1つのGPUでも大規模言語モデルを動かせる!FlexGenの革新的な技術とは?
FlexGenとは?
FlexGenは、限られたGPUメモリで大規模な言語モデルを実行するための技術です。従来、大規模言語モデルの推論には高性能なGPU複数使用する必要がありましたが、FlexGenを使用することで1つのGPUでも推論することができます。 FlexGenは、GPU、CPU、SSDを上手く使うことで、限られたVRAMでも大規模な言語モデルを実行することができます。
公式のハードウェア環境は、NVIDIA T4 (16 GB), RAM (208 GB),SSD (1.5 TB) となっていました。
GitHub: https://github.com/FMInference/FlexGen
従来の大規模言語モデルの課題
大規模言語モデル(LLM)の発展に伴い、大量の訓練データや十分に大きなスケールのモデルを使用することが可能になったものの、その反面、必要なハードウェア要件が非常に高いため、現在利用できるのはごく限られたユーザーのみであることが問題となっています。例えば、最も大きなLLMの1つであるBLOOMを実行するためには、352 GB以上のVRAMが必要であり、RTX A6000(48 GB)を8つ使用する必要があります。 このようなハードウェア要件は、LLMを開発および研究する上での大きな課題となっています。
FlexGenの特徴 - 1つのGPUでも大規模な言語モデルを動かせる理由
LLMの推論に必要なリソースを削減することは、近年非常に注目されています。これらの取り組みには3つの方向性があります。FlexGenは、RAMやSSDから必要な部分を読み込み、一部の計算を行うことで、VRAMが限られたデバイスでも実行できるようにしています。
- モデルを圧縮することで、モデル自体のサイズを小さくし、保存に必要なメモリや実行に必要な計算量を少なくする方法
- 推論作業を複数のデバイスやノードに分割し、それらを連携させてより効率的にタスクを完了させる方法
- モデルがVRAMに収まらない場合、RAMとVRAMの間でモデルとデータのチャンクをスワップすることで、LLMを推論する方法
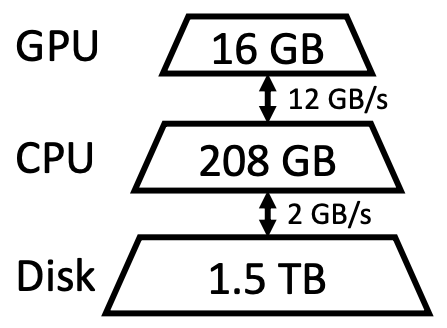
FlexGenの論文より
これまでは、LLMを実行するには、高性能なGPUを複数用意する必要がありました。しかし、FlexGenは、一般的なGPUでもRAMが大量にあれば、実行可能になることが特徴です。FlexGenのような技術により、少ないリソースで効率的にLLMを実行することが可能となり、より手軽にLLMを利用できるようになることが期待されています。
FlexGenの性能 - 対応しているLLMの種類と必要スペック
有名なLLMとして、GPT-3があります。GPT-3はOpenAIが開発しており、パラメーターは175Bであり、複数の言語で質問に答えたり、文章を要約したりすることができます。しかし、モデルの訓練コストが高いため、研究機関でなければ作ることができません。GPT-3はAPIとして利用できますが、モデル自体は公開されていないため、利用が容易ではありません。
それに対して、いくつかのプロジェクトが大規模言語モデルを開発し無料で公開しています。例えば、MetaはGPT-3を再構築してOPT(Open Pretrained Transformer)を開発し、無償で提供しています。パラメーターは125Mから175Bのものがあります。Hugging Faceは、1000人を超えるAI研究者にと共に、BLOOMを開発し、公開しています。パラメーターは176Bとなっています。
現在、FlexGenはLLMの中でも、OPTに対応しています。 ただし、OPTの中で最大のモデルは研究者向けに公開されているため、一般向けに公開されている少し小さいモデル利用することになると思います。
FlexGenは、複数のハイスペックGPUを必要とせず、一般的なGPUでも利用できます。ただし、大量のRAMが必要となるため、注意が必要です。 現在でも開発が進められており、今後のアップデートに期待されています。公式のハードウェア環境は、NVIDIA T4 (16 GB), RAM (208 GB),SSD (1.5 TB) となっていました。
特に、Hugging FaceのBLOOMは多言語に対応したLLMであり、一般公開されているモデルです。そのため、BLOOMへの対応が今後の重要なポイントになると思われます。
Google Colabを利用したデモの手順
Google Colabでも、FlexGenを使ってOPTを動かすことができます。ただし、最初に言っておくと無料版はRAMが少ないため一番小さいモデルしか動作を確認することができませんでした。
インストール
このような技術は比較的インストールなどが難しいことが多いのですが、FlexGenは簡単に使うことができます。
!git clone https://github.com/FMInference/FlexGen.git
!cd FlexGen
!pip3 install -e .
一番小さいモデルで動作確認
!python3 -m flexgen.flex_opt --model facebook/opt-125m
tensorflow のエラーが出る場合は
!pip install -U tensorflow==2.9.2で治るかもしれません。
一番小さいモデルでチャットボット起動
!python3 apps/chatbot.py --model facebook/opt-125m
それ以外のモデル
OPTはOPT-125M, OPT-350M, OPT-1.3B, OPT-2.7B, OPT-6.7B, OPT-13B, OPT-30B, OPT-66B, OPT-175B が公開されているのですが、無料版はRAMが12.68 GBと少ないため一番小さいOPT-125Mしか動作を確認することができませんでした。ちなみに、 次に大きいOPT-350M このモデルはアーキテクチャが異なるため、実装されていません となってしまいます。GitHubでは、「OPT-1.3Bのような小さいモデルから試してみましょう」となっているのですが、RAMが足りずに動作しませんでした。VRAM的には問題ないと思うのですが…
この辺りの問題は、今後のアップデートで改善されることを期待しましょう!
Colab Pro版では、ハイメモリを選択することでRAMが83.48 GBまで増やすことができるので、OPT-1.3B, OPT-6.7B を動かすことができます。 OPT-6.7Bくらいから質問にちゃんと回答してくれるようになります。
GitHubによると、OPT-30BとチャットするにはRAMが90 GBほど必要になるそうです。オプションを組み合わせることで、Colab Pro版で動かしている例を見つけましたが、ダウンロードに非常に時間がかかるようです。
参考資料
Discussion