【Kaggle】RNSA 2022 1st place solution explained
This time, I explain the 1st solution of RNSA 2022 competition.
1. Goal of the competition
Rapid detection and location of spinal fractures from CT images.
2. Solution Summary
The code:
Used 2-stage learning.
・stage1: 3D semantic segmentation
・stage2: 2.5D w/ LSTM classification
In addition, there are 2 different types of classification models in stage2.
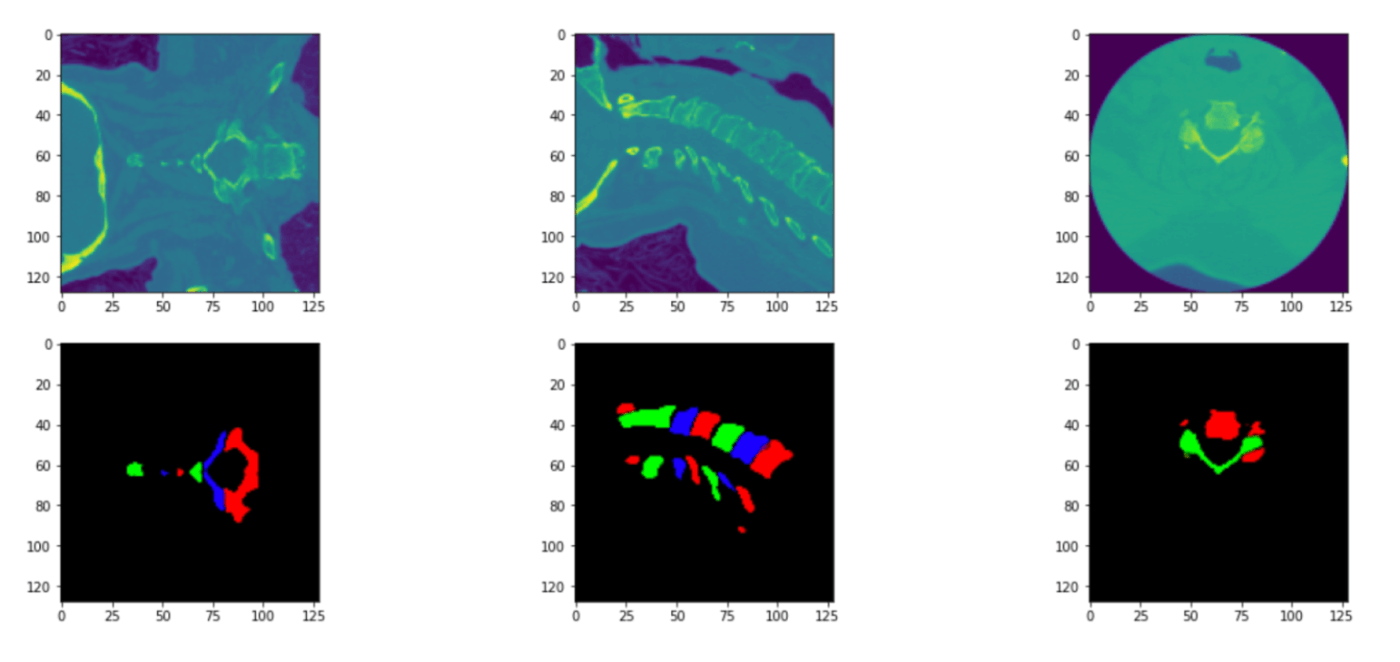
3. 3D Semantic Segmentation
For 3D semantic segmentation, there are only 87 samples w/3d mask in the dataset, but it's sufficient to train 3D semantic segmentation with good performance.
Details
・Input: 128x128
・Model: resnet18 or efficientnet v2s + unet
・Output: C[1-7] vertebraes, 7ch
Training the model, and predict 3D masks for each vertebrae for all 2k samples in training set.
・Mask examples
4. Prepare Data for Classification
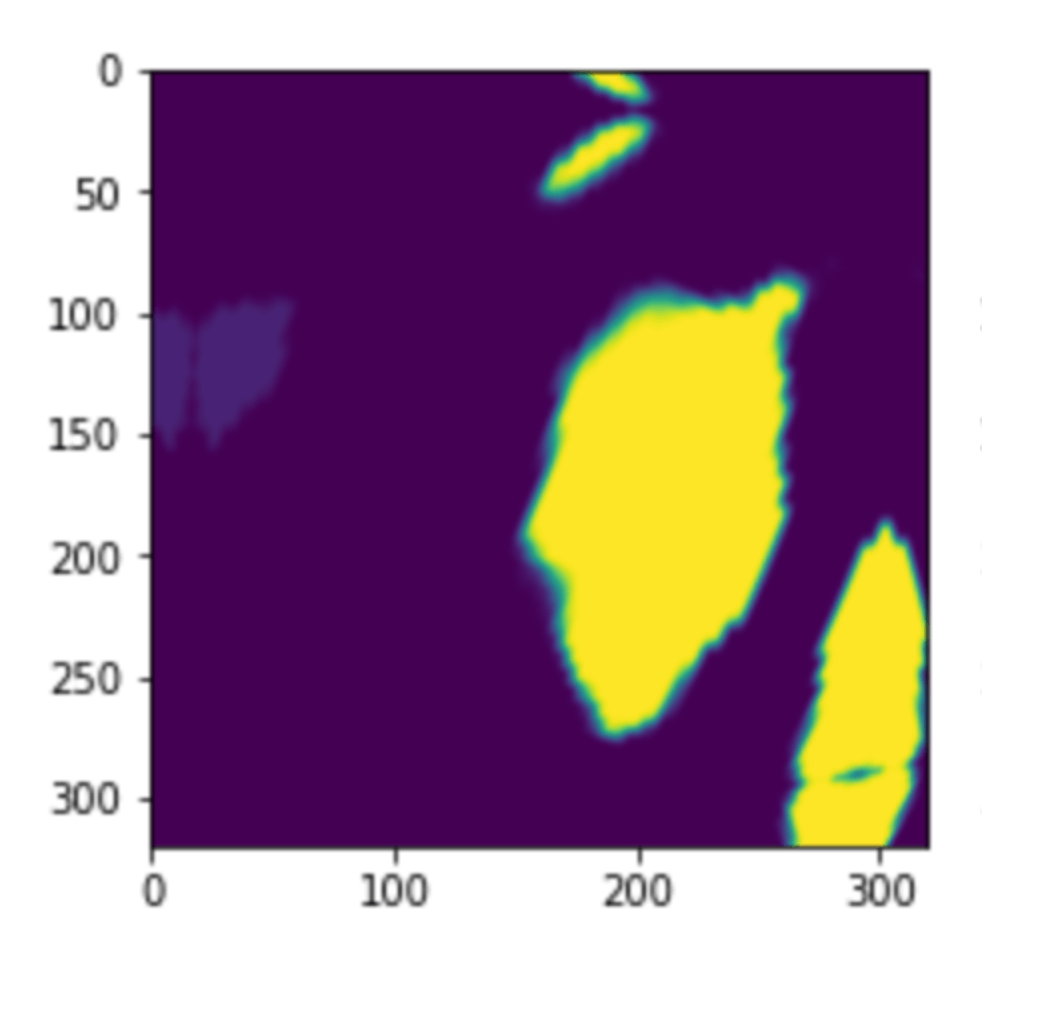
Cropping out 7 vertebraes from a single original 3d image. At this moment, he get the 2k x 7 = 14k samples
Then for each vertebrae sample, he extarcted 15 slices evenly by z-fimension.
Further he extracted +-2 adjust slices to form an image with 5 channels. E.g if a 3D vertebrae sample have a shape of (128, 128, 30), I extracted 0th, 2nd, 4th, 6th….26th, 28th slices, then for example for the 2nd one, I use 0th~4th slices to form a 5-channel image.
So a single sample becames to 15 x 5 channel data.
In addition, he added the predicted mask of corresponding vertebrae as the 6th channel to each image, as a way to exclude the effect of having multiple vertebraes in a single sample.
What a smart!
・Example of one slice of a single vertebrae, and its predicted mask (with augmentations).

5. 2.5D + LSTM Classification
Simple 3D CNN doesn't work for him. So it is written 2.5D, but the model is a normal 2D CNN with 5-channels input.
He created 2 type of model.
- 15 slices as input
2DCNN extract 512 dim features from each 15 slice, and LSTM learn the features CNN outputted. So that the whole model can learn the features of the whole vertebrae.
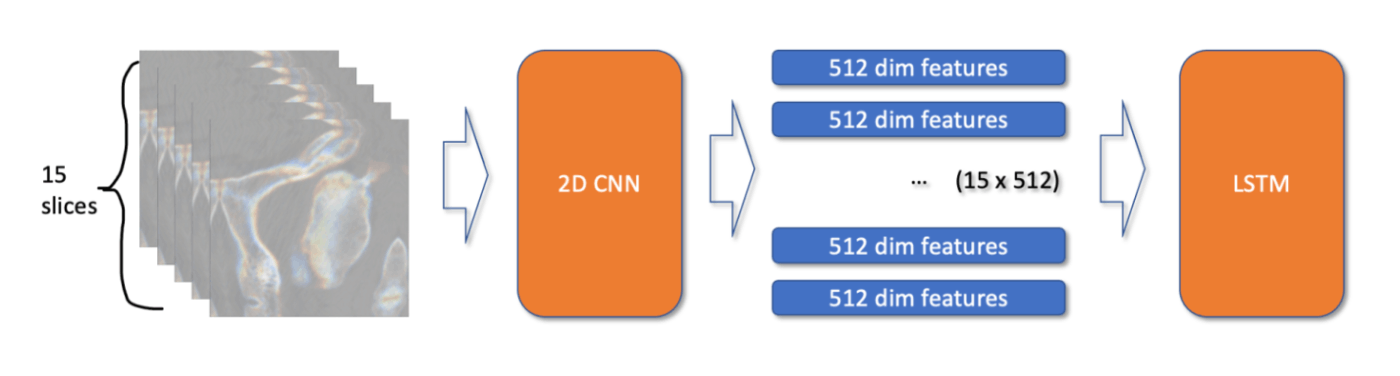
This model structure above, while being able to train a single vertebrae for fracture, does not able to train the patient as a whole for the presence of a fracture. So he designed another model.
- 7x15 slices as input
To treats a patient as one training sample, (the model above treats a vertebrae as one traning sample) this model is fed with 7x15 2D images at the same time, so that it has the ability to learn patient_overall labels.
(105 = 7x15)

However, it takes no much GPU memory and therefore can only use small backbones(1 batch_size has to be trained on 105 images at one time.)
6. Final Submission
3D Segmentation
・5fold resnet 18d unet (128x128x128)
・5fold effv2 s (128x128x128)
2.5D Classification
・Type1 5fold effv2s (512x512)
・Type1 5fold convnext tiny (384x384)
・Type2 5fold convnext nano (512x512)
・Type2 2fold convnext pico (512x512)
・Type2 2fold convnext tiny (384x384)
・type2 2fold nfnet l0 (384x384)
The submission time is 7.5 hours
7. AcKnowledge
In this competition, more than half of my models are trained on Z8G4 Workstation with dual A6000 GPU from Z by HP.
8. Summary
This is a greatful work, sophisticated preprocessing and model building. He used segmentation, 3dCNN, 2dCNN and LSTM in one solution!
I respect him and tyring to replicate for learning.
I recommend you to visit the original page.
Discussion