Datastream を知らずに今年は終われない
みなさま、こんにちは。
Google Cloud Champion Innovators Advent Calendar 2023 の 21 日目の記事です。
今年もGoogle Cloudは色々なアップデートがありました。
例えば 2023 年 04 月 04 日の更新では、Datastream の PostgreSQL からのデータ抽出と、BigQuery へのデータ反映が一般提供になりました。
これにより、Datastream は RDBMS と BigQuery を繋ぐ時のいちばん簡単な方法として、おすすめできる存在になりました。
そこで、Datastream とは何か、またその設置の時に気をつけなければいけない点は何かを紹介したいと思います。
よくあるデータパイプラインとその問題点
読者の皆様は、RDBMS のデータを分析する時に、データを データウェアハウス (DWH) に転送し、分析をしているものと思います。
通常、RDBMS からデータ分析用のデータ基盤にデータを反映させるときには、定期的なバッチにより CSV や Avro、Parquet などの形式で、ファイルの形でデータを抽出し、データ基盤に転送して反映させることが多いでしょう。

図1 よくあるデータパイプラインの像
この構成には、いくつか問題があります。
まずデータを抽出する元になる RDBMS に、負荷がかかります。通常のクエリと同じようにクエリを発行してデータ抽出を行うので、データ量によってはかなりな負荷がかかり、オンラインの処理が遅延することもあるでしょう。
その影響を避けるため、負荷が下がる深夜時間帯にバッチ処理でデータ転送を行うという対処も多く見受けられます。この方式ならば、確かに負荷による問題は出にくくなります。しかし、今度はデータの鮮度、つまり反映までの時間が長くなってしまい、新鮮なデータでの情報分析ができない問題が発生します。データに基づいて素早い判断が企業の競争優位に繋がると言われている現在、これは割りと大きな問題でしょう。
Datastream とは何者か?
Datastream とは、RDBMS をデータの読み取り元として、データレイクもしくはデータウェアハウスに、ストリーミングで、ほぼリアルタイムに反映させるサービスです。また Datastream は、サーバレスです。
バッチでデータを転送する時の色々な問題を、これ一つで解決するサービスであると行っても過言では有りません。

図2 Datastreamを使った場合のデータパイプラインのイメージ
データは、RDBMS から Change Data Caputure (CDC) で取得します。CDC は、変更差分をトランザクションのログから変更差分を取得する仕組みです。この CDC を使って転送しますので、データ取得時に RDBMS に負荷をかけない仕組みが実現できます。
Datastream はサーバレスですので、サーバの管理をする必要がありませんし、データの量に応じて自動でスケールします。
更に、Datastreamは転送元と転送先の設定があればデータ転送が実現できるため、転送バッチをコーディングする必要がありません。
転送するデータはテーブル単位で取捨選択できます。
転送先を BigQuery に定めた場合、データ型はソースデータのデータ型に合わせて転送できます。
現在対応している RDBMS は、MySQL、PostgreSQL、Oracle になります。対応バージョンは、それぞれのリンク先のドキュメントで確認ください。もし、利用しているRDBMSがこの範囲であるならば、バッチで悩んでいた部分が一通り解決できます。
Datastream のアーキテクチャ
このように至れり尽くせりのDatastreamの構成はどうなっているのでしょうか?
ここからは図の簡素化を目的として、データの保管先をBigQueryに限定して説明します。

図3 Datastream のアーキテクチャ概念図
Datastreamを利用してデータ転送を実現するために必要なDatastreamの構成要素は4つです。
- RDBMS と接続するためのネットワークを設定する Private Connectivity
- データのソースであるRDBMSと接続するための Connection Profile
- データの保存先と接続するための Connection Profile
- そしてこの接続設定を使ってデータを転送する部分を担う Stream
なんと、たったこれだけです。
これらで、データソースを認識し、データ転送先を認識し、データ転送の開始、停止、再開を制御することができます。
設定自体については、ここでは細かく解説しませんので、リンク先のそれぞれのドキュメントを見てください。
Datastream のネットワーク
Datastreamの設定はこれだけですが、追加で考慮するべきはネットワークです。
Public IPで接続する場合は、IPの許可リストに登録するべきIPが出ますので、RDBMS 側のネットワークとして許可リストを作成し、接続元を制限するだけで事足りるでしょう。
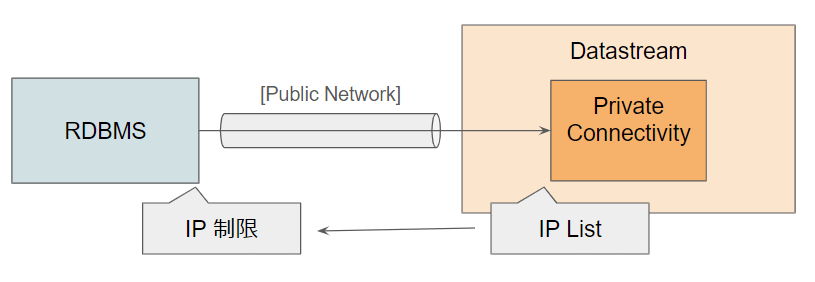
図4 Public IP接続ならば、IP制限さえかければよし
しかし、多くの用途ではPrivate IPでの接続を第一に考えたくなるものかと思います。
Private接続で問題になってくるのは、リクエストの流れです。データの流れとしては、ソースのデータベースから流れてくる図になるのですが、リクエストの流れとしてはここが逆になっています。
DatastreamはVPCに対して VPC Network Peeringで接続します。接続先は主に Cloud SQL と オンプレミスネットワーク上の RDBMS の 2 パターンになるかと思います。
オンプレミスネットワーク上の RDBMS に接続する場合で、Private IP で接続するならば、 VPN もしくは Interconnect を通しての接続になるでしょう。この時、ネットワーク情報の交換には Cloud Router を使いますが、デフォルトではここには Peering 接続をした Datastream の情報はありません。そこで、Cloud Router に Custom Route 設定を施し、Datastream のネットワークを交換する必要があります。

図5 オンプレミスネットワークへの接続 ※IPはサンプル
同一プロジェクト上の Cloud SQLですが、こちらは少し厄介です。
Cloud SQL は、VPC Network Peering で VPC Network にプライベート接続します。Datastream もVPC Network Peering をしているので、推移的接続の禁止というルールにより Datastream からの Cloud SQL のネットワークアドレスの解決ができません。

図6 Cloud SQL への接続
この問題は、VPC Network 上にアドレスの解決ための Compute Engine VM インスタンスによる Reverse Proxy を作成することで解決できます。

図7 Reverse Proxy を設置した時の図
まとめ
Datastream とその接続方法を紹介しました。
簡単かつスケーラブルにデータのパイプラインを構築するツールとして、Datastream はこれから大きく羽ばたいていくと考えています。
ぜひ、今年は Datastream を覚えて頂き、来年は大いに Datastream でデータパイプラインを簡素化して、リアルタイムにデータを分析していきましょう!
Discussion