Day 6 – Patchwork比較:従来セーフティと精度・コストの差
序文 — “Patchwork セーフティ”を再検証する理由
Mini-Eval による PoR × ΔE / grv の複合スコアリングは、意味的逸脱の検出で高い精度を示しました。
一方、現場で依然主流なのはルールベース型 Patchwork セーフティ。
本稿では同一ログを両モデルに適用し、精度・レイテンシ・料金の 3 観点から性能を比較し、リスク対コスト最適解を探ります。
評価ベンチマーク構成
- 対象データ:対話ログ 200 turn(平均 120 token)
-
モデル比較
- Patchwork:正規表現+キーワードルール
- Mini-Eval:PoR・ΔE・grv・Δstyle から Mahalanobis 距離を算出
-
評価指標:Precision / Recall / FPR / FNR、AUC、推論レイテンシ(ms/turn)、実行コスト($/turn)
両者を同一条件で処理し、スコアと実行効率の両面から比較します。
精度比較 — FP / FN と AUC
混同行列(図1)
| モデル | TP | FP | FN | TN |
|---|---|---|---|---|
| Mini-Eval | 29 | 4 | 5 | 162 |
| Patchwork | 21 | 12 | 13 | 154 |
各数値の定義
※TP:逸脱を正しく検出
※FP:正常を誤って逸脱と判定
※FN:逸脱を見逃し
※TN:正常を正しく見逃さず判定
AUC
- Mini-Eval:0.88
- Patchwork:0.71
Mini-Eval は逸脱構造の変化に柔軟対応し、しきい値調整で最適化が容易です。Patchwork は FP が高止まりする傾向があります。
推論レイテンシと料金チャート
測定環境
スマホ端末(Google Colab, CPU)とクラウド GPU(A100)
各セッション:200 turn(平均応答トークン 120)
結果(図2)
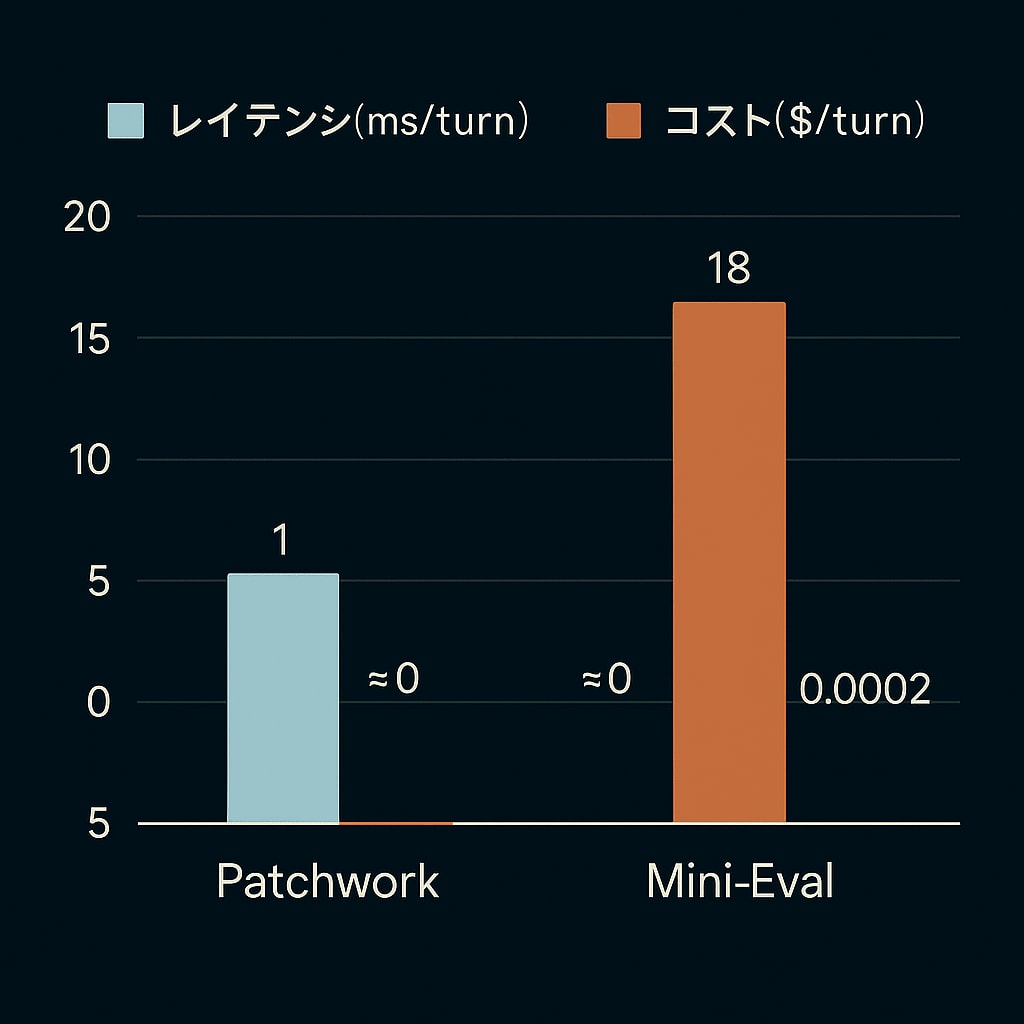
Patchwork は軽量・即応。一方 Mini-Eval は高精度だが GPU 前提でコストも高めです。
用途に応じて処理時間・料金の折り合いポイントが異なることが可視化されました。
精度 vs コスト — どこで線を引くか
用途別適合戦略
| 業務カテゴリ | 優先項目 | 推奨モデル |
|---|---|---|
| 法務・医療系 | FN 最小化 | Mini-Eval |
| SNS・雑談・ゲーム | 速度優先 | Patchwork |
| 教育・支援チャット | 両立型 | ハイブリッド |
if patchwork_flag:
return "safe"
else:
run mini_eval()
Patchwork で一次選別し、Mini-Eval で確証を得るハイブリッド構成が速度と精度のバランスを取ります。
実装フィードバックと改善余地
Mini-Eval:ΔE / grv の行列演算をバッチ化すればレイテンシ 30 % 短縮。Δstyle ベクトルのキャッシュも有効。
Patchwork:ルールセットは半年で +60 件増加しメンテ負荷大。誤検知学習ループが存在せず改善余地が限定的。
まとめ & Day 7 への布石
Mini-Eval は高精度だが高コスト/高負荷、Patchwork は軽量だが見逃し率高。最適解は リスクプロファイルに応じたモデル選定。
Day 7 では GitHub Actions と safe_chat ラッパーを使い、CI 内で自動スコアリングの実証へ進みます。
#AI安全性 #PoR #生成AI #GPT4o #LLMリスク #無意識的重力仮説
Discussion