【ML Paper】DeiT: There are only fewer images for ViT? Part7
The summary of this paper, part7.
The authors proposed an improved Vision Transformer, DeiT(Data-Efficient image Transformer)
Original Paper: https://arxiv.org/abs/2012.12877v2
5. Training details & ablation
5.1 Initialization
The transformer is sensitive to initial values, after several test experiments, some of them not converging.
They used the recommendation of Hanin and Rolnick to initialize the weights with a truncated normal distribution.
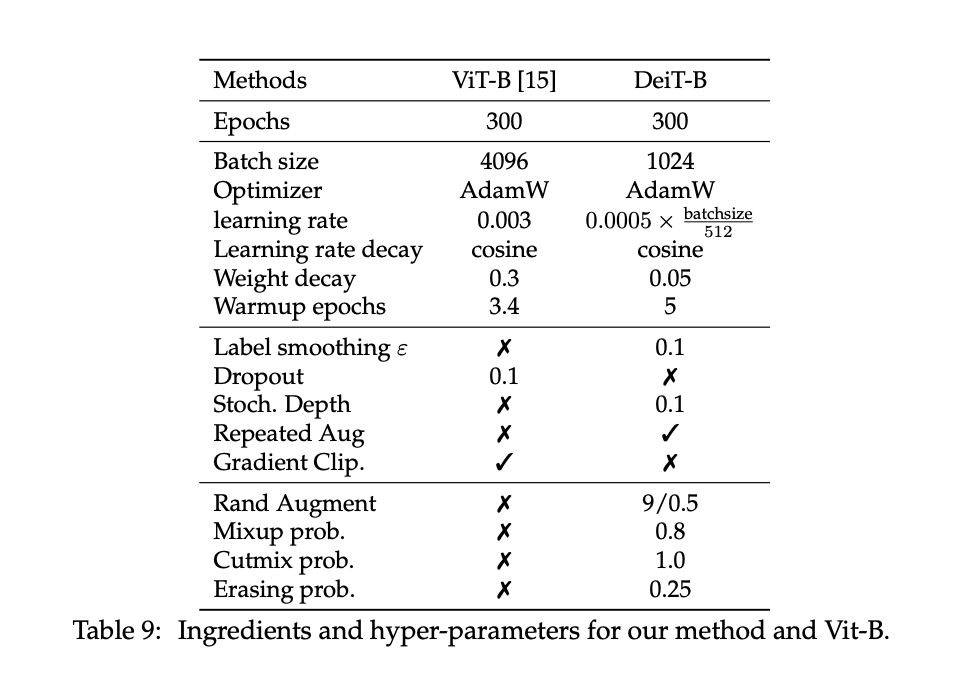
・Default configuration (unless stated otherwise)
For distillation, they follow the recommendations from Cho et al. The typical values τ = 3.0 and λ = 0.1 for the usual (soft) distillation.
5.2 Data augmentation
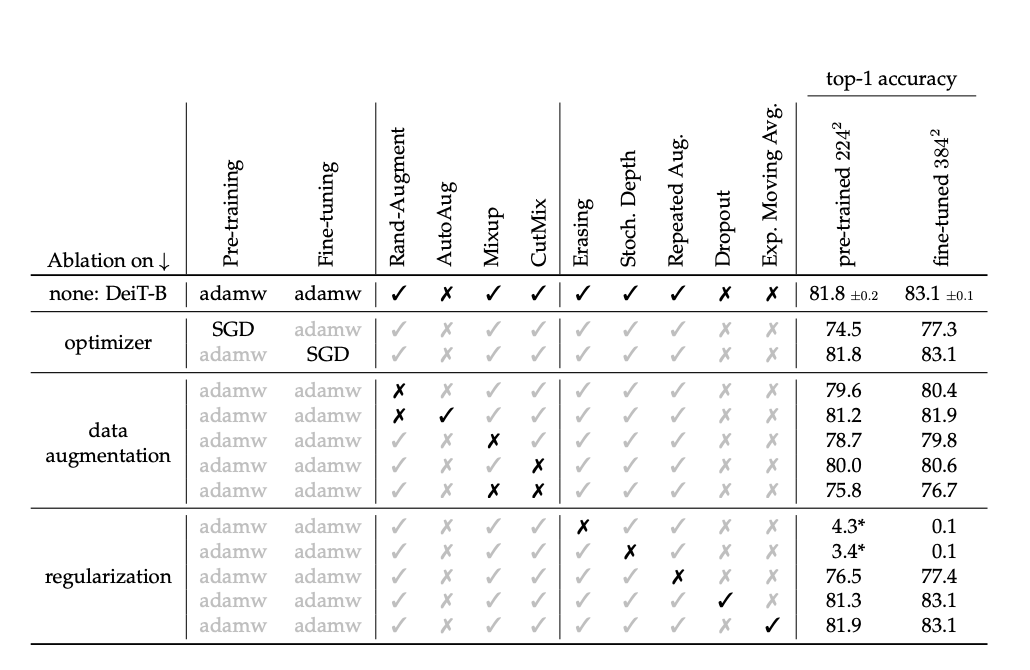
They used Rand-Augment(instead of Auto-Augment by ablation study) and random erasing, which improved the results.
Overall their experiments confirm that transformers require strong data augmentation.
One exception is dropout, which they exclude from their training procedure.
・Ablation study
The hyper-parameters are fixed according to Table 9, and may be suboptimal.
5.3 Optimizers & Regulatization
The best results use the AdamW optimizer with the same learning rates as ViT but with a much smaller weight decay, as the weight decay reported in the paper hurts the convergence in our setting.
We have employed stochastic depth, which facilitates the convergence of transformers, especially deep ones.
Regularization like Mixup and Cutmix improve performance. They also use repeated augmentation, which provides a significant boost in performance and is one of the key ingredients of the proposed training procedure.
Discussion