Parquet形式とは
今回はデータ形式のParquetについて解説します。
Parquet形式とは
Parquet形式は、大規模なデータファイルに使用されるフォーマットの一つであり、以下の構成要素を持ちます。
- ファイルヘッダー
ファイルがParquet形式であることを示す - メタデータ
データセットのスキーマ情報(カラム名、データ型など)、各列のデータ詳細(圧縮タイプ、エンコーディングなど)を示す。これによりデータへのアクセス方法が分かる - データブロック(行グループ)
データ本体。列方向に複数の行グループに分割されて保存されている。例えば1000行のデータであれば、5つの200行を内包する行グループに分けることができる。各行グループに対してメタデータが存在する
データブロックの確認
具体的にデータ形式をイメージするために、データ本体の構造について見ていきましょう。
# 時間、周波数、振幅
#行グループ1
[[0.0 , 5.0, 0.],
[0.01, 5.0, 0.30901699],
[0.02, 5.0, 0.58778525],
[0.03, 5.0, 0.80901699],
[0.04, 5.0, 0.95105652]]
#行グループ2
[[0.05, 5.0, 1.0],
[0.06, 5.0, 0.95105652],
[0.07, 5.0, 0.80901699],
[0.08, 5.0, 0.58778525],
[0.09, 5.0, 0.30901699]]
#行グループ3
...
このように、テーブルデータを列方向に分割したようなデータ形式がParquet形式です。
またParquetデータへのアクセスは列方向で行われます。
例
・行グループ1の時間列を取得→「0.0, 0.01, 0.02, 0.03, 0.04」
・行グループ2の振幅列を取得→「1.0, 0.95105652, 0.80901699, 0.58778525, 0.30901699」
可視化
では、上記のデータの行グループ1,2から「時間」列と「振幅」列を抜き出してプロットしてみましょう。
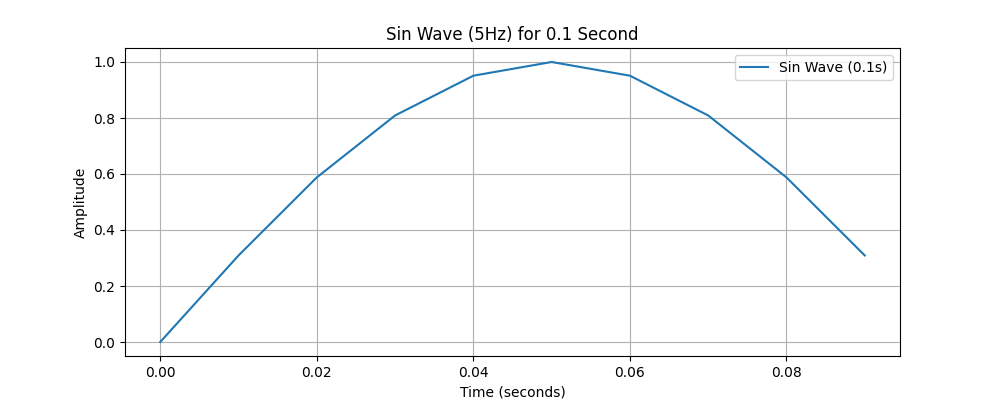
このように、特定の列を抜き出して関係を見ることができます。
メリット
Parquet形式では、列方向のアクセスと、行グループによって大規模なデータを効率的に扱うことができます。
-
列方向アクセス
Parquetは列方向でデータへのアクセスを行います。(MySQLやOracleDatabaseは行方向アクセス)従って、クエリ実行時に行方向に全ての列データを読み込むのではなく、クエリに必要な列だけを読み込むことで、I/Oの負荷を減らし、パフォーマンスを向上させます。
このアクセス方式は、大規模なデータセットを扱うデータ分析などのタスクに有効です。
例:特定の列と列[年齢と身長]の関係を知りたい時など -
行グループ
Parquetファイルは行グループによって、データが列方向に区切られています。このため大規模なデータセットでは、行グループごとに分散して分析を行うことができます。また特定のグループのみを抜き出すこともできるため、より効率的にデータを扱うことができます。
まとめ
Parquet形式は、行グループを持つ列方向のデータ形式であり、効率的なデータ操作を可能にします。データが大規模になるほど、そのメリットは大きくなるでしょう。
今回はここまでになります。最後まで読んでいただきありがとうございました。
Discussion