【ML】AdaBoost Explained
Boosting is the words often hear in machine learning field(especially GBDT relation).
But I don't know the mecanism of this, so this time I summarize about boosting.
There are two boosting methods, AdaBoost and GradientBoost.
First, I'll explain about Adaboost in this article.
1. AdaBoost
- AdaBoost
AdaBoost, short for Adaptive Boosting, is an ensemble learning technique that combines multiple weak learners to create a strong classifier.
Weak learner:
Is a classifier that performs slightly better than random guessing. For example, a simple decision stump (a one-level decision tree) is often used as a weak learner in AdaBoost.
1.2 How AdaBoost Works
-
Initialization:
- Assign equal weights to all training examples. Suppose we have
( N ) ( w_i = \frac{1}{N} )
- Assign equal weights to all training examples. Suppose we have
-
Training Weak Learners:
- For each iteration
t - Train a weak learner using the weighted training data.
-
Evaluate the weak learner’s performance on the training data and compute the weighted error rate
\epsilon_t
\epsilon_t = \frac{\sum_{i=1}^{N} w_i \cdot I(y_i \neq h_t(x_i))}{\sum_{i=1}^{N} w_i}
whereI(y_i \neq h_t(x_i))
Looks complex, but this is simple truely. This indicate the ratio of training weights that the model made mistakes on to the total training weights.(so range of\epsilon -
Compute the learner’s weight
\alpha_t
\alpha_t = \frac{1}{2} \ln \left( \frac{1 - \epsilon_t}{\epsilon_t} \right)
This weight represents the importance of the weak learner in the final model.
This formula means the model that has small error rate will have big weight in final model. -
Update the weights of the training examples:
w_i \leftarrow w_i \cdot \exp(\alpha_t \cdot I(y_i \neq h_t(x_i)))
The weights of misclassified examples are increased, so the next weak learner focuses more on these hard examples. - Normalize the weights so that they sum to 1.
- For each iteration
-
Final Model:
- The final strong classifier
H(x)
H(x) = \text{sign} \left( \sum_{t=1}^{T} \alpha_t \cdot h_t(x) \right)
whereT h_t(x)
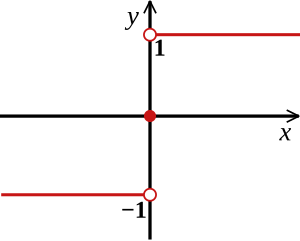
wikipedia[1]
- The final strong classifier
That is overview of adavoost mechanism, this architecture train the model from the model weight(
1.3 Advantages of AdaBoost
-
Robustness to Overfitting
Pretend overfitting, especially when using simple weak learners. -
Versatility
Can be used with various types of weak learners and adapted for different kinds of problems (classification, regression).
1.4 Limitations of AdaBoost
-
Sensitive to Noisy Data and Outliers
Since AdaBoost increases the weights of misclassified examples, it can be overly influenced by noise and outliers. -
Computationally Intensive
The sequential nature of training weak learners can be computationally expensive for large datasets.
1.5 Practical Use
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
weak_learner = DecisionTreeClassifier(max_depth=1)
adaboost = AdaBoostClassifier(base_estimator=weak_learner, n_estimators=50, learning_rate=1.0)
adaboost.fit(X_train, y_train)
y_pred = adaboost.predict(X_test)
2. Summary
This time, I explained aboout adaboost from mechanism. The feature that prevent overfitting is strong, but the sensitively to noisy data and outliner is crucial problem.
However, this model can perform when dataset is clear.
Each model has its advantages and disadvantages, so it is important to use them appropriately.
This article overs, thank you for reading.
Reference
[1] Sign function, wikipedia
Discussion