【ML Paper】Explanation of all of YOLO series Part 10
This is an summary of paper that explains yolov1 to v8 in one.
Let's see the history of the yolo with this paper.
This article is part 10, part 9 is here.
Original Paper: https://arxiv.org/pdf/2304.00501
6. YOLOv3
6.0.1 Bounding Box Prediction
YOLOv3 extends the bounding box prediction mechanism from YOLOv2 by forecasting four coordinates (
6.0.2 Class Prediction
Transitioning from a softmax approach, YOLOv3 utilizes binary cross-entropy to train independent logistic classifiers, framing the problem as a multilabel classification task. This modification allows multiple labels to be assigned to the same bounding box, accommodating complex datasets with overlapping labels. For instance, a single object can be classified simultaneously as both a "Person" and a "Man."
6.0.3 New Backbone
YOLOv3 introduces a more robust backbone composed of 53 convolutional layers integrated with residual connections. This enhanced feature extractor aligns YOLOv3 with state-of-the-art performance benchmarks while preserving real-time processing capabilities. Detailed architecture specifications are further elaborated in Section 6.1.
6.0.4 Spatial Pyramid Pooling (SPP)
Although not initially highlighted in the original paper, YOLOv3 incorporates a modified Spatial Pyramid Pooling (SPP) block within its backbone. This block concatenates multiple max pooling outputs with varying kernel sizes (
6.0.5 Multi-scale Predictions
Inspired by Feature Pyramid Networks, YOLOv3 implements multi-scale predictions by forecasting three bounding boxes at three different scales. This approach improves detection accuracy across objects of varying sizes.
6.0.6 Bounding Box Priors
YOLOv3 employs k-means clustering to determine the bounding box priors for anchor boxes. Unlike YOLOv2, which utilizes five prior boxes per cell, YOLOv3 reduces this number to three prior boxes distributed across three distinct scales. This adjustment optimizes the model's ability to generalize across different object sizes and scales.
6.0.7 Architecture Overview
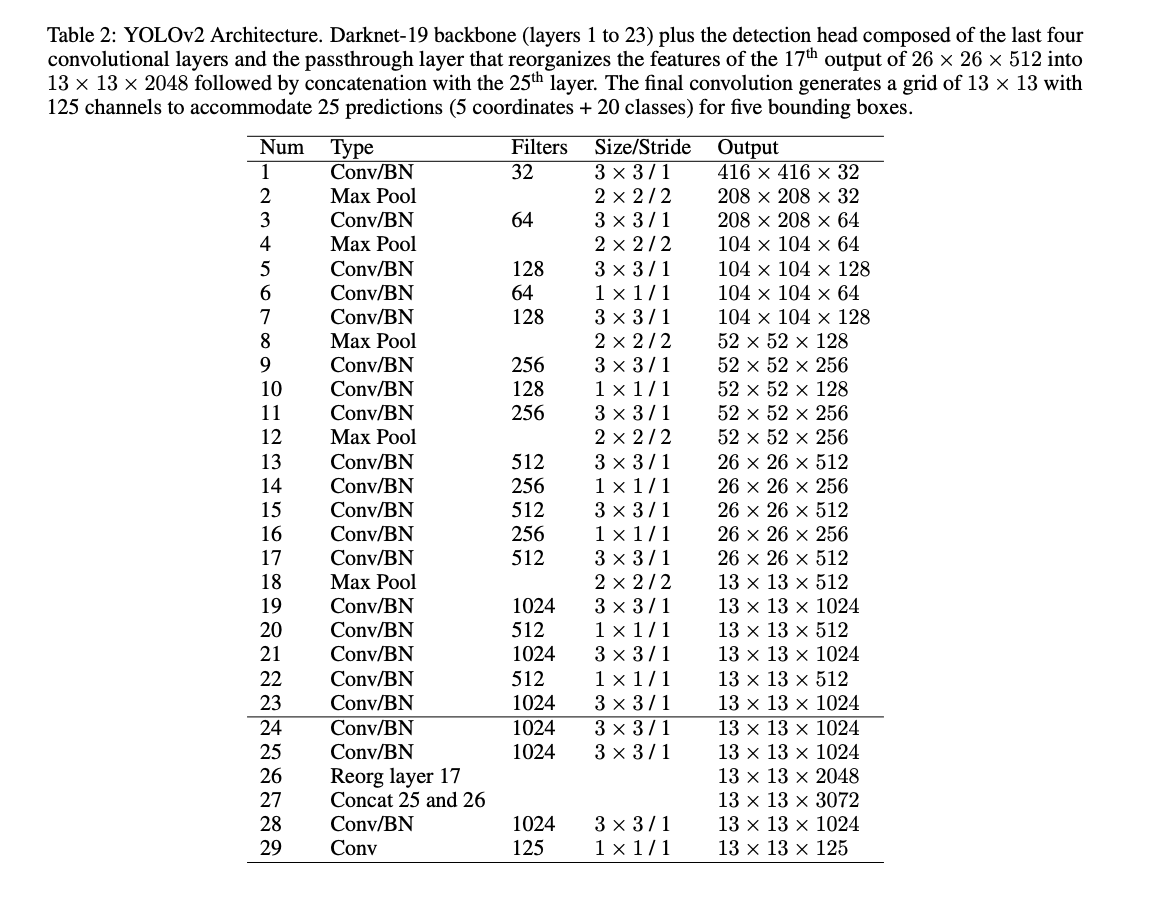
Table 2 presents the YOLOv2 architecture, detailing the Darknet-19 backbone and the detection head. The backbone comprises layers 1 to 23, while the detection head includes the final four convolutional layers and a passthrough layer that reorganizes features for concatenation and final prediction. The architecture facilitates real-time object detection by generating a grid of 13 × 13 with 125 channels, accommodating 25 predictions (5 coordinates + 20 classes) for five bounding boxes.
Discussion