🌝
discordで講義レジュメを管理・要約する。



大学の講義を効率的にサボるツールをdiscordを使って作成します。
概要
pythonオンリーでdiscord botを作成してみました。要約に使ったLLMはGPT4oです。
discord botの作成方法については言及しません。
この記事に影響を受けました。↓
なぜdiscordで管理するのか
- 私がゲーマーのため基本的にファイルやデータの共有はdiscordで済ませたい。
- 周りの友人とのメインコミュニケーションツールがdiscordだった。
- またdiscordはSlackやLineと違い保管期限が無い。
実際のコード
import discord
import openai
import os
import fitz # PyMuPDF for PDF
from pptx import Presentation
from docx import Document
from dotenv import load_dotenv
#環境変数を読み込む
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
DISCORD_TOKEN = os.getenv("DISCORD_TOKEN")
#Discord Intents 設定
intents = discord.Intents.default()
intents.message_content = True
client = discord.Client(intents=intents)
#ファイル形式別のテキスト抽出関数
def extract_text_from_pdf(file_bytes):
with fitz.open(stream=file_bytes, filetype="pdf") as doc:
return "\n".join([page.get_text() for page in doc])
def extract_text_from_docx(file_bytes):
with open("temp.docx", "wb") as f:
f.write(file_bytes)
doc = Document("temp.docx")
os.remove("temp.docx")
return "\n".join(p.text for p in doc.paragraphs)
def extract_text_from_pptx(file_bytes):
with open("temp.pptx", "wb") as f:
f.write(file_bytes)
prs = Presentation("temp.pptx")
os.remove("temp.pptx")
text = ""
for slide in prs.slides:
for shape in slide.shapes:
if hasattr(shape, "text"):
text += shape.text + "\n"
return text
#Discordイベント:メッセージ受信時
@client.event
async def on_message(message):
if message.author.bot:
return
if message.attachments:
try:
attachment = message.attachments[0]
filename = attachment.filename.lower()
file_bytes = await attachment.read()
# 拡張子によって処理を分岐
if filename.endswith(".txt"):
text = file_bytes.decode("utf-8")
elif filename.endswith(".pdf"):
text = extract_text_from_pdf(file_bytes)
elif filename.endswith(".docx"):
text = extract_text_from_docx(file_bytes)
elif filename.endswith(".pptx"):
text = extract_text_from_pptx(file_bytes)
else:
await message.channel.send("対応しているファイル形式は .txt, .pdf, .docx, .pptx です。")
return
# プロンプト作成
prompt = f"以下の文章を要約し、日本語に翻訳してください:\n\n{text}"
# OpenAI Chat API を使用(新API対応)
response = openai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは優秀な翻訳者であり要約者です。"},
{"role": "user", "content": prompt}
],
temperature=0.5,
max_tokens=800
)
result = response.choices[0].message.content.strip()
# スレッドで結果を返信
thread = await message.create_thread(name="要約・翻訳結果")
await thread.send(result)
except Exception as e:
await message.channel.send(f"エラーが発生しました: {e}")
#Bot起動
client.run(DISCORD_TOKEN)
結果
手頃なレジュメがなかったのでGoogle ScholarでLLMと検索しヒットした論文の中でトップにきたもので試してみます。
ファイルを送信したのち10秒ほどで応答しました。

要約結果がこちらです。
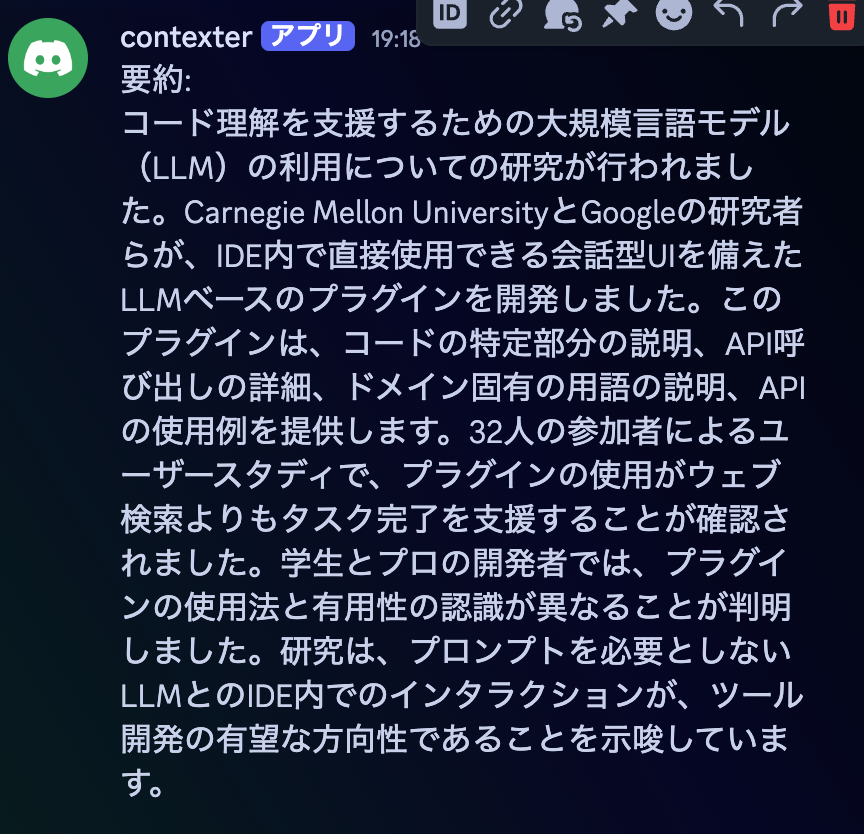

要約はGPT4oが行ってるのでそこまで気にならないですね。
気になった事

やりすぎるとスレッドの表示が増えていっちゃうかも?
今後の展望
- awsかなんかの無料のクラウドサービスを使ってもっと使いやすくする。
- LLMのモデルで他にいいものを探す。→教えてください。
- プロンプトを変える。
以上ありがとうございました。
Discussion