VIT解説 Part3 MLPHead
今回はMLPHeadを解説し、VITの解説をまとめます。
4. MLPHead
MLPHeadはクラス分類を行う分類機です。
アーキテクチャは以下のようになっています。
・MLPHead

単MLPHeadは、単純なLinearとLayerNormによる一層の線型結合層です。
- Liner
線形結合層。出力は重み付き線形和の配列 - LayerNorm
前回解説しています。
主な役割は、Encoderで得られたベクトル空間を特定のクラス数に整える事です。
MLPHeadには活性化関数が含まれていないため、学習の部分はEncoder部分が担っている事が分かります。
5. まとめ
以上でVITの各部品についての解説は終了です。
では、改めてVITの概要を確認しましょう。
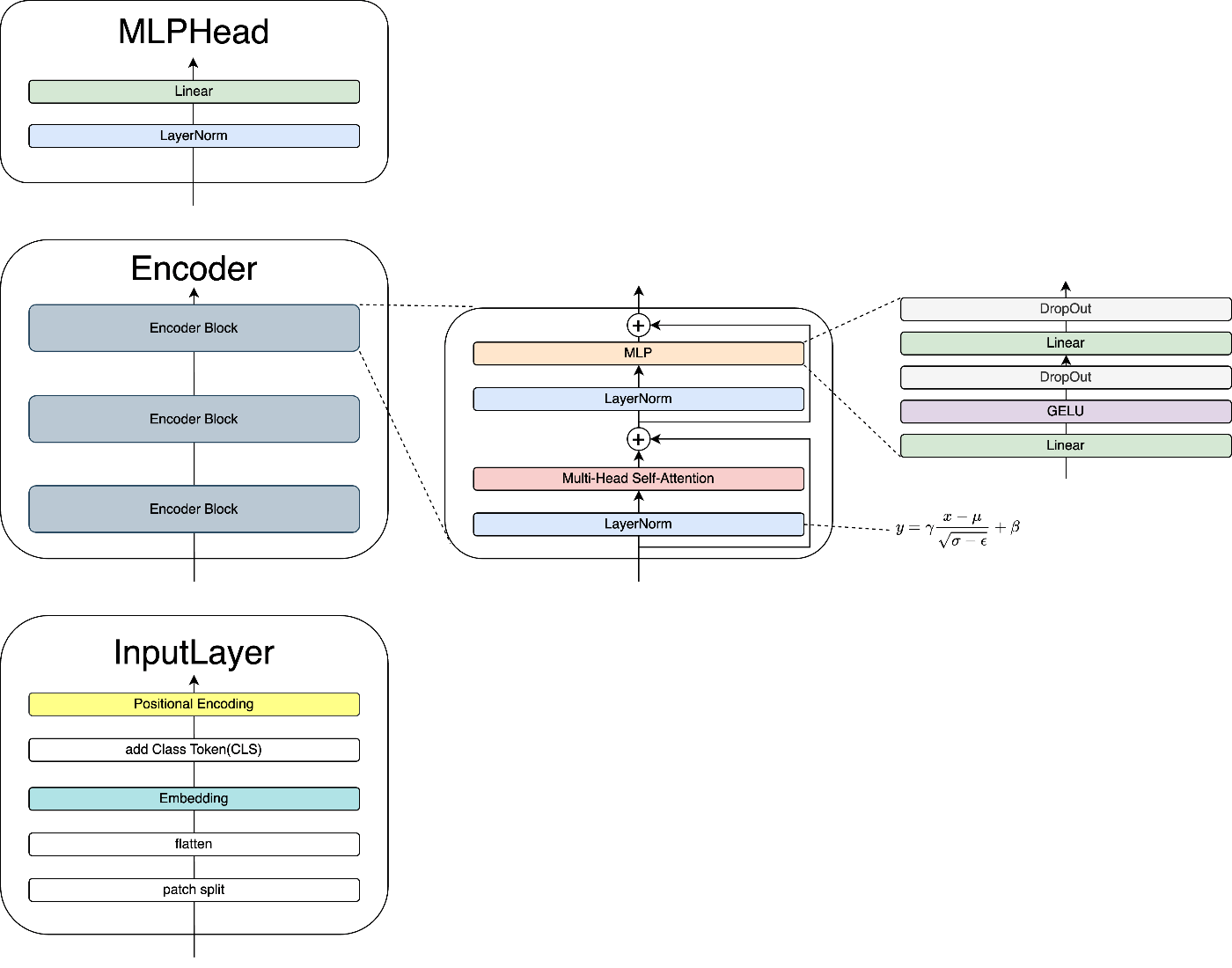
5.1 InputLayer
InputLayerは以下の流れで処理を行います。
- 画像をパッチに分割 (patch split)
- 一次元化 (flatten)
- ベクトル化 (Embedding)
- クラストークン追加 (add Class Token)
- 位置埋め込み (Positional Encoding)
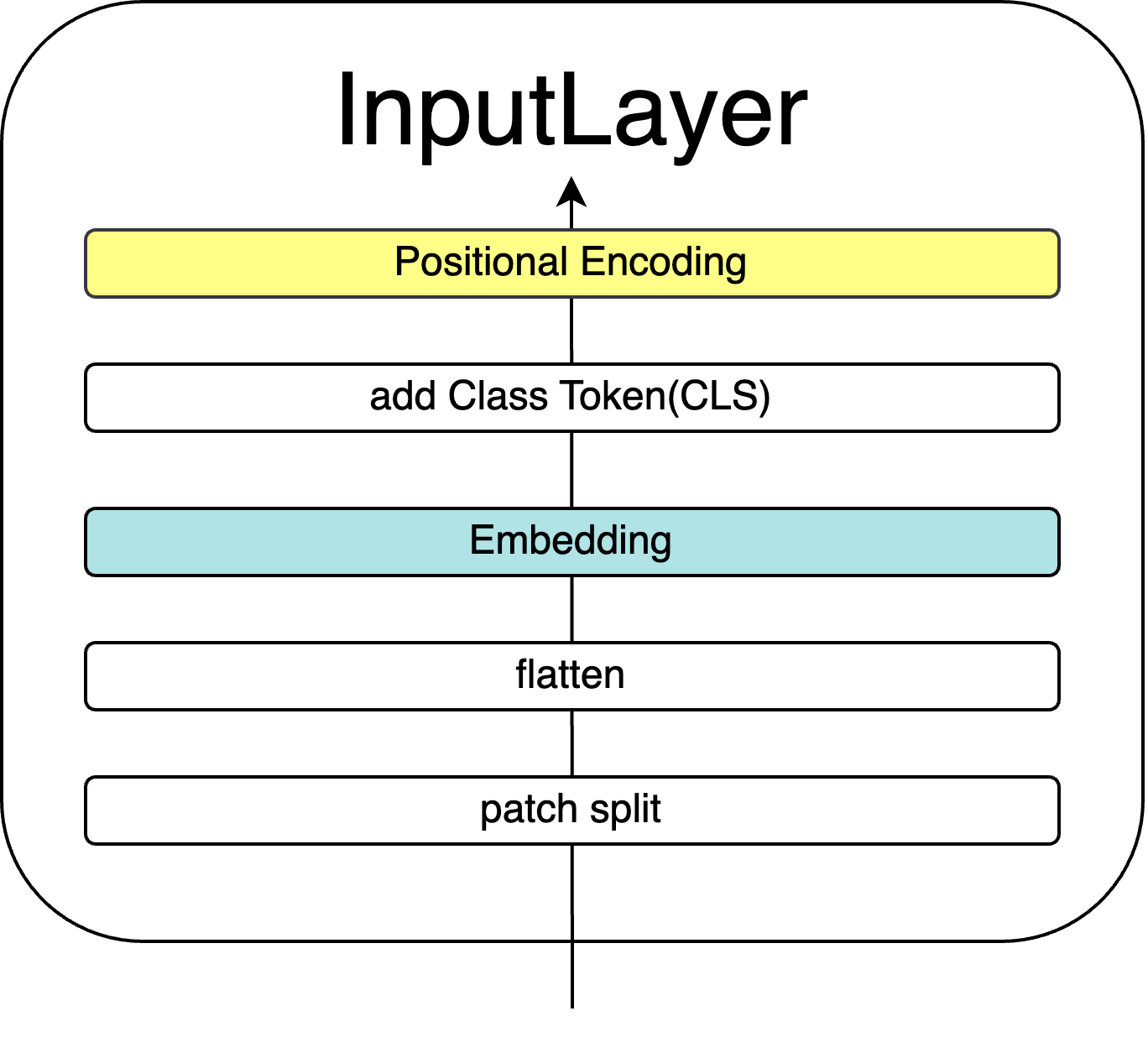
この処理によって画像は機械が扱えるような、意味のある二次元配列に変換されます。
5.2 Encoder
Encoderは以下の流れで処理を行います。
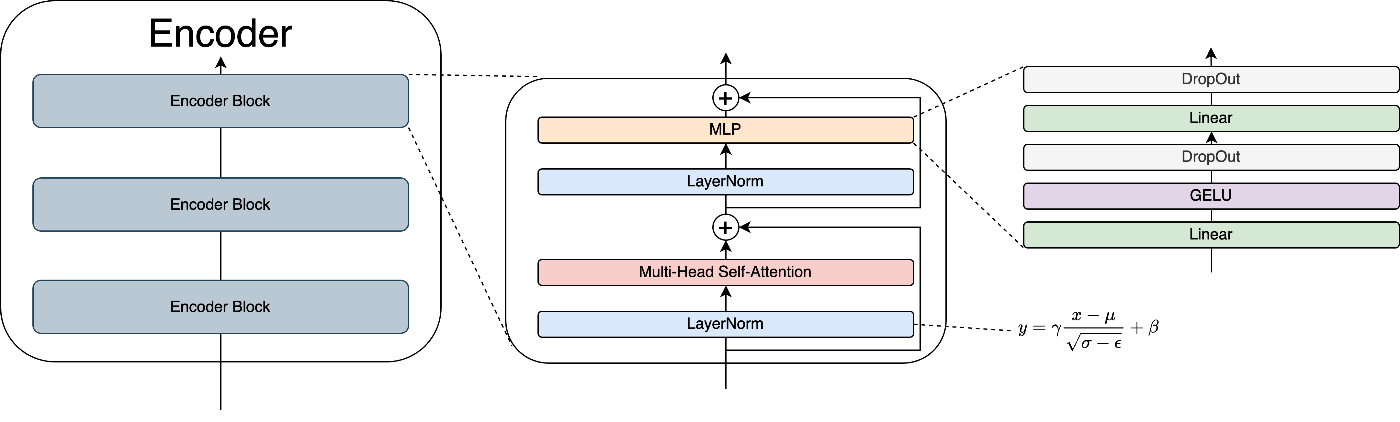
※Encoder Blockの処理
- 入力をLayerで正規化 (LayerNorm)
- MHSAで、各トークンと周囲トークンの類似度を特徴量として複数空間で取得 (MHSA)
- Skip Conecctionで線形変換の要素を追加 (+)
- Layerで正規化 (LayerNorm)
- 線形変換とGELUで必要な特徴量の取捨選択 (MLP)
- DropOutで過学習抑制 (MLP)
Encoderは、これを積み重ねてより深い特徴を学習します。
5.3 MLPHead
MLPHeadは以下の流れで処理を行います。
- 入力をLayerで正規化 (LayerNorm)
- 線形結合層で出力の数を分類先クラス数に合わせる (Linear)
5.4 概略
おおまかに
InputLayerで学習可能な形に変換、
Encoderで特定の画像トークンと周囲の画像トークンの類似度を学習、
MLPHeadで出力形状を整えます。
VITで注目すべきはAttention機構による特徴の抽出と、Multi-Headによる特徴空間の多様化です。これによってVITは柔軟な表現力を獲得する事ができています。
VITの解説は以上になります。
最後まで読んでいただきありがとうございました。
参考
(1)原論文 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
(2)Vision Transformer 入門 株式会社技術評論社 2022/9/30 山本晋太郎,徳永匡臣,箕浦大晃,QIU YUE,品川政太郎
Discussion