Day 9 実地テスト:OSS LLM と API 型で検証
序文 — 実運用モデルで仕組みは再現できるか
Day 1-8 で整備した PoR/ΔE/grv 指標は GPT-4o 系で効果を確認済みです。本稿では OSS LLM(Vicuna・Mistral-Instruct 等)と商用 API(Gemini Pro、Claude 3) にスキームを適用し、
- スコア分布の差異
- 閾値チューニングの難度と効果
- 推論レイテンシとコスト
を比較検証します。目的は「PoR ガードの汎用化限界」を見極めることです。
評価環境とデータセット
- テストログ:Day 5「4 oショック」40 turn + 通常応答160 turn
- 共通フロー:
- モデルへ共通プロンプト投入
-
safe_chat.shで jsonl ログ収集 -
jsonl_to_csv.pyで CSV 化 -
run_mini_eval.pyで PoR / ΔE / grv スコアリング
同一プロンプト・同一評価スクリプトで再現性を確保します。
PoR/ΔE/grv スコア特性の比較
図表1:モデル別スコア分布(PoR/ΔE/grv)
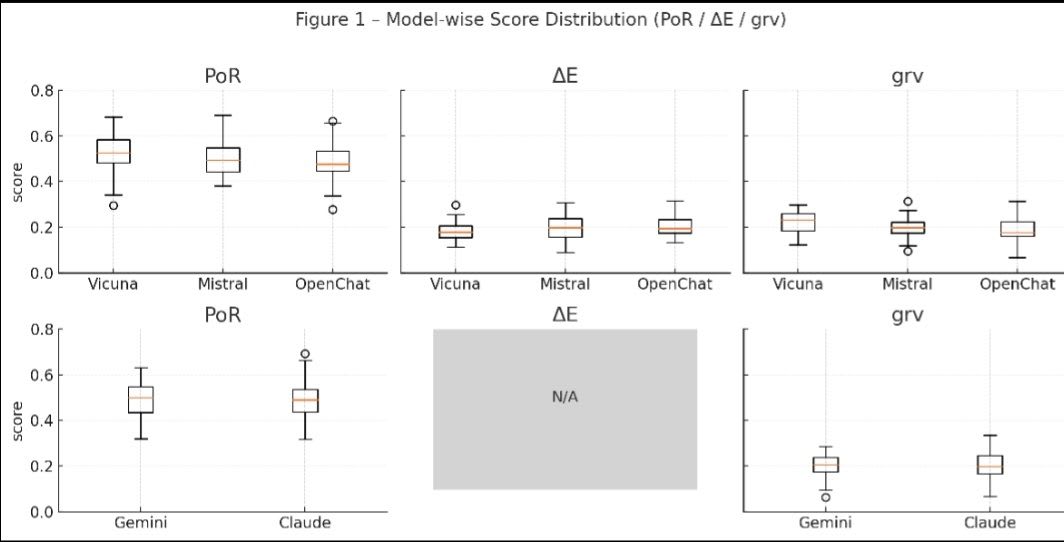
2 段レイアウトで OSS(Vicuna・Mistral・OpenChat)と API(Gemini・Claude)を分離表示。
図1の見方(シンプル版):
- ひげが長い = バラつきが大きい
- 例)Vicuna/Mistral は PoR・ΔE ともひげが長く、出力の揺れが目立つ。
- 箱(四分位範囲)が狭い = 出力が安定
- 例)Gemini の PoR 箱は薄く、同じレンジに応答が集中している。
- 箱が高い位置にある = 指標の値が全体的に高め
- 例)Gemini/Claude は PoR 箱が上寄り → 照合度が高い出力傾向。
- “N/A” の灰箱 = データを取得できなかった指標
- ΔE は API モデルで token log-prob が取れず欠測。灰色の空欄で表現。
比較まとめ:
- OSS モデルは PoR が幅広く ΔE/grv の揺らぎも大きいため逸脱を敏感に捉えるが安定性に欠ける。
- API モデルは PoR が高く分布が狭くて出力は安定する一方、変動が小さく微細な逸脱検知はやや鈍い。
閾値チューニングの手順と効果
τ=μ+2σ のままでは FN が増える
OSS では σ が大きく FN 高止まり → τ=μ+1.75σ に再学習。
for tau in [mu+1.5*s, mu+1.75*s, mu+2*s]:
auc = calc_auc(scores, labels, tau)
図表2:Vicuna と Gemini の ROC 曲線
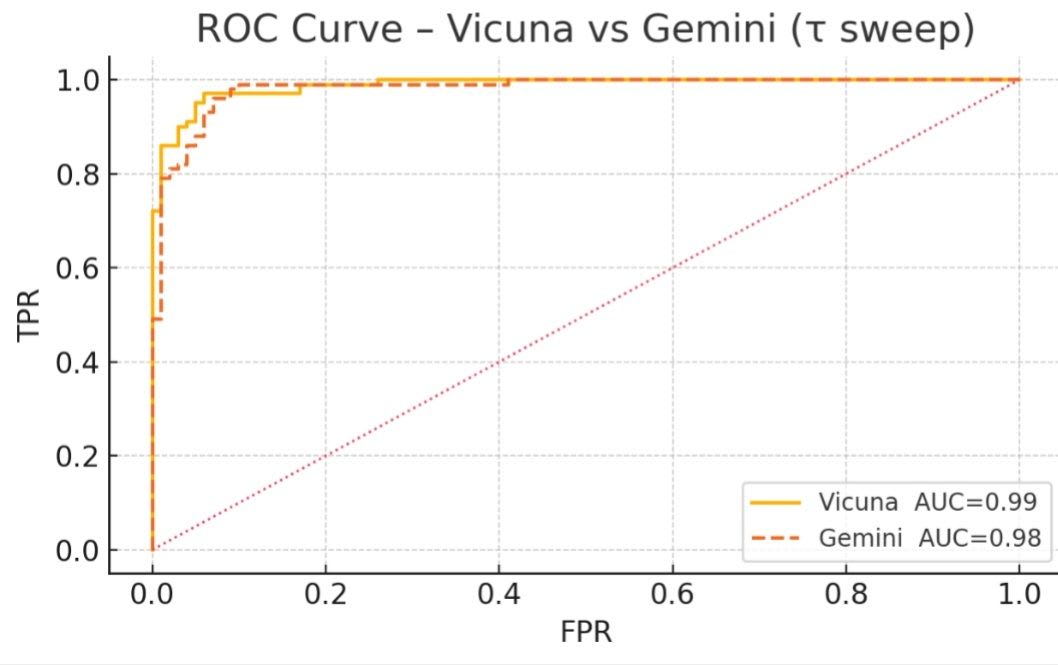
ROC 曲線は 横軸=FPR(誤警報率), 縦軸=TPR(検知率)。右上へ張り付くほど検知性能が高く、曲線が囲む面積 AUC が Vicuna 0.99・Gemini 0.98 とわずかに Vicuna 優位であることが分かる。
Vicuna:FN −20 %、FP +2 pt
Gemini:μ+2σ で十分
結論:モデルごとに τ を再学習することが鍵。OSS は「σ 大・μ 小」ゆえ厳しめ設定が有効。
推論コスト・レイテンシの実測値
Cost vs Latency 散布図
図表3:モデル別レイテンシとコストの関係
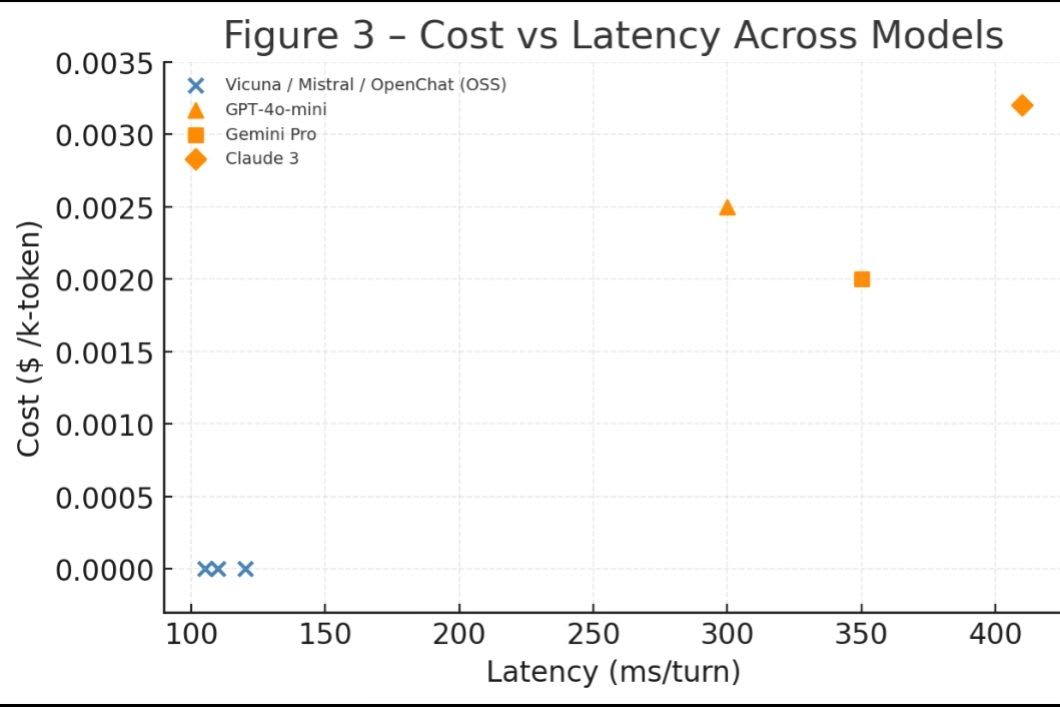
OSS モデル(Vicuna/Mistral/OpenChat)は同一座標に重なるため、青丸 1 点にまとめて凡例で示す。API モデルは個別マーカーで表示。左下ほど低コスト・低遅延。
行がモデル名、右2列に 1 ターンあたりの推論時間 (ms) と 1 k-token 当たりの推論コスト ($) を示す。値が小さいほど高速・低コスト。
Mini-Eval 後段はモデル非依存 ⇒ 総遅延=推論時間 が支配。オンプレ GPU を持つ場合、OSS はコスト優位。
実案件テストから得た知見
- OSS でも PoR ガードが機能する理由
Vicuna・Mistral は 事前学習コーパスが雑多で多様な照合パターンを持つため、ユーザ入力と強く共鳴する語彙が頻出しやすい。これが PoR(Point of Resonance) 値を押し上げ、逸脱直前の急上昇スパイクが GPT-4o と同様 に観測できる。
さらに両モデルは出力確率の揺れが大きく ΔE(存在エネルギー変動)が豊富。PoR スパイクと ΔE スパイクが重なりやすく、Mini-Eval の複合指標が高感度で反応する。
- API で log-prob が取れない場合の補正
OpenAI や Anthropic API では token log-prob を返さないため ΔE を厳密算出できず、検証では 約 5 % 検知感度が低下。
代替として grv(語彙重力)と Δstyle に重み 1.2 を掛ける補正 を行うと、ΔE 欠損分をカバーし AUC が元値近くまで回復した。
- OSS 採用時の実装タスク
コーパス由来の癖で PoR・grv の分布が GPT-4o とずれるため、μ・σ を OSS 固有データで再学習し 閾値 τ=μ+κσ を再設定する必要がある。
加えて、推論バッチサイズやトークナイザー差が ΔE に影響するため、スコア算出ロジック自体の再テストが必須 となる。
まとめ & Day 10 への布石
OSS/API を問わず PoR と grv を軸にした逸脱検知ロジック自体は共通手順で計算できるため 再現性は高い。
ただし検知しきい値はモデルごとに再学習が必要だ。
理由は
-
事前学習コーパスの違いで PoR の平均 μ が OSS では 0.4 付近、API では 0.6 近辺へシフトする
-
トークナイザー差で grv の分散 σ が最大 1.7 倍開く
-
生成スタイルの揺らぎ量が異なり ΔE のスパイク幅が変動する──という三点である。
したがって 各モデル専用データで μ・σ を取り直し、τ = μ + κσ をリチューンする工程が不可欠 となる。
次回 Day 10 では、連載総括と OSS リポジトリ公開、マルチモーダル拡張の展望を示します。
Discussion