pickup_day | ピックアップした日 |
| pickup_hour | ピックアップした時間(時) |
| pickup_minute | ピックアップした時間(分) |
| pickup_weekday | ピックアップした曜日(1: 日曜日, 2: 月曜日, …, 7: 土曜日) |
| trip_duration | 乗車時間(単位:分) |
まとめとTips
- 2019年1月のデータを例にデータをクリーニングする方法を学びました
- 不要な列の削除、NULL値の削除、データを適切な範囲に限定、データタイプの変更を行いました。
- ZスコアやIQR法などを用いて各列の外れ値の削除などを実施しデータをクリーニングを実施しました。
- pandasだと容易にZスコアなど計算できますが、今回sparkデータフレームなので一からロジック記載してます。
- copilotにお願いすると様々なロジックを記載してくれます。
2.データのクレンジング BronzeからSilverへデータの加工
- Notebook名: 2.Cleaned_Bronze_to_Silver
- 既定のレイクハウス: Bronze_LH_NYC

目的
- Bronzeレイヤー に保存されているrawデータを加工し、 Silverレイヤー に Cleanデータ として保存
内容
- UDF(ユーザー定義関数)の作成
- RawデータをUDFを使用して加工、SilverレイヤーにDelta tableとして保存
- 保存されたDelta Tableが適切に処理されているかをチェック
Notebook
UDF(ユーザー定義関数)の作成
from pyspark.sql.functions import col, expr, sum, month, count, year, dayofmonth, hour, minute, dayofweek, unix_timestamp, avg, stddev
import pyspark.sql.functions as F
# ファイルパスのリスト作成
try:
file_paths = []
# 2019年から2021年までの各年についてループ
for year in range(2019, 2022):
# 各年の1月から12月までについてループ
for month_val in range(1, 13):
# ファイルパスをリストに追加
file_paths.append((year, month_val, f"Files/Bronze/{year}/{month_val}/green_tripdata_{year}-{month_val:02d}.parquet"))
print("File paths created successfully.")
except Exception as e:
# エラー発生時にエラーメッセージを表示
print(f"Error creating file paths: {e}")
# ファイルパスのリストを表示
file_paths
出力:
File paths created successfully.
[(2019, 1, 'Files/Bronze/2019/1/green_tripdata_2019-01.parquet'),
↓
(2021, 12, 'Files/Bronze/2021/12/green_tripdata_2021-12.parquet')]まで
### ユーザー定義関数
def process_dataframe(df, filter_month):
try:
# 削除する不要な列のリストを定義
columns_to_drop = ["VendorID", "store_and_fwd_flag", "RateCodeID", "extra", "mta_tax", "tolls_amount",
"ehail_fee", "improvement_surcharge", "fare_amount", "tip_amount", "Trip_type",
"congestion_surcharge"]
# 不要な列を削除し、欠損値がある行を削除
df = df.drop(*columns_to_drop).dropna()
# 必要な列を選択し、型を変換してリネーム
df = df.select(
col("lpep_pickup_datetime").cast("timestamp").alias("pickup_datetime"),
col("lpep_dropoff_datetime").cast("timestamp").alias("dropoff_datetime"),
col("PULocationID").cast("int").alias("pickup_LocationID"),
col("DOLocationID").cast("int").alias("dropoff_LocationID"),
col("payment_type").cast("int").alias("payment_type"),
col("passenger_count").cast("int").alias("passenger_count"),
col("trip_distance").cast("double").alias("trip_distance"),
col("total_amount").cast("double").alias("total_amount")
)
# 指定された月でフィルタリング(pickupとdropoffの両方が同じ月)
df = df.filter((F.month(col("pickup_datetime")) == filter_month) & (F.month(col("dropoff_datetime")) == filter_month))
# pickup_datetimeに基づいて新しい列を追加(年、月、日、時、分、曜日)
df = df.withColumn("pickup_year", F.year(col("pickup_datetime"))) \
.withColumn("pickup_month", F.month(col("pickup_datetime"))) \
.withColumn("pickup_day", F.dayofmonth(col("pickup_datetime"))) \
.withColumn("pickup_hour", F.hour(col("pickup_datetime"))) \
.withColumn("pickup_minute", F.minute(col("pickup_datetime"))) \
.withColumn("pickup_weekday", F.dayofweek(col("pickup_datetime")))
# pickup_datetimeとdropoff_datetimeの差を計算し、trip_durationとして追加(単位:分)
df = df.withColumn("trip_duration",
(unix_timestamp(col("dropoff_datetime")) - unix_timestamp(col("pickup_datetime"))) / 60)
# 不要になったdropoff_datetime列を削除
df = df.drop("dropoff_datetime")
# 列の型を明示的に指定して変換
df = df.selectExpr(
"cast(pickup_datetime as timestamp)",
"cast(pickup_LocationID as int)",
"cast(dropoff_LocationID as int)",
"cast(payment_type as int)",
"cast(passenger_count as int)",
"cast(trip_distance as double)",
"cast(total_amount as double)",
"cast(pickup_year as int)",
"cast(pickup_month as int)",
"cast(pickup_day as int)",
"cast(pickup_hour as int)",
"cast(pickup_minute as int)",
"cast(pickup_weekday as int)",
"cast(trip_duration as double)"
)
# データのフィルタリング(適切な範囲の値のみを保持)
df = df.filter(
(col("pickup_LocationID").between(1, 265)) & # pickup_LocationIDが1〜265の範囲内
(col("dropoff_LocationID").between(1, 265)) & # dropoff_LocationIDが1〜265の範囲内
(col("payment_type").between(1, 5)) & # payment_typeが1〜5の範囲内
(col("passenger_count").between(1, 6)) & # passenger_countが1〜6の範囲内
(col("trip_distance") > 0) & # trip_distanceが0より大きい
(col("total_amount") > 0) & # total_amountが0より大きい
(col("pickup_year").between(2019, 2021)) & # pickup_yearが2019〜2021年の範囲内
(col("pickup_month").between(1, 12)) & # pickup_monthが1〜12月の範囲内
(col("pickup_day").between(1, 31)) & # pickup_dayが1〜31日の範囲内
(col("pickup_hour").between(0, 23)) & # pickup_hourが0〜23時の範囲内
(col("pickup_minute").between(0, 59)) & # pickup_minuteが0〜59分の範囲内
(col("trip_duration") > 0) # trip_durationが0分より大きい
)
# 四分位範囲(IQR)を用いた異常値の除去(trip_distanceに対して)
quantiles = df.approxQuantile("trip_distance", [0.25, 0.75], 0.01)
Q1, Q3 = quantiles[0], quantiles[1]
IQR = Q3 - Q1
lower_bound, upper_bound = Q1 - 1.5 * IQR, Q3 + 1.5 * IQR
df = df.filter((col("trip_distance") >= lower_bound) & (col("trip_distance") <= upper_bound))
# total_amountに対する異常値のトリミング(上下0.5%の範囲外を除外)
bounds = df.approxQuantile("total_amount", [0.005, 0.995], 0.0)
lower_bound, upper_bound = bounds[0], bounds[1]
df = df.filter((col("total_amount") >= lower_bound) & (col("total_amount") <= upper_bound))
# trip_durationに対するZスコアの計算と異常値の除去(Zスコア2:標準偏差の2倍を超える値を除外)
stats = df.select(avg(col('trip_duration')).alias('mean'), stddev(col('trip_duration')).alias('stddev')).collect()
mean_trip_duration = stats[0]['mean']
stddev_trip_duration = stats[0]['stddev']
df = df.filter(((col('trip_duration') - mean_trip_duration) / stddev_trip_duration <= 2) &
((col('trip_duration') - mean_trip_duration) / stddev_trip_duration >= -2))
return df # 処理されたデータフレームを返す
except Exception as e:
# エラーが発生した場合にエラーメッセージを表示
print(f"Error processing dataframe: {e}")
return None
# 各ファイルを読み込み、処理して保存する
for year, month_val, file_path in file_paths:
try:
# 指定されたパスからParquetファイルを読み込む
df = spark.read.parquet(file_path)
# 読み込んだデータフレームをユーザー定義関数を用いて処理する
processed_df = process_dataframe(df, month_val)
# 処理されたデータフレームが存在する場合
if processed_df is not None:
# 保存するテーブル名を作成
table_name = f"Silver_LH_NYC.cleaned_green_{year}_{month_val:02d}"
# 処理されたデータフレームをDelta形式で指定されたテーブルに上書き保存する
processed_df.write.mode("overwrite").option("overwriteSchema", "true").format("delta").saveAsTable(table_name)
print(f"Processed and saved data for cleaned_green_{year}_{month_val:02d}")
else:
# 処理中にエラーが発生した場合は、保存をスキップしメッセージを表示する
print(f"Skipping save for cleaned_green_{year}_{month_val:02d} due to processing error.")
# ファイルの読み込みや処理中にエラーが発生した場合のエラーハンドリング
except Exception as e:
print(f"Error processing file {file_path}: {e}")
出力:
Processed and saved data for cleaned_green_2019_01
↓
Processed and saved data for cleaned_green_2021_12まで
- Silver_LH_NYCのTableに作成されていることを確認します。

Delta Tableが適切に処理されているかユーザー定義関数で確認
# データベースをSilver_LH_NYCに設定
spark.sql("USE Silver_LH_NYC")
#データベース内のすべてのテーブル名を取得
#SHOW TABLES コマンドを使用してデータベース内のテーブル情報を取得
#select("tableName") でテーブル名のみを選択し、RDDに変換後、リストとして収集
tables = spark.sql("SHOW TABLES").select("tableName").rdd.flatMap(lambda x: x).collect()
# テーブル名リストを表示
print("List of tables in Silver_LH_NYC:")
for table_name in tables:
print(table_name)
出力:
List of tables in Silver_LH_NYC:
cleaned_green_2019_01
↓
cleaned_green_2021_12
# 確認の関数を定義
def validate_processed_table(table_name):
try:
df = spark.table(table_name)
# カラムの存在確認
expected_columns = ["pickup_datetime", "pickup_LocationID", "dropoff_LocationID",
"payment_type", "passenger_count", "trip_distance", "total_amount",
"pickup_year", "pickup_month", "pickup_day", "pickup_hour",
"pickup_minute", "pickup_weekday", "trip_duration"]
for col_name in expected_columns:
if col_name not in df.columns:
print(f"Column {col_name} is missing in table {table_name}")
return False
# 期待されるカラムの型
expected_schema = {
"pickup_datetime": "TimestampType()",
"pickup_LocationID": "IntegerType()",
"dropoff_LocationID": "IntegerType()",
"payment_type": "IntegerType()",
"passenger_count": "IntegerType()",
"trip_distance": "DoubleType()",
"total_amount": "DoubleType()",
"pickup_year": "IntegerType()",
"pickup_month": "IntegerType()",
"pickup_day": "IntegerType()",
"pickup_hour": "IntegerType()",
"pickup_minute": "IntegerType()",
"pickup_weekday": "IntegerType()",
"trip_duration": "DoubleType()"
}
for col_name, col_type in expected_schema.items():
if str(df.schema[col_name].dataType) != col_type:
print(f"Column {col_name} has incorrect type in table {table_name}. Expected {col_type}, got {str(df.schema[col_name].dataType)}")
return False
# フィルタリング条件の確認
filter_conditions = [
df["pickup_LocationID"].between(1, 265),
df["dropoff_LocationID"].between(1, 265),
df["payment_type"].between(1, 5),
df["passenger_count"].between(1, 6),
df["trip_distance"] > 0,
df["total_amount"] > 0,
df["pickup_year"].between(2019, 2021),
df["pickup_month"].between(1, 12),
df["pickup_day"].between(1, 31),
df["pickup_hour"].between(0, 23),
df["pickup_minute"].between(0, 59),
df["trip_duration"] > 0
]
for condition in filter_conditions:
if df.filter(~condition).count() > 0:
print(f"Filter condition failed for table {table_name}")
return False
print(f"Table {table_name} passed all checks.")
return True
except Exception as e:
print(f"Error validating table {table_name}: {e}")
return False
# テーブルの検証を実行
for table_name in tables:
validate_processed_table(f"Silver_LH_NYC.{table_name}")
出力:
Table Silver_LH_NYC.cleaned_green_2019_01 passed all checks.
↓
Table Silver_LH_NYC.cleaned_green_2021_12 passed all checks.
(補足)Silverレイヤーのすべてのtableを削除する方法
- 必要がない場合はスキップしてください。
- クリーンアップ用に使用ください。
# データベースをSilver_LH_NYCに設定
spark.sql("USE Silver_LH_NYC")
# データベース内のすべてのテーブル名を取得
tables = spark.sql("SHOW TABLES").select("tableName").rdd.flatMap(lambda x: x).collect()
# テーブル名リストを表示
print("List of tables in Silver_LH_NYC:")
for table in tables:
print(table)
# すべてのテーブルを削除
for table in tables:
spark.sql(f"DROP TABLE IF EXISTS {table}")
print("All tables in Silver_LH_NYC have been dropped.")
まとめとTips
- 「1.データ探索の基礎」で実装した処理をユーザー定義関数(process_dataframe)として作成
- Bronzeレイヤーに保存されている2019年1月-2021年12月までのデータを一括処理
- Silverレイヤーのテーブルに処理したクリーンデータを保存
- データが適切に処理されているか、ユーザー定義関数(validate_processed_table)で確認
- ETLツールであるDataflowを使用すればGUIで分かりやすく処理できます。今回はコピペできるようにnotebookで処理してます。
- Fabricのnotebookで別のNotebookを呼び出すこともできるので、ユーザー定義関数を別のnotebookに保管して汎用的に使用させることでできます。
3.可視化のためにGoldレイヤーにデータ集約
- Notebook名: 3.aggregate_Silver_to_Gold
- 既定のレイクハウス: Silver_LH_NYC(前回から変更が必要)

目的
- ビジネスレベルに活用できるように、Silverレイヤーを集計・加工し、スタースキーマ用にGoldレイヤーに保存
内容
-
スタースキーマ(ファクトテーブル、ディメンジョンテーブル)の作成
-
スタースキーマとは?
- リレーショナル データ ウェアハウスで広く採用されている成熟したモデリング手法です。
- モデルテーブルを「ディメンション」または「ファクト」として分けて管理します。
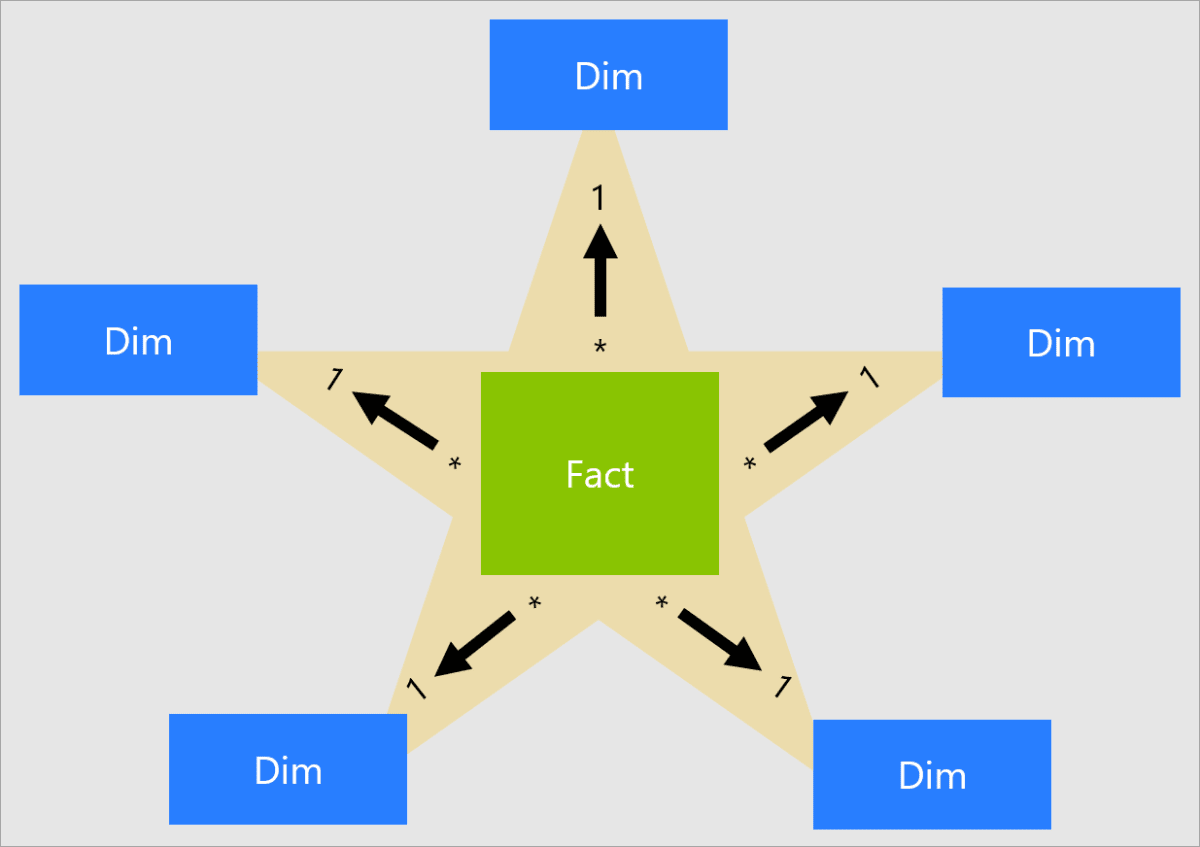
-
スタースキーマの特徴
- ファクトテーブル(Fact):スタースキーマでは、中央にファクトテーブルがあります。このファクトテーブルは、ビジネスプロセスの主要な測定値(メトリクス)を格納します。
-
ディメンジョンテーブル(Dim):ファクトテーブルの周囲に複数のディメンジョンテーブルがあります。
- これらのディメンジョンテーブルは、ファクトテーブルの主キーに関連する詳細情報を提供します。
- ディメンジョンテーブルには、製品、時間、顧客、場所などの属性情報が含まれます。Factテーブルに製品名や場所などを記載するとデータ量が多くなるため、IDでマッピングします。今回はLocationIDがわかりやすい例です。
-
スタースキーマを実装するメリット
- クエリパフォーマンスの向上:スタースキーマはシンプルな一対多の関係を持つため、複雑なクエリでもパフォーマンスが向上します。データの結合がシンプルで効率的です。
- データの理解と管理が容易:ディメンジョンテーブルとファクトテーブルに分けることで、データの構造が明確になり、ユーザーがデータを理解しやすくなります。
- データの一貫性の向上:ディメンジョンテーブルに詳細情報をまとめることで、データの一貫性と整合性が保たれます。
- 再利用可能なディメンジョン:同じディメンジョンテーブルを複数のファクトテーブルで再利用できるため、データモデルの設計が効率的です。変更時も容易に変更できます。
-
-
作成するファクトテーブル: fact_tripの作成(2019-2021年の結合データ)
-
作成するディメンジョンテーブル: dim_location, dim_paymenttype, dim_locationの作成
Notebook
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
fact_tripの作成
# データベースをSilver_LH_NYCに設定
spark.sql("USE Silver_LH_NYC")
# データベース内のすべてのテーブル名を取得
tables = spark.sql("SHOW TABLES").select("tableName").rdd.flatMap(lambda x: x).collect()
# テーブル名リストを表示
print("List of tables in Silver_LH_NYC:")
for table_name in tables:
print(table_name)
# すべてのテーブルを結合するデータフレームを作成
fact_tripdf = None
for table_name in tables:
df = spark.table(table_name)
if fact_tripdf is None:
fact_tripdf = df
else:
fact_tripdf = fact_tripdf.union(df)
出力:
List of tables in Silver_LH_NYC:
cleaned_green_2019_01
↓
cleaned_green_2021_12まで
# 実施した内容が正確に反映されていることを確認
# 結合されたデータフレームの表示
display(fact_tripdf.describe())
- 2019年から2021年までのデータが含まれている

# Table として保存
fact_tripdf.write.mode("overwrite").option("overwriteSchema", "true").saveAsTable("Gold_LH_NYC.fact_trip")
dim_weekdayの作成
# 既存のテーブルを削除
spark.sql("DROP TABLE IF EXISTS Gold_LH_NYC.dim_weekday")
# データの準備
data = [
(1, "Sunday"),
(2, "Monday"),
(3, "Tuesday"),
(4, "Wednesday"),
(5, "Thursday"),
(6, "Friday"),
(7, "Saturday")
]
# スキーマの定義
schema = StructType([
StructField("pickup_weekday", IntegerType(), True),
StructField("description", StringType(), True)
])
# データフレームの作成
dim_weekday_df = spark.createDataFrame(data, schema)
# テーブルとして保存
dim_weekday_df.write.mode("overwrite").saveAsTable("Gold_LH_NYC.dim_weekday")
df = spark.sql("SELECT * FROM Gold_LH_NYC.dim_weekday")
display(df)

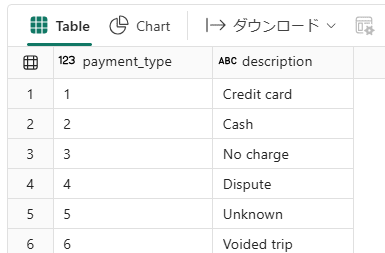
dim_paymenttypeの作成
# 既存のテーブルを削除
spark.sql("DROP TABLE IF EXISTS Gold_LH_NYC.dim_paymenttype")
# データの準備
data = [
(1, "Credit card"),
(2, "Cash"),
(3, "No charge"),
(4, "Dispute"),
(5, "Unknown"),
(6, "Voided trip")
]
# スキーマの定義
schema = StructType([
StructField("payment_type", IntegerType(), True),
StructField("description", StringType(), True)
])
# データフレームの作成
dim_paymenttypedf = spark.createDataFrame(data, schema)
# テーブルとして保存
dim_paymenttypedf.write.mode("overwrite").saveAsTable("Gold_LH_NYC.dim_paymenttype")
dim_locationの作成
-
こちらにLocationIDの詳細が記載されています。
-
こちらのデータを使用してディメンジョンテーブルを作成します。

-
URLからCSVファイルを読み込む操作がサポートされていないようなので、まずCSVファイルをローカルにダウンロードし、その後PySparkで読み込む必要があります。
import requests
csv_url = "https://d37ci6vzurychx.cloudfront.net/misc/taxi_zone_lookup.csv"
response = requests.get(csv_url)
with open('/lakehouse/default/Files/taxi_zone_lookup.csv', 'wb') as file:
file.write(response.content)
- Silver_LH_NYCのFilesにtaxi_zone_lookup.csvがダウンロードされていることを確認します。
# スキーマの定義
schema = StructType([
StructField("LocationID", IntegerType(), True),
StructField("Borough", StringType(), True),
StructField("Zone", StringType(), True),
StructField("service_zone", StringType(), True)
])
# CSVファイルの読み込み
dim_location = spark.read.format("csv").schema(schema).option("header", "true").load("Files/taxi_zone_lookup.csv")
# Deltaテーブルとして保存
dim_location.write.format("delta").mode("overwrite").saveAsTable("Gold_LH_NYC.dim_location")
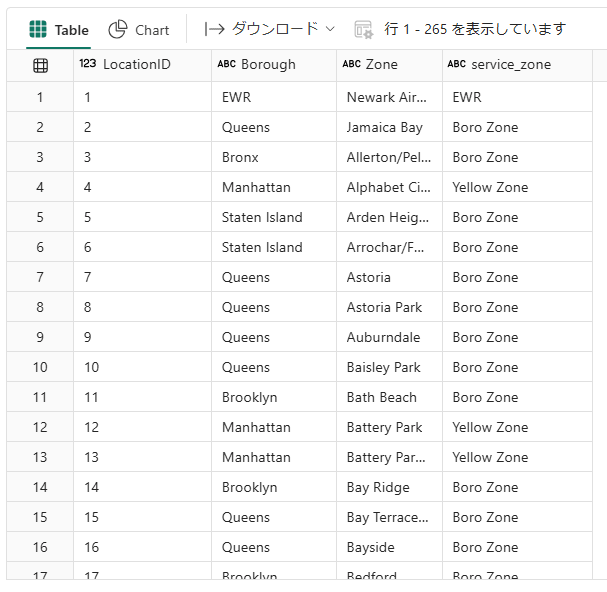
display(spark.sql("SELECT * FROM Gold_LH_NYC.dim_location ORDER BY LocationID ASC"))
-
LocationIDがどこに対応しているかわかります。
-
最終的に以下のテーブルがGold_LH_NYCに作成されています。

まとめとTips
- ファクトテーブルとディメンジョンテーブルを作成しました。
- 必要なファイル(taxi_zone_lookup.csv)をダウンロードしテーブルの作成をしました。
- 手動でダウンロードしてFilesにアップロードしても同様のことができます。
4.基本的なデータ探索
- Notebook名: 4.Basic_Analysis_Gold
- 既定のレイクハウス: Gold_LH_NYC(前回から変更が必要)
目的
- Notebookを使用してGoldレイヤーのデータ探索を行う
- 基本的な内容を実行し、notebookでの可視化を行う
内容
- 以下の内容を可視化していきます。
- 月、時間、曜日ごとの乗客者数の変化
- 合計金額(total_amount)の分布
- 移動距離(trip_distance)の分布
- 移動時間(trip_duration)の分布
- 支払い方法(payment_type)の分布
- 乗客数(passenger_count)の分布
- 人気のpickup_LocationIDとdropoff_LocationIDを表示
Notebook
事前準備
from pyspark.sql.functions import col, sum, mean, stddev, min, max, count, dayofweek, hour
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
import pandas as pd
import matplotlib.pyplot as plt
# Spark SQL を使用して、現在の既定のレイクハウスと同じワークスペースからのレイクハウスに対してクエリを実行してください。
df = spark.sql("SELECT * FROM Gold_LH_NYC.fact_trip")
dim_weekday = spark.sql("SELECT * FROM Gold_LH_NYC.dim_weekday")
dim_paymenttype = spark.sql("SELECT * FROM Gold_LH_NYC.dim_paymenttype")
dim_location = spark.sql("SELECT * FROM Gold_LH_NYC.dim_location")
基本的なデータ分析
月ごとの乗客者数の変化
# 月ごとに乗客者数を集計
monthly_passenger_count = df.groupBy("pickup_year", "pickup_month") \
.agg(sum("passenger_count").alias("total_passenger_count")) \
.orderBy("pickup_year", "pickup_month")
# Pandasデータフレームに変換
monthly_passenger_count_pd = monthly_passenger_count.toPandas()
# pickup_yearとpickup_monthを文字列として結合して新しい列を作成
monthly_passenger_count_pd['year_month'] = monthly_passenger_count_pd['pickup_year'].astype(str) + '-' + monthly_passenger_count_pd['pickup_month'].astype(str).str.zfill(2)
# 年月順にソート
monthly_passenger_count_pd = monthly_passenger_count_pd.sort_values('year_month')
#結果を表で表示
display(monthly_passenger_count_pd)
# 可視化
plt.figure(figsize=(12, 6))
plt.plot(monthly_passenger_count_pd['year_month'], monthly_passenger_count_pd['total_passenger_count'], marker='o')
plt.xticks(rotation=90)
plt.xlabel('Year-Month')
plt.ylabel('Total Passenger Count')
plt.title('Monthly Passenger Count')
plt.grid(True)
plt.tight_layout()
plt.show()
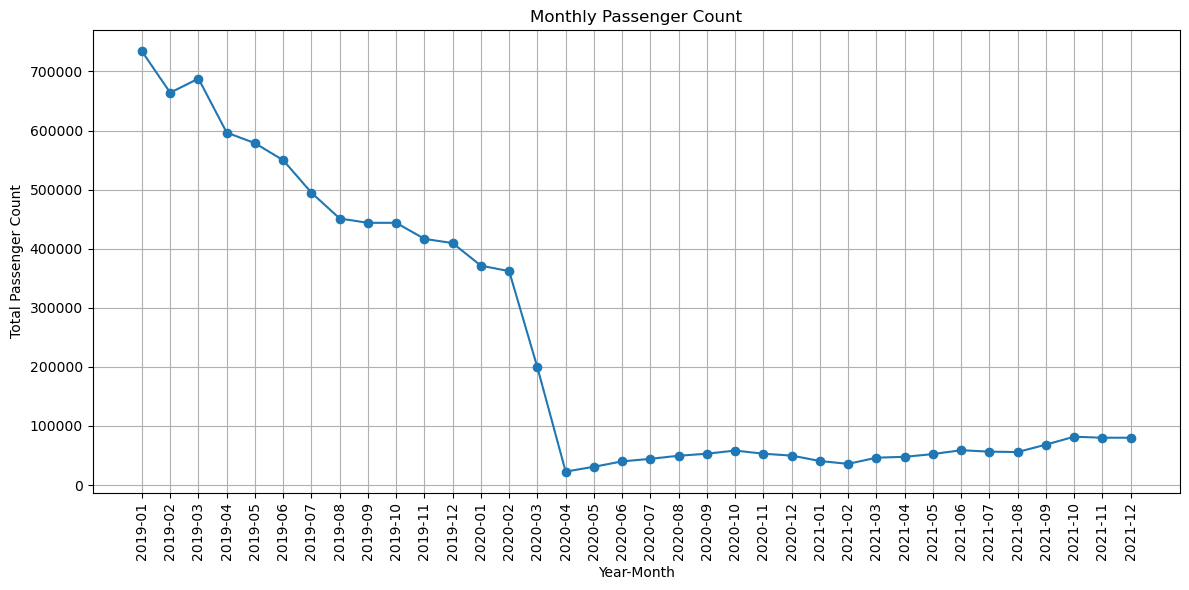
- 感染症の影響で2020年初頭から急激に乗客数が下がっているのがわかります。
時間ごとの乗客数の変化
# 時間ごとに乗客者数を集計
hourly_passenger_count = df.groupBy("pickup_hour") \
.agg(sum("passenger_count").alias("total_passenger_count")) \
.orderBy("pickup_hour")
# Pandasデータフレームに変換
hourly_passenger_count_pd = hourly_passenger_count.toPandas()
# カラフルに可視化
plt.figure(figsize=(12, 6))
plt.bar(hourly_passenger_count_pd['pickup_hour'], hourly_passenger_count_pd['total_passenger_count'], color=plt.cm.rainbow(hourly_passenger_count_pd['pickup_hour'] / hourly_passenger_count_pd['pickup_hour'].max()))
plt.xticks(hourly_passenger_count_pd['pickup_hour'])
plt.xlabel('Hour of Day')
plt.ylabel('Total Passenger Count')
plt.title('Hourly Passenger Count')
plt.grid(True)
plt.tight_layout()
plt.show()
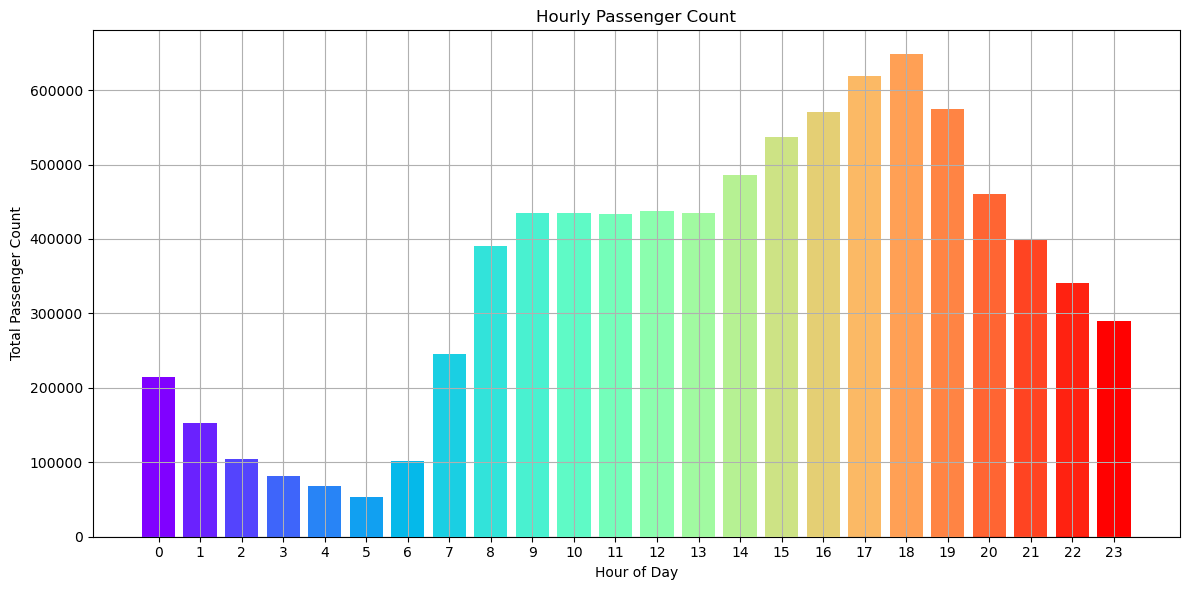
- 朝6時くらいから徐々に増加し18時にピークを迎えます。
曜日ごとの乗客者数の変化
# 曜日ごとに乗客者数を集計
weekday_passenger_count = df.groupBy("pickup_weekday") \
.agg(sum("passenger_count").alias("total_passenger_count")) \
.orderBy("pickup_weekday")
# マッピングテーブルと結合
weekday_passenger_count = weekday_passenger_count.join(dim_weekday, on="pickup_weekday")
# 結果の表示
display(weekday_passenger_count)
# Pandasデータフレームに変換
weekday_passenger_count_pd = weekday_passenger_count.toPandas()
# 曜日順に並び替え
weekday_passenger_count_pd = weekday_passenger_count_pd.sort_values('pickup_weekday')
# カラーマップを使用して濃淡を設定
norm = plt.Normalize(weekday_passenger_count_pd['total_passenger_count'].min(), weekday_passenger_count_pd['total_passenger_count'].max())
colors = plt.cm.viridis(norm(weekday_passenger_count_pd['total_passenger_count']))
# 可視化
fig, ax = plt.subplots(figsize=(12, 6))
bars = ax.bar(weekday_passenger_count_pd['description'], weekday_passenger_count_pd['total_passenger_count'], color=colors)
plt.xlabel('Day of Week')
plt.ylabel('Total Passenger Count')
plt.title('Passenger Count by Day of Week')
plt.grid(True)
plt.tight_layout()
# カラーバーの追加
sm = plt.cm.ScalarMappable(cmap='viridis', norm=norm)
sm.set_array([])
fig.colorbar(sm, ax=ax, label='Passenger Count')
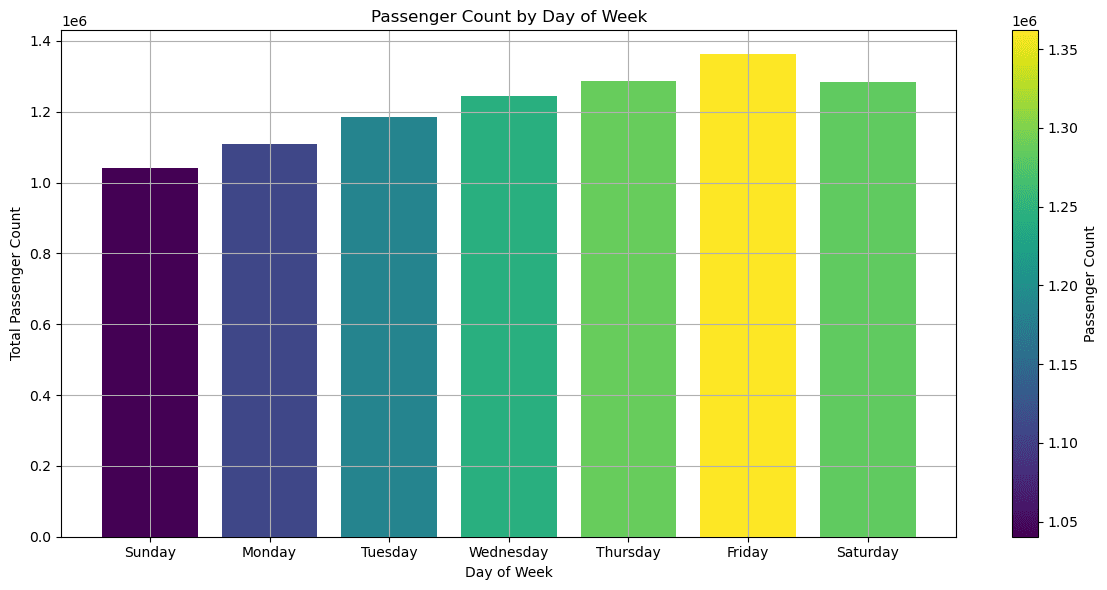
- 日曜日が一番乗客数が少なく、金曜日が一番多いことがわかります。
合計金額(total_amount)の分布
# 基本的な統計情報の取得
total_amount_stats = df.select(
mean("total_amount").alias("mean"),
stddev("total_amount").alias("stddev"),
min("total_amount").alias("min"),
max("total_amount").alias("max"),
count("total_amount").alias("count")
).collect()
# 結果の取得
mean_value = total_amount_stats[0]['mean']
stddev_value = total_amount_stats[0]['stddev']
min_value = total_amount_stats[0]['min']
max_value = total_amount_stats[0]['max']
count_value = total_amount_stats[0]['count']
# Pandasデータフレームに変換
total_amount_pd = df.select("total_amount").toPandas()
# ヒストグラムを作成
plt.figure(figsize=(10, 6))
plt.hist(total_amount_pd['total_amount'], bins=50, color='blue', edgecolor='black', alpha=0.7)
# 統計情報の表示
plt.axvline(mean_value, color='r', linestyle='dashed', linewidth=1, label=f'Mean: {mean_value:.2f}')
# テキストの追加
plt.text(mean_value, plt.ylim()[1]*0.8, f'Mean: {mean_value:.2f}', color='r', ha='center', fontsize=16)
# グラフのラベルとタイトル
plt.xlabel('Total Amount')
plt.ylabel('Frequency')
plt.title('Distribution of Total Amount')
plt.legend()
plt.grid(True)
plt.tight_layout()
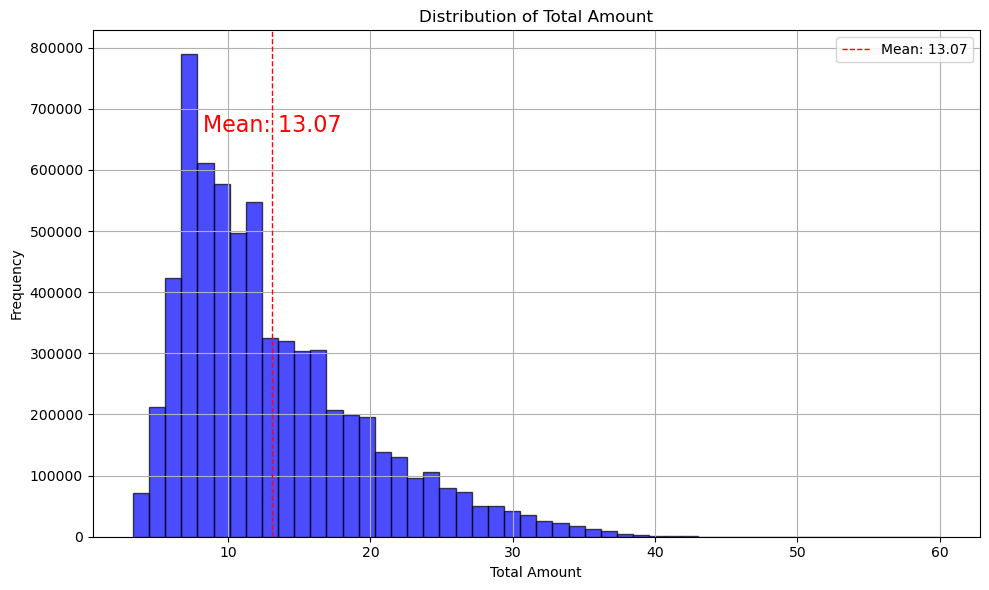
- 約13ドルが平均利用料金とわかります。
移動距離(trip_distance)の分布
# マイルからメートルへの変換
df_m = df.withColumn("trip_distance_meters", col("trip_distance") * 1609.34)
# 基本的な統計情報の取得
trip_distance_stats = df_m.select(
mean("trip_distance_meters").alias("mean")
).collect()
# 結果の取得
mean_value = trip_distance_stats[0]['mean']
# 必要なカラムを選択してPandasデータフレームに変換
trip_distance_pd = df_m.select("trip_distance_meters").toPandas()
# ヒストグラムを作成
plt.figure(figsize=(10, 6))
plt.hist(trip_distance_pd['trip_distance_meters'], bins=50, color='silver', edgecolor='black', alpha=0.7)
# 平均値の表示
plt.axvline(mean_value, color='r', linestyle='dashed', linewidth=1, label=f'Mean: {mean_value:.2f} meters')
# テキストの追加(位置調整とフォントサイズ変更)
plt.text(mean_value, plt.ylim()[1]*0.9, f'Mean: {mean_value:.2f} meters', color='r', ha='center', fontsize=12)
# グラフのラベルとタイトル
plt.xlabel('Trip Distance (meters)', fontsize=14)
plt.ylabel('Frequency', fontsize=14)
plt.title('Distribution of Trip Distance (meters)', fontsize=16)
plt.legend(fontsize=12)
plt.grid(True)
plt.tight_layout()
plt.show()
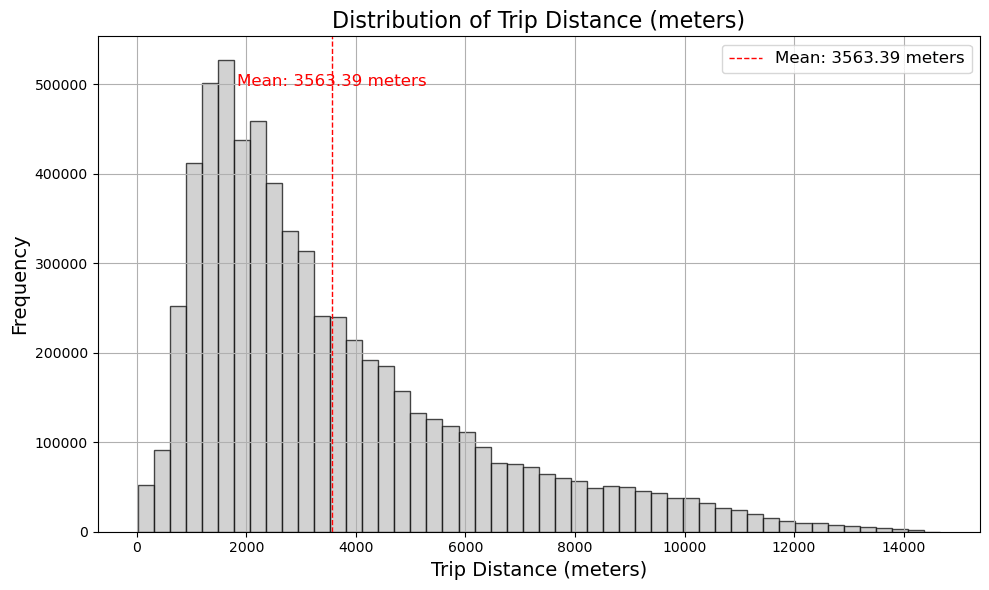
- 約3.5キロメートルが平均移動距離とわかります。
移動時間(trip_duration)の分布
# 基本的な統計情報の取得
trip_duration_stats = df.select(
mean("trip_duration").alias("mean")
).collect()
# 結果の取得
mean_duration = trip_duration_stats[0]['mean']
# 必要なカラムを選択してPandasデータフレームに変換
trip_duration_pd = df.select("trip_duration").toPandas()
# ヒストグラムを作成
plt.figure(figsize=(10, 6))
plt.hist(trip_duration_pd['trip_duration'], bins=50, color='green', edgecolor='black', alpha=0.7)
# 平均値の表示
plt.axvline(mean_duration, color='r', linestyle='dashed', linewidth=1, label=f'Mean: {mean_duration:.2f} minutes')
# テキストの追加(位置調整とフォントサイズ変更)
plt.text(mean_duration, plt.ylim()[1]*0.9, f'Mean: {mean_duration:.2f} minutes', color='r', ha='center', fontsize=12)
# グラフのラベルとタイトル
plt.xlabel('Trip Duration (minutes)', fontsize=14)
plt.ylabel('Frequency', fontsize=14)
plt.title('Distribution of Trip Duration', fontsize=16)
plt.legend(fontsize=12)
plt.grid(True)
plt.tight_layout()
plt.show()
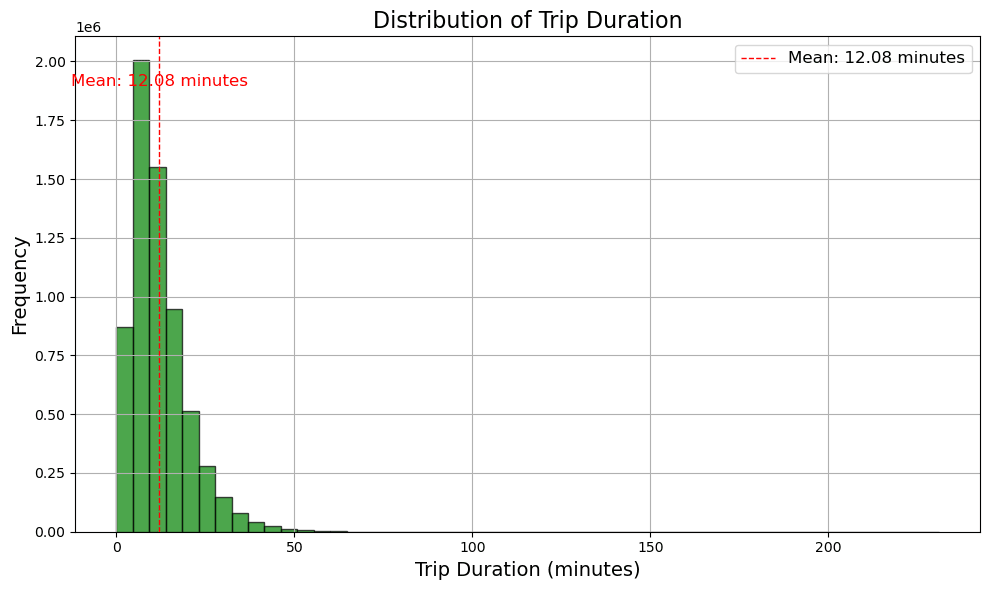
- 約12分が平均移動時間とわかります。
移動時間(trip_duration)と合計金額(total_amount)の関係図
# 必要なカラムを選択してPandasデータフレームに変換
df_pd = df.select("trip_duration", "total_amount").toPandas()
# 散布図を作成
plt.figure(figsize=(10, 6))
plt.scatter(df_pd['trip_duration'], df_pd['total_amount'], alpha=0.5, edgecolor='k')
# グラフのラベルとタイトル
plt.xlabel('Trip Duration (minutes)', fontsize=14)
plt.ylabel('Total Amount ($)', fontsize=14)
plt.title('Relationship between Trip Duration and Total Amount', fontsize=16)
plt.grid(True)
plt.tight_layout()
plt.show()
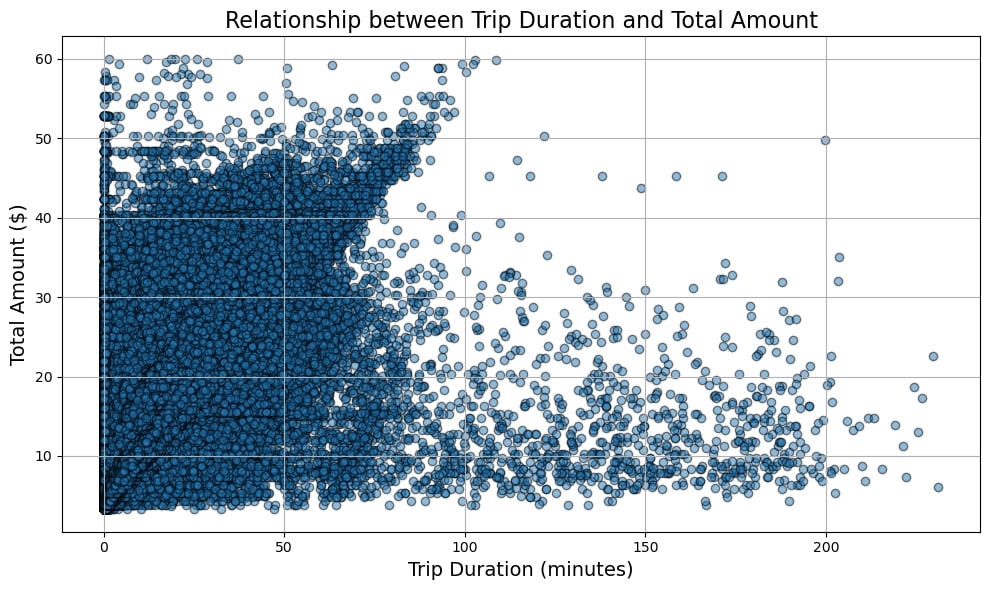
支払い方法(payment_type)の分布
# `payment_type` の分布を集計し、ディメンションテーブルと結合
payment_type_distribution = df.groupBy("payment_type").agg(count("payment_type").alias("count"))
payment_type_distribution = payment_type_distribution.join(dim_paymenttype, on="payment_type").orderBy(col("count").desc())
# Pandasデータフレームに変換
payment_type_pd = payment_type_distribution.toPandas()
# ヒストグラムを作成
plt.figure(figsize=(10, 6))
bars = plt.bar(payment_type_pd['description'], payment_type_pd['count'], color='blue', edgecolor='black', alpha=0.7)
# 各バーの上に数を表示
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2, yval, int(yval), va='bottom', ha='center', fontsize=12, color='black')
# グラフのラベルとタイトル
plt.xlabel('Payment Type', fontsize=14)
plt.ylabel('Count', fontsize=14)
plt.title('Distribution of Payment Type', fontsize=16)
plt.grid(True)
plt.tight_layout()
plt.show()
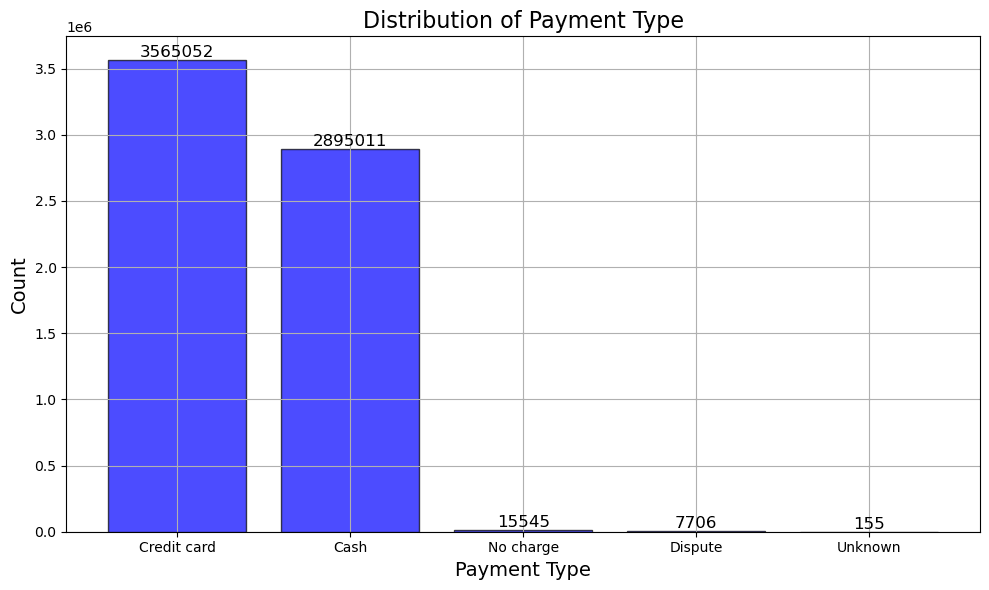
- 支払方法はほぼクレジットカードと現金です。
乗客数(passenger_count)の分布
# 必要なカラムを選択してPandasデータフレームに変換
passenger_count_pd = df.select("passenger_count").toPandas()
# ヒストグラムを作成
plt.figure(figsize=(10, 6))
plt.hist(passenger_count_pd['passenger_count'], bins=range(1, 11), color='blue', edgecolor='black', alpha=0.7, align='left')
# グラフのラベルとタイトル
plt.xlabel('Passenger Count', fontsize=14)
plt.ylabel('Frequency', fontsize=14)
plt.title('Distribution of Passenger Count', fontsize=16)
plt.grid(True)
plt.tight_layout()
plt.show()

- 1人で乗車しているケースが大半のようです。
人気のpickup_LocationIDとdropoff_LocationIDを表示
# pickup_LocationIDの分布を集計し、ディメンジョンテーブルと結合
pickup_location_distribution = df.groupBy("pickup_LocationID").agg(count("pickup_LocationID").alias("count")).orderBy(col("count").desc()).limit(5)
pickup_location_distribution = pickup_location_distribution.join(dim_location, pickup_location_distribution["pickup_LocationID"] == dim_location["LocationID"]).select("pickup_LocationID", "count", "Borough", "Zone", "service_zone").orderBy(col("count").desc())
# dropoff_LocationIDの分布を集計し、ディメンジョンテーブルと結合
dropoff_location_distribution = df.groupBy("dropoff_LocationID").agg(count("dropoff_LocationID").alias("count")).orderBy(col("count").desc()).limit(5)
dropoff_location_distribution = dropoff_location_distribution.join(dim_location, dropoff_location_distribution["dropoff_LocationID"] == dim_location["LocationID"]).select("dropoff_LocationID", "count", "Borough", "Zone", "service_zone").orderBy(col("count").desc())
# Pandasデータフレームに変換
pickup_location_pd = pickup_location_distribution.toPandas()
dropoff_location_pd = dropoff_location_distribution.toPandas()
# pickup_LocationIDのヒストグラムを作成
plt.figure(figsize=(10, 6))
plt.bar(pickup_location_pd['Zone'], pickup_location_pd['count'], color='blue', edgecolor='black', alpha=0.7)
plt.xlabel('Pickup Zone', fontsize=14)
plt.ylabel('Count', fontsize=14)
plt.title('Top 5 Pickup Locations', fontsize=16)
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
# dropoff_LocationIDのヒストグラムを作成
plt.figure(figsize=(10, 6))
plt.bar(dropoff_location_pd['Zone'], dropoff_location_pd['count'], color='green', edgecolor='black', alpha=0.7)
plt.xlabel('Dropoff Zone', fontsize=14)
plt.ylabel('Count', fontsize=14)
plt.title('Top 5 Dropoff Locations', fontsize=16)
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
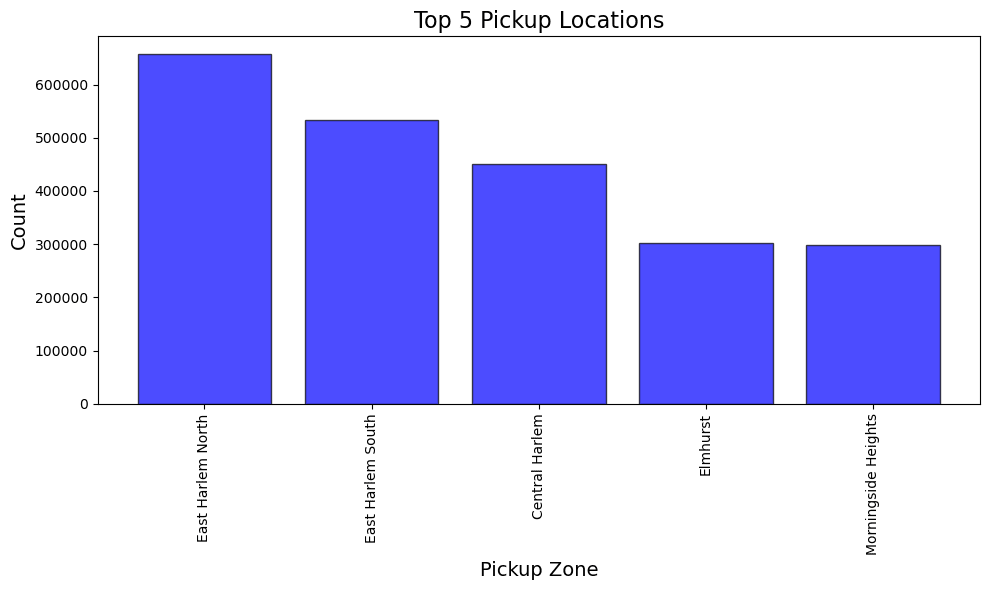

- 乗車も降車もEast Harlem Northが一番多くなってます。
まとめとTips
-
標準的なグラフを使用してデータ探索を行いました。
-
どのようなデータの特徴があるのかを把握するため、PowerBIレポートで表示する前にデータの分析を実施しました。
-
matplotlibなどはSparkのデータフレームに対応してないため、一度Pandasに変換する必要がある。
-
pasdasだとデフォルトの関数でIQR法など用意されているため、簡単に実装できる。
-
単一ノードでしか動かないのでSparkのデータフレームで分散処理させる必要があった。
-
plotlyなどを使用すると動作が重くなるので基本的にmatplotlibをメインに可視化を行いました。
5.高度なデータ分析
- Notebook名: 5.Advanced_Analysis_Gold
- 既定のレイクハウス: Gold_LH_NYC

目的
- notebook上で高度なデータ分析を行いデータに対するインサイトを得る
内容
- 以下の内容を可視化していきます。
- 曜日と時間ごとの乗客者数をヒートマップで表示
- 特定の曜日やどの時間帯に乗客が多いかを一目で確認
- ピックアップエリアのBoroughからドロップオフエリアのBoroughへの移動をサンキー図で可視化
- 時間ごとの平均速度
- 距離(trip_distance)をX軸に、運賃(total_amount)をY軸に、乗客数(passenger_count)をバブルのサイズとしてプロット
- ニューヨーク市の区画の表示。地図情報をダウンロード
- 乗客数が多いpickup_LocationIDを地図上に表示
Notebook
事前準備
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum, dayofweek, hour, mean, when, count
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.linear_model import LinearRegression
import plotly.graph_objects as go
from matplotlib import cm
import matplotlib.colors as mcolors
import requests, zipfile
df = spark.sql("SELECT * FROM Gold_LH_NYC.fact_trip")
dim_weekday = spark.sql("SELECT * FROM Gold_LH_NYC.dim_weekday")
dim_paymenttype = spark.sql("SELECT * FROM Gold_LH_NYC.dim_paymenttype")
dim_location = spark.sql("SELECT * FROM Gold_LH_NYC.dim_location")
高度なデータ分析
曜日と時間ごとの乗客者数をヒートマップで表示
# 曜日と時間を追加
df = df.withColumn("pickup_weekday", dayofweek(col("pickup_datetime"))) # 'pickup_datetime' 列から曜日を抽出し、新しい列 'pickup_weekday' を追加
df = df.withColumn("pickup_hour", hour(col("pickup_datetime"))) # 'pickup_datetime' 列から時間を抽出し、新しい列 'pickup_hour' を追加
# 曜日と時間ごとの乗客数を集計
# 曜日と時間ごとに 'passenger_count' を集計し、 'total_passenger_count' としてエイリアス
# 'pickup_weekday' と 'pickup_hour' でソート
weekday_hourly_passenger_count = df.groupBy("pickup_weekday", "pickup_hour") \
.agg(sum("passenger_count").alias("total_passenger_count")).orderBy("pickup_weekday", "pickup_hour")
# マッピングテーブルと結合
weekday_hourly_passenger_count = weekday_hourly_passenger_count.join(dim_weekday, on="pickup_weekday") # 'pickup_weekday' をキーとして 'dim_weekday' テーブルと結合
display(weekday_hourly_passenger_count) # 結果のデータフレームを表示
# SparkデータフレームをPandasデータフレームに変換
weekday_hourly_passenger_count_pd = weekday_hourly_passenger_count.toPandas()
# ピボットテーブルを作成
pivot_table = weekday_hourly_passenger_count_pd.pivot_table(
index="description", # 行ラベルとして 'description' を使用
columns="pickup_hour", # 列ラベルとして 'pickup_hour' を使用
values="total_passenger_count", # 集計値として 'total_passenger_count' を使用
aggfunc='sum', # 集計関数として 'sum' を使用
fill_value=0 # 欠損値を0で埋める
)
# 曜日順に並び替え
pivot_table = pivot_table.reindex(["Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"]) # 曜日順に並び替え
# ヒートマップを作成
plt.figure(figsize=(12, 8)) # グラフのサイズを設定
sns.heatmap(
pivot_table, # ピボットテーブルをヒートマップとしてプロット
annot=True, # 各セルに値を表示
fmt="d", # 整数形式で値を表示
cmap="YlGnBu", # カラーマップを 'YlGnBu' に設定
linewidths=.5, # セル間の線の幅を設定
cbar_kws={'label': 'Total Passenger Count'} # カラーバーのラベルを設定
)
# グラフのラベルとタイトル
plt.xlabel('Hour of Day', fontsize=14) # x軸ラベルを設定
plt.ylabel('Day of Week', fontsize=14) # y軸ラベルを設定
plt.title('Heatmap of Passenger Count by Day of Week and Hour', fontsize=16) # グラフのタイトルを設定
plt.tight_layout() # レイアウトを調整して要素間の重なりを防ぐ
plt.show() # グラフを表示
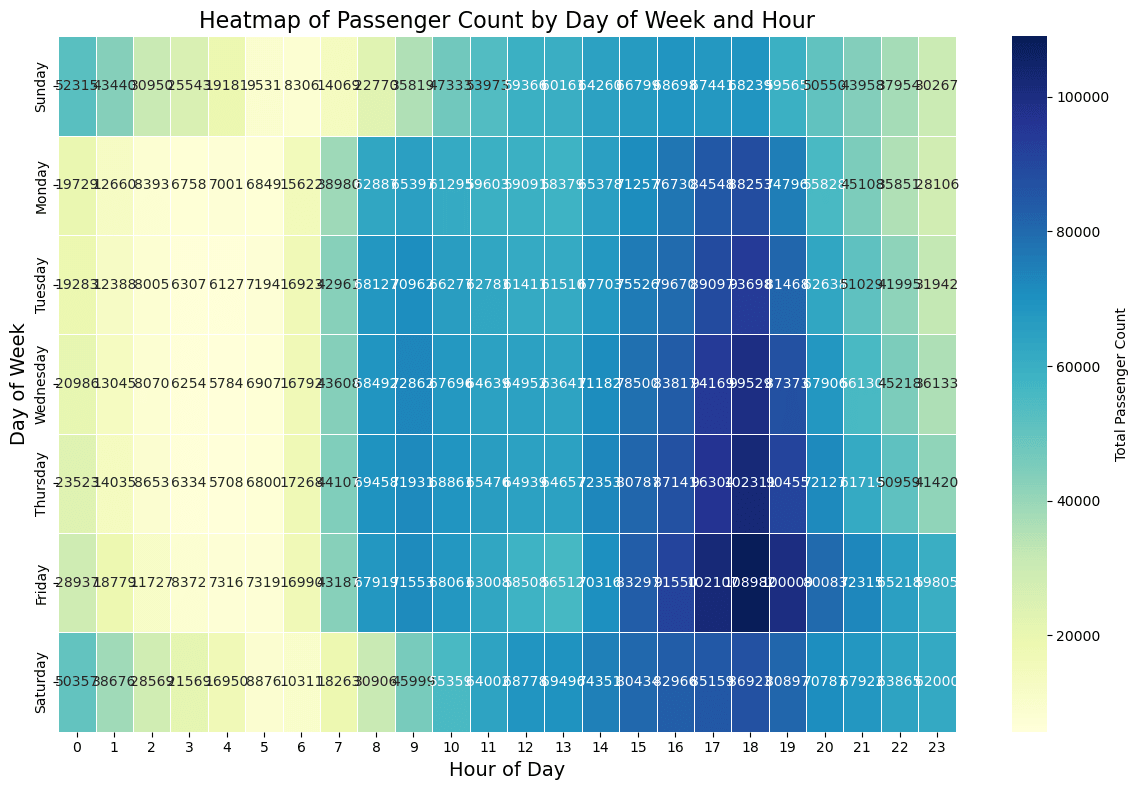
- 金曜日の夕方が一番人数は多いことがわかります
- 土日の午前0時は他の曜日に比べると少し混んでいることがわかります
どの時間帯にどこで乗客が多いかを一目で確認
# 時間とBoroughを追加
# 'pickup_datetime' 列から時間を抽出し、新しい列 'pickup_hour' を追加
df = df.withColumn("pickup_hour", hour(col("pickup_datetime")))
# 各Boroughの乗客数を集計
# 時間と 'pickup_LocationID' ごとに 'passenger_count' を集計し、 'total_passenger_count' としてエイリアス
borough_passenger_count = df.groupBy("pickup_hour", "pickup_LocationID").agg(sum("passenger_count").alias("total_passenger_count"))
# ディメンジョンテーブルと結合してBorough情報を追加
# 'pickup_LocationID' をキーとして 'dim_location' テーブルと左結合し、 'Borough' 列を追加
borough_passenger_count = borough_passenger_count.join(dim_location, borough_passenger_count["pickup_LocationID"] == dim_location["LocationID"], "left") \
.select("pickup_hour", "Borough", "total_passenger_count")
# 各Boroughごとの乗客数を時間ごとに集計
# 時間とBoroughごとに 'total_passenger_count' を集計し、 'total_passenger_count' としてエイリアス
# 'pickup_hour' と 'Borough' でソート
borough_hourly_passenger_count = borough_passenger_count.groupBy("pickup_hour", "Borough").agg(sum("total_passenger_count").alias("total_passenger_count")).orderBy("pickup_hour", "Borough")
# 結果の表示
display(borough_hourly_passenger_count)
# SparkデータフレームをPandasデータフレームに変換
borough_hourly_passenger_count_pd = borough_hourly_passenger_count.toPandas()
# ピボットテーブルを作成
pivot_table = borough_hourly_passenger_count_pd.pivot(
index="pickup_hour", # 行ラベルとして 'pickup_hour' を使用
columns="Borough", # 列ラベルとして 'Borough' を使用
values="total_passenger_count" # 集計値として 'total_passenger_count' を使用
).fillna(0) # 欠損値を0で埋める
# プロットの作成
plt.figure(figsize=(12, 8)) # プロットのサイズを設定
pivot_table.plot(
kind='area', # 面グラフとしてプロット
stacked=True, # スタック形式に設定
figsize=(12, 8), # プロットのサイズを再設定
cmap='tab20' # カラーマップを 'tab20' に設定
)
# グラフのラベルとタイトル
plt.xlabel('Hour of Day', fontsize=14) # x軸ラベルを設定
plt.ylabel('Total Passenger Count', fontsize=14) # y軸ラベルを設定
plt.title('Passenger Count by Hour and Borough', fontsize=16) # グラフのタイトルを設定
plt.legend(title='Borough', bbox_to_anchor=(1.05, 1), loc='upper left') # 凡例を設定
plt.tight_layout() # レイアウトを調整して要素間の重なりを防ぐ
plt.show()
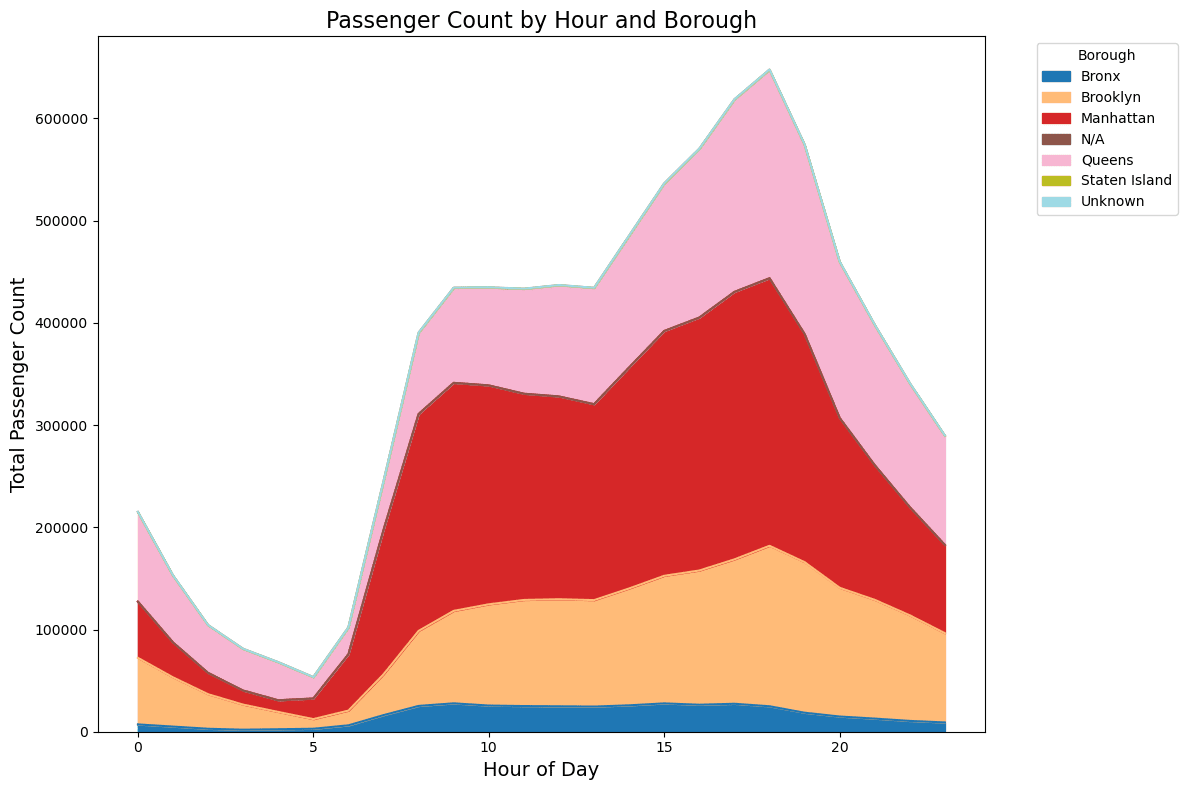
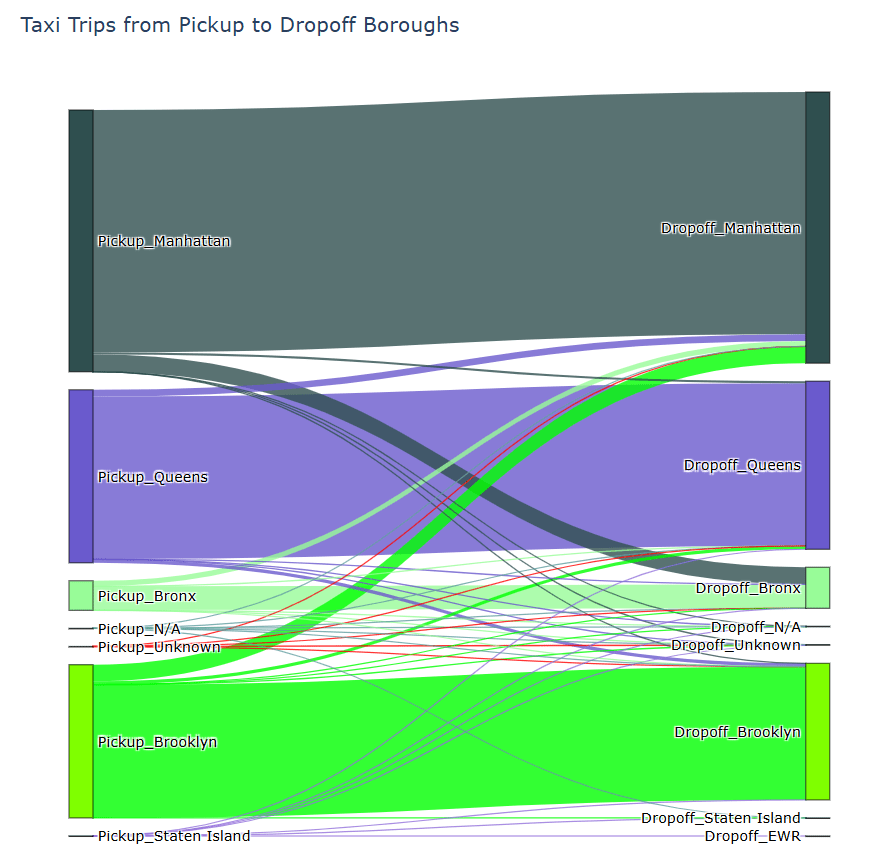
どのエリアで乗ってどのエリアで降りているかSankey図で表示
# ピックアップBoroughとドロップオフBoroughの関係を集計
# ピックアップのBorough情報を追加
# ドロップオフのBorough情報を追加
# ピックアップとドロップオフのBoroughごとにカウントを集計
borough_flow = df.join(dim_location, df["pickup_LocationID"] == dim_location["LocationID"], "left") \
.select(col("pickup_LocationID"), col("dropoff_LocationID"), col("Borough").alias("pickup_Borough")) \
.join(dim_location, df["dropoff_LocationID"] == dim_location["LocationID"], "left") \
.select("pickup_Borough", col("Borough").alias("dropoff_Borough")) \
.groupBy("pickup_Borough", "dropoff_Borough").agg(count("*").alias("count")) \
.orderBy(col("count").desc())
# 結果の表示
display(borough_flow) # 結果のデータフレームを表示
# SparkデータフレームをPandasデータフレームに変換
borough_flow_pd = borough_flow.toPandas()
# 出発地点と到着地点のBorough情報を取得
source_boroughs = "Pickup_" + borough_flow_pd['pickup_Borough'] # 'pickup_Borough' 列に 'Pickup_' プレフィックスを追加
target_boroughs = "Dropoff_" + borough_flow_pd['dropoff_Borough'] # 'dropoff_Borough' 列に 'Dropoff_' プレフィックスを追加
all_boroughs = pd.concat([source_boroughs, target_boroughs]).unique() # 全てのBorough情報を一意に取得
borough_to_index = {borough: idx for idx, borough in enumerate(all_boroughs)} # Borough情報にインデックスを割り当て
# カラー設定
unique_boroughs = borough_flow_pd['pickup_Borough'].unique() # 一意なBorough情報を取得
colors = list(mcolors.CSS4_COLORS.values()) # CSS4の全ての色を取得
np.random.shuffle(colors) # 色をランダムにシャッフル
borough_colors = {borough: color for borough, color in zip(unique_boroughs, colors)} # Boroughごとに色を割り当て
# ノードの色設定
node_colors = []
for borough in all_boroughs:
borough_name = borough.split('_')[1] # プレフィックスを除いたBorough名を取得
node_colors.append(borough_colors.get(borough_name, 'gray')) # Borough名に対応する色を取得
# リンクの色設定
link_colors = ['rgba' + str(mcolors.to_rgba(borough_colors[borough], alpha=0.8)) for borough in borough_flow_pd['pickup_Borough']]
# サンキー図のデータ作成
source_indices = source_boroughs.map(borough_to_index) # 出発地点のインデックスを取得
target_indices = target_boroughs.map(borough_to_index) # 到着地点のインデックスを取得
values = borough_flow_pd['count'] # リンクの幅を取得
# サンキー図の作成
fig = go.Figure(data=[go.Sankey(
node=dict(
pad=15, # ノードの間隔
thickness=20, # ノードの厚さ
line=dict(color="black", width=0.5), # ノードの境界線の設定
label=all_boroughs, # ノードのラベル
color=node_colors # ノードの色
),
link=dict(
source=source_indices, # ノードの出発地点
target=target_indices, # ノードの到着地点
value=values, # リンクの幅
color=link_colors # リンクの色
)
)])
# レイアウトの設定
fig.update_layout(title_text="Taxi Trips from Pickup to Dropoff Boroughs", font_size=12, height=800) # 図のタイトルとフォントサイズ、高さを設定
# 図の表示
fig.show()
時間ごとの平均速度
# マイルをメートルに変換 (1マイル = 1609.34メートル)
df_distance_meters = df.withColumn("trip_distance_meters", col("trip_distance") * 1609.34) # 'trip_distance' 列をメートルに変換し、新しい列 'trip_distance_meters' を追加
# 分を時に変換
df_duration_hours = df_distance_meters.withColumn("trip_duration_hours", col("trip_duration") / 60) # 'trip_duration' 列を分から時に変換し、新しい列 'trip_duration_hours' を追加
# 時速を計算
df_speed_kph = df_duration_hours.withColumn("speed_kph", col("trip_distance_meters") / 1000 / col("trip_duration_hours")) # 'trip_distance_meters' と 'trip_duration_hours' を使用して時速 (km/h) を計算し、新しい列 'speed_kph' を追加
# 時間帯を分類
df_speed_kph = df_speed_kph.withColumn("time_of_day",
when((col("pickup_hour") >= 6) & (col("pickup_hour") < 12), "morning") # 6時から12時を 'morning' に分類
.when((col("pickup_hour") >= 12) & (col("pickup_hour") < 18), "afternoon") # 12時から18時を 'afternoon' に分類
.when((col("pickup_hour") >= 18) & (col("pickup_hour") < 24), "evening") # 18時から24時を 'evening' に分類
.otherwise("late night")) # その他の時間帯を 'late night' に分類
# 結果の確認
df_speed_kph.select("pickup_hour", "speed_kph", "time_of_day").show(5) # 'pickup_hour', 'speed_kph', 'time_of_day' の最初の5行を表示
# 各時間ごとの平均速度を計算
# 'pickup_hour' と 'time_of_day' ごとに 'speed_kph' の平均を計算し、 'avg_speed_kph' としてエイリアス
hourly_avg_speed = df_speed_kph.groupBy("pickup_hour", "time_of_day").agg(mean("speed_kph").alias("avg_speed_kph")).orderBy("pickup_hour") # 'pickup_hour' でソート
# 結果の表示
hourly_avg_speed.show() # 'hourly_avg_speed' データフレームを表示
# Pandasデータフレームに変換
hourly_avg_speed_pd = hourly_avg_speed.toPandas() # SparkデータフレームをPandasデータフレームに変換
# カラーマップを設定
color_map = {
"morning": "orange",
"afternoon": "blue",
"evening": "green",
"late night": "red"
} # 時間帯ごとの色を設定
# プロットの作成
plt.figure(figsize=(12, 8)) # プロットのサイズを設定
# 時間帯ごとにプロット
for time_of_day, group in hourly_avg_speed_pd.groupby("time_of_day"):
plt.plot(group['pickup_hour'], group['avg_speed_kph'], marker='o', color=color_map[time_of_day], label=time_of_day) # 時間帯ごとに 'pickup_hour' と 'avg_speed_kph' をプロット
# グラフのラベルとタイトル
plt.xlabel('Hour of Day', fontsize=14) # x軸ラベルを設定
plt.ylabel('Average Speed (kph)', fontsize=14) # y軸ラベルを設定
plt.title('Average Speed by Hour of Day', fontsize=16) # グラフのタイトルを設定
plt.legend(title='Time of Day') # 凡例を設定
plt.grid(True) # グリッドを表示
plt.tight_layout() # レイアウトを調整して要素間の重なりを防ぐ
# 図の表示
plt.show() # 図を表示

- 明け方の方が平均速度が高いことがわかります。
- 日中は車の数も多いので平均速度が低いことがわかります。
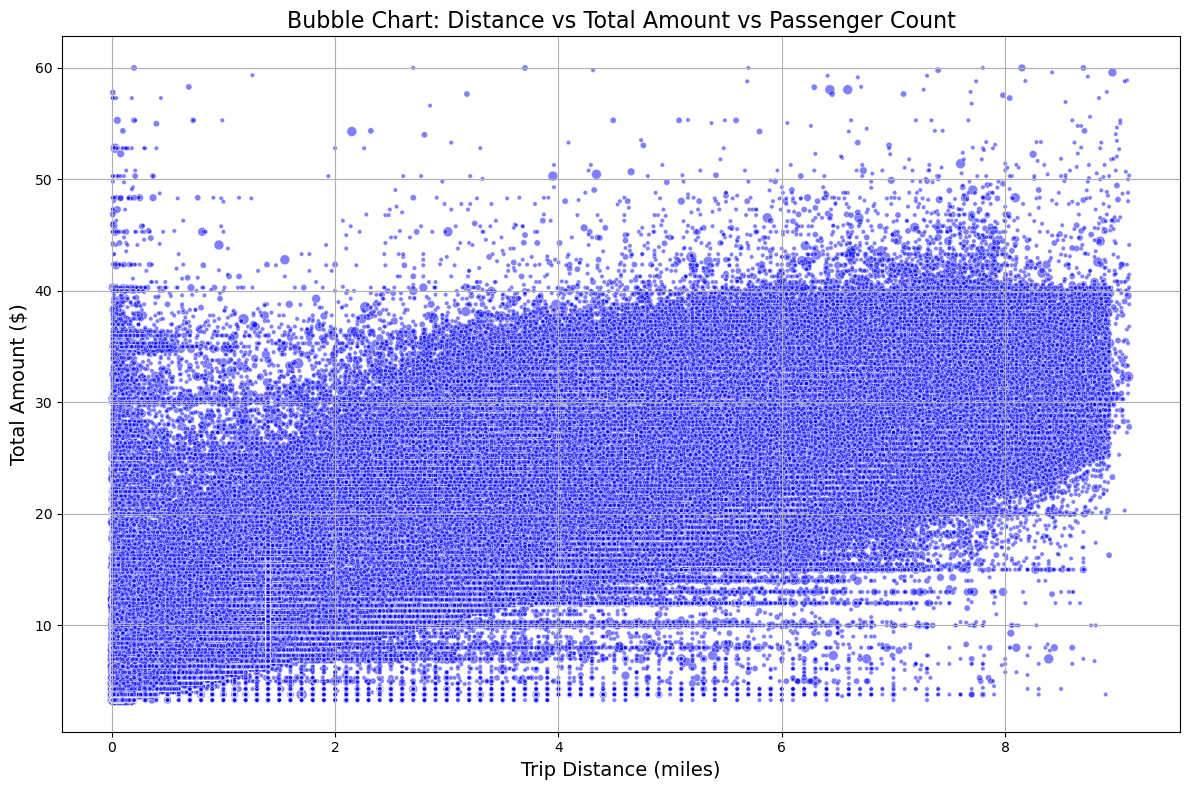
距離(trip_distance)をX軸に、運賃(total_amount)をY軸に、乗客数(passenger_count)をバブルのサイズとしてプロット
# 必要なカラムを選択
df_selected = df.select("trip_distance", "total_amount", "passenger_count") # 必要なカラム 'trip_distance', 'total_amount', 'passenger_count' を選択
# Pandasデータフレームに変換
df_selected_pd = df_selected.toPandas() # SparkデータフレームをPandasデータフレームに変換
# 結果の確認
df_selected_pd.head() # データフレームの最初の5行を表示して確認
# バブルチャートの作成
plt.figure(figsize=(12, 8)) # プロットのサイズを設定
# バブルチャートのプロット
plt.scatter(
df_selected_pd['trip_distance'], # x軸に 'trip_distance' をプロット
df_selected_pd['total_amount'], # y軸に 'total_amount' をプロット
s=df_selected_pd['passenger_count'] * 10, # バブルのサイズを 'passenger_count' に基づいて設定
alpha=0.5, # バブルの透明度を設定
c='blue', # バブルの色を設定
edgecolors='w', # バブルのエッジカラーを白に設定
linewidth=0.5 # バブルのエッジの幅を設定
)
# グラフのラベルとタイトル
plt.xlabel('Trip Distance (miles)', fontsize=14) # x軸ラベルを設定
plt.ylabel('Total Amount ($)', fontsize=14) # y軸ラベルを設定
plt.title('Bubble Chart: Distance vs Total Amount vs Passenger Count', fontsize=16) # グラフのタイトルを設定
# グリッドの追加
plt.grid(True) # グリッドを表示
# 図の表示
plt.tight_layout() # レイアウトを調整して要素間の重なりを防ぐ
plt.show() # 図を表示
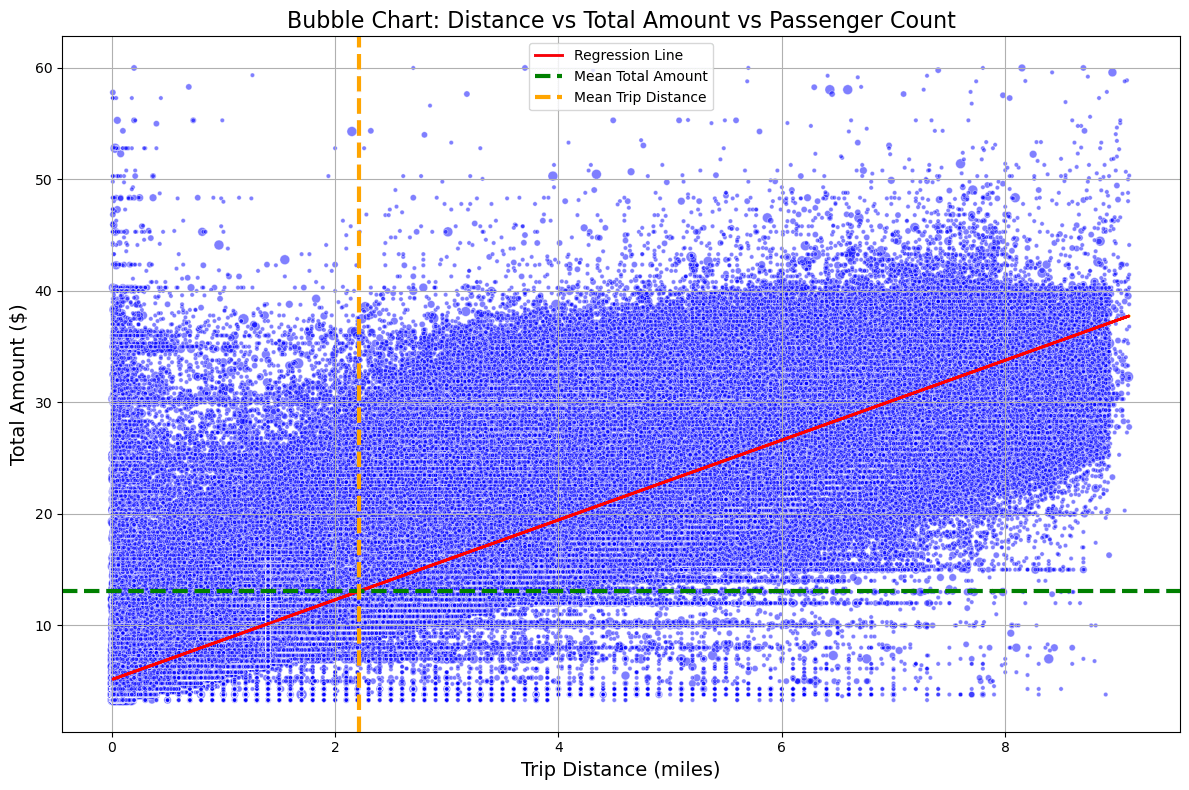
- 補助的な線を追加して、データの傾向をより分かりやすくする
- 回帰直線の追加:データポイントの傾向を示すために、回帰直線を追加。
- 平均線の追加:X軸またはY軸に対して平均値の線を追加。
# バブルチャートの作成
plt.figure(figsize=(12, 8)) # プロットのサイズを設定
# バブルチャートのプロット
plt.scatter(
df_selected_pd['trip_distance'], # x軸に 'trip_distance' をプロット
df_selected_pd['total_amount'], # y軸に 'total_amount' をプロット
s=df_selected_pd['passenger_count'] * 10, # バブルのサイズを 'passenger_count' に基づいて設定
alpha=0.5, # バブルの透明度を設定
c='blue', # バブルの色を設定
edgecolors='w', # バブルのエッジカラーを白に設定
linewidth=0.5 # バブルのエッジの幅を設定
)
# 回帰直線の追加
X = df_selected_pd[['trip_distance']] # 説明変数として 'trip_distance' を設定
y = df_selected_pd['total_amount'] # 目的変数として 'total_amount' を設定
reg = LinearRegression().fit(X, y) # 線形回帰モデルをフィット
y_pred = reg.predict(X) # 予測値を計算
plt.plot(df_selected_pd['trip_distance'], y_pred, color='red', linewidth=2, label='Regression Line') # 回帰直線をプロット
# グラフのラベルとタイトル
plt.xlabel('Trip Distance (miles)', fontsize=14) # x軸ラベルを設定
plt.ylabel('Total Amount ($)', fontsize=14) # y軸ラベルを設定
plt.title('Bubble Chart: Distance vs Total Amount vs Passenger Count', fontsize=16) # グラフのタイトルを設定
# 平均線の追加
mean_total_amount = df_selected_pd['total_amount'].mean() # 'total_amount' の平均を計算
mean_trip_distance = df_selected_pd['trip_distance'].mean() # 'trip_distance' の平均を計算
plt.axhline(mean_total_amount, color='green', linestyle='dashed', linewidth=3, label='Mean Total Amount') # 平均総額の水平線を追加
plt.axvline(mean_trip_distance, color='orange', linestyle='dashed', linewidth=3, label='Mean Trip Distance') # 平均距離の垂直線を追加
# グリッドの追加
plt.grid(True)
# 凡例の追加
plt.legend()
# 図の表示
plt.tight_layout() # レイアウトを調整して要素間の重なりを防ぐ
plt.show()
ニューヨーク市の区画の表示
- %pip installではなく!pip installを使用する
- !pip は、Executor ノードではなく、ドライバー ノードにのみパッケージをインストールします。
- Fabric上でのライブラリの管理はこちらをご参考ください。
!pip install geopandas==0.9.0
!pip install folium
!pip install shapely
import geopandas as gpd
- geopandasは地理空間データの操作に、pandasはデータフレーム操作に、matplotlibはデータの可視化に使用します。
- サンプルデータの読み込み: ニューヨーク市の区画データを読み込みます。GeoPandasは、ニューヨーク市の区画データセット(nybb)を標準で提供しています。
nyc_boroughs = gpd.read_file(gpd.datasets.get_path('nybb'))
# Geopandasのサンプルデータセットからニューヨーク市の区画データを読み込み
# タクシーデータの作成(サンプル)
data = {
"pickup_LocationID": [1, 2, 3, 4, 5],
"latitude": [40.7128, 40.7060, 40.7306, 40.7527, 40.7899],
"longitude": [-74.0060, -74.0086, -73.9352, -73.9772, -73.9730]
}
sampledf = pd.DataFrame(data) # サンプルのタクシーデータを作成
# GeoDataFrameの作成
gdf = gpd.GeoDataFrame(sampledf, geometry=gpd.points_from_xy(sampledf.longitude, sampledf.latitude)) # タクシーデータをGeoDataFrameに変換
# CRS(座標参照系)の設定
gdf.set_crs(epsg=4326, inplace=True) # 座標参照系をEPSG:4326に設定
# 地図のプロット
fig, ax = plt.subplots(figsize=(10, 10)) # プロットのサイズを設定
# ニューヨーク市の区画データを色分けしてプロット、凡例を左上に配置
nyc_boroughs.plot(ax=ax, column='BoroName', legend=True, legend_kwds={'loc': 'upper left'})

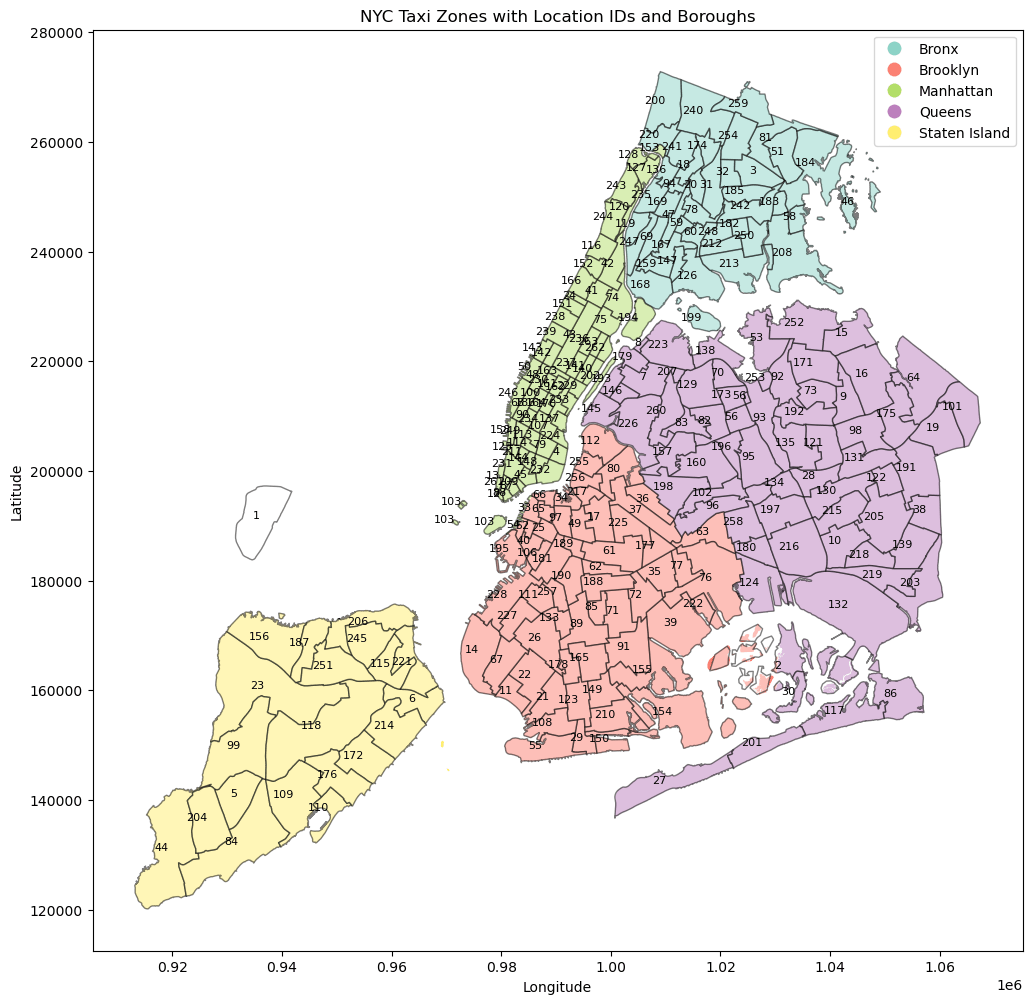
- 地図上にLocationIDも追加する
- 地図情報はNYC TLCで提供されている
# シェープファイルのURL
url = "https://d37ci6vzurychx.cloudfront.net/misc/taxi_zones.zip" # シェープファイルが格納されているURL
# ダウンロード先のパス
zip_path = "/lakehouse/default/Files/taxi_zones.zip" # シェープファイルを保存するローカルのパス
# シェープファイルのダウンロード
response = requests.get(url) # URLからシェープファイルをダウンロード
with open(zip_path, "wb") as f: # ダウンロードしたデータをファイルに書き込む
f.write(response.content)
# シェープファイルの解凍
with zipfile.ZipFile(zip_path, 'r') as zip_ref: # ダウンロードしたZIPファイルを開く
zip_ref.extractall("/lakehouse/default/Files/taxi_zones") # 指定したディレクトリに解凍
# 解凍後のシェープファイルのパス
shapefile_path = "/lakehouse/default/Files/taxi_zones/taxi_zones.shp" # 解凍されたシェープファイルのパス
# タクシーゾーンのシェープファイルを読み込み
taxi_zones = gpd.read_file(shapefile_path) # Geopandasを使用してシェープファイルを読み込み、GeoDataFrameに変換
# SparkデータフレームをPandasデータフレームに変換
dim_location_pd = dim_location.toPandas()
# タクシーゾーンのシェープファイルとデータをLocationIDで結合
merged = taxi_zones.merge(dim_location_pd, left_on="LocationID", right_on="LocationID")
# Geopandasのサンプルデータセットからニューヨーク市の区画データを読み込み
nyc_boroughs = gpd.read_file(gpd.datasets.get_path('nybb'))
# プロットのサイズを設定
fig, ax = plt.subplots(figsize=(12, 12))
# 区画データをプロット、背景をライトグレー、境界を黒で表示
nyc_boroughs.plot(ax=ax, color='lightgrey', edgecolor='black')
# 結合されたタクシーゾーンデータをプロット、白色で表示し、境界を黒、透明度を0.5に設定
merged.plot(ax=ax, color='white', edgecolor='black', alpha=0.5)
# タクシーゾーンの中心にLocationIDを表示
for x, y, label in zip(merged.geometry.centroid.x, merged.geometry.centroid.y, merged['LocationID']):
ax.text(x, y, label, fontsize=8, ha='right', color='black') # テキストラベルを追加
# グラフのタイトルとラベル
plt.title('NYC Taxi Zones with Location IDs') # グラフのタイトルを設定
plt.xlabel('Longitude') # x軸ラベルを設定
plt.ylabel('Latitude') # y軸ラベルを設定
plt.show()

# Geopandasのサンプルデータセットからニューヨーク市の区画データを読み込み
nyc_boroughs = gpd.read_file(gpd.datasets.get_path('nybb'))
# プロットのサイズを設定
fig, ax = plt.subplots(figsize=(12, 12))
# ニューヨーク市の区画を色分けしてプロット
# 区画データをBoroNameごとに色分けしてプロット、凡例を右上に配置、カラーマップを'Set3'に設定
nyc_boroughs.plot(ax=ax, column='BoroName', legend=True, legend_kwds={'loc': 'upper right'}, cmap='Set3') #
# 結合されたタクシーゾーンデータをプロット、白色で表示し、境界を黒、透明度を0.5に設定
merged.plot(ax=ax, color='white', edgecolor='black', alpha=0.5)
# LocationIDのラベルを追加
for x, y, label in zip(merged.geometry.centroid.x, merged.geometry.centroid.y, merged['LocationID']): # タクシーゾーンの中心にLocationIDを表示
ax.text(x, y, label, fontsize=8, ha='right', color='black') # テキストラベルを追加
# グラフのタイトルとラベル
plt.title('NYC Taxi Zones with Location IDs and Boroughs') # グラフのタイトルを設定
plt.xlabel('Longitude') # x軸ラベルを設定
plt.ylabel('Latitude') # y軸ラベルを設定
plt.show()
乗客数が多いpickupエリアtop 10を地図上に表示
# ピックアップ地点ごとに乗客数を集計
passenger_counts = df.groupBy("pickup_LocationID").agg(sum("passenger_count").alias("total_passenger_count"))
# 乗客数が多い上位10のピックアップ地点を取得
top_10_pickup = passenger_counts.orderBy(col("total_passenger_count").desc()).limit(10)
top_10_pickup_pd = top_10_pickup.toPandas() # SparkデータフレームをPandasデータフレームに変換
dim_location_pd = dim_location.toPandas() # SparkデータフレームをPandasデータフレームに変換
# シェープファイルとトップ10データを結合
merged = taxi_zones.merge(top_10_pickup_pd, left_on="LocationID", right_on="pickup_LocationID") # シェープファイルと乗客数トップ10のデータを結合
# Geopandasのサンプルデータセットからニューヨーク市の区画データを読み込み
nyc_boroughs = gpd.read_file(gpd.datasets.get_path('nybb'))
# 地図のプロット
fig, ax = plt.subplots(figsize=(14, 14)) # プロットのサイズを設定
# ニューヨーク市の区画を色分けしてプロット
nyc_boroughs.plot(ax=ax, column='BoroName', legend=True, legend_kwds={'loc': 'upper right'}, cmap='Set3') # 区画データをBoroNameごとに色分けしてプロット、凡例を右上に配置、カラーマップを'Set3'に設定
# タクシーゾーンデータをプロット、ライトグレーで表示、境界を黒、透明度を0.3に設定
taxi_zones.plot(ax=ax, color='lightgrey', edgecolor='black', alpha=0.3)
# バブルのサイズを乗客数に基づいて設定
sizes = merged['total_passenger_count'] / merged['total_passenger_count'].max() * 3000
# バブルチャートのプロット
sc = ax.scatter(merged.geometry.centroid.x, merged.geometry.centroid.y, s=sizes, color='dodgerblue', alpha=0.6, edgecolor='k', linewidth=1.5)
# LocationIDのラベルを追加
for x, y, label in zip(merged.geometry.centroid.x, merged.geometry.centroid.y, merged['pickup_LocationID']): # 各ピックアップ地点にLocationIDを表示
ax.text(x, y, label, fontsize=12, ha='center', color='darkred', weight='bold', bbox=dict(facecolor='white', alpha=0.5, boxstyle='round,pad=0.3')) # テキストラベルを追加
# グラフのタイトルとラベル
plt.title('Top 10 NYC Taxi Pickup Locations by Passenger Count', fontsize=16, weight='bold') # グラフのタイトルを設定
plt.show()

まとめとTips
- データ分析の高度な手法を用いてデータからインサイトを得る方法について解説しました。
- 曜日や時間帯ごとの乗客数の視覚化、エリア間の移動パターンの解析、平均速度の算出、距離と運賃の関係の分析などを取り上げています
- ニューヨーク市の地図データを活用し、乗客の多いエリアを特定して視覚的に表示する方法も紹介しています。これにより、データから得られるインサイトを効果的に抽出することができます
- 可視化する図が多いとnotebookのロード時間が長くなるため、適度にnotebookを分けることをお勧めします。
最後に
- Microsoft Fabricを使用してメダリオンアーキテクチャの実装を行いました。
- 文字数制限の8万文字に達してしまったので、今回はここまでとします。
- PowerBIレポートと機械学習もいつか書きたいと思います。
Discussion