【Kaggle】BirdCLEF2024 1st Solution explained


This time, continue to previous one, I'll explain BirdCLEF2024's solution.Let's enjoy together!
0. Competiton explanation
This competition's purpose is classification to the 182 type bird calls.
The validation method is AUC-ROC, so we had to predict all of birds classes.
Competition host provide the random length audio calling data over 240000 samples as training data, and data not labeled for utilize to augmentation or otehrs.
As the problem must be addressed were:
unbalanced data, probably noisy and mixed test data, data while bird not calling, etc..
Additionaly point to be noted is the limitation of submittion. This competition only allow CPU and under 120 minutes for inference. We have to both infer and process the data in time.
1. Dataset
Data/labels preprocessing
used two data
- BirdCLEF 2024
train_audio - pseudo labeled
unlabeled_soundscape
For the final submission, they used only 2024 data, both train_audio and unlabeled_soundscapes.
At the very beginning of the competition, we found that random fold0 gives much better results that other folds.
To find out why this happen, they calculated various statistics related to siganl strength (see the picture below) and found that fold0's statistics are lower than other fold's.
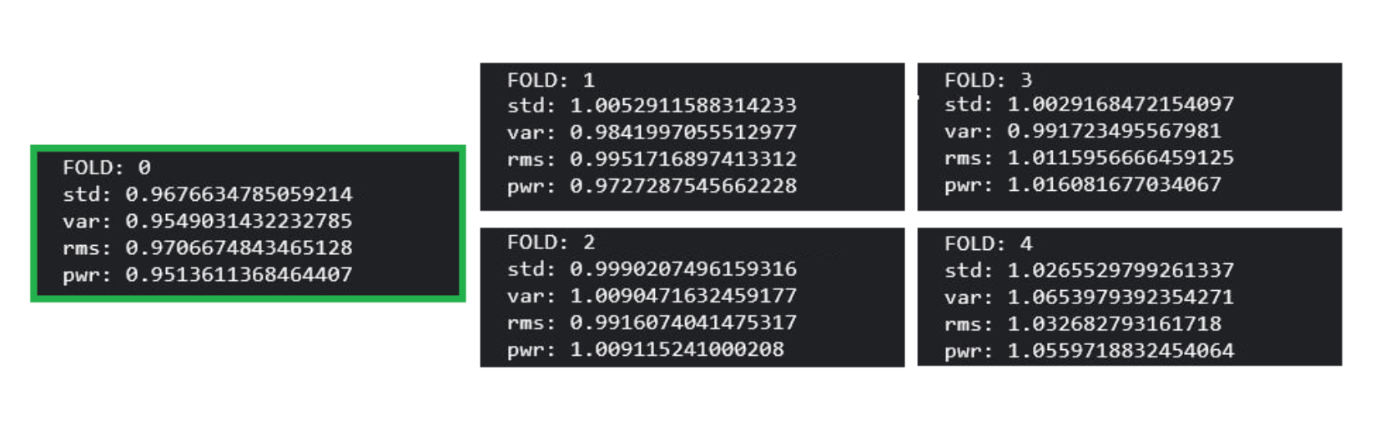
so for ensembles, instead of folds0-4, they use fold0 and 0.8 uqantile of statistics T = std + var + rms + pwr, and this worked well. Seemingly, noizey and too loud suido harms the models.
In other words, it means useing only 80% data that has lower statistics, and it gives us the cleaner dataset because it avoids noises.(it's make sense. if data's four statistics above is lower, it is less-noise data.)
Data Extraction
There are some duplicate audio files in te train data, so we discard them. Data in train_audio is also filtered with Google-bird-vocalization-classifier: if the classifer's max prediction doesn't match with the primary label. the chunk is droped (maybe there is no bird sound or it has a bad quality). If the classifier's max prediction matches with the secondary label, they replace the primary label with the secondary label. Moreover, if the file has secondary labels, then they take the primary label with 0.5, and the remaining 0.5 is every distributed among the secondary labels.
They also add pseudo labels obtained with Google classifier to resulting labels with a coefficient of 0.05. The soundscapes are labeled with an ensemble of Google classifier, and our best models are trained only with train_audio. Finnaly, if the sound is too short, they use cyclic padding.
The doubting datasets is too important, but easy to forget. We will have to be noticing this.
2. Preprocessing
Models are trained on 10-second chunks that consist of two 5-second adjacent chunks with averaged labels. The idea is that a 10-second chunk provides processing of full chirps or full periods of chirps() if they are cropped by 5-second chunks).
Mel parameters
- n_fft = 1024
- hop_length = 500
- n_mels = 128
- fmin = 40
- fmax = 15000
- power = 2
3. Models
- efficientnet_b0 pretrained on ImageNet
- regnety_008 pretrained on ImageNet
RegNet is efficient and high performance NN architecture(achieved from different way to efficientnet) for computer vision tasks. Paper is here.
Other models tried
- seresnext gives the same results as efficient net, but the inferencetime is almost 3 times longer.
- They saw that 3rd place(NVBird) uses efficientvit due to its high spped. IN their case, VITs work significantly worse.
- Modifications like SED and Psi's CNN from previous years work slower and provide worse results than pure back bones. They are convinced that overly complex models do not work better than simple ones.
They don't experiment with larger models since they have no computation resources and use only Kaggle kernels.
3.1 Training
Parameters:
- CrossEntropyLoss
- AdamW
- CosineAnnealingLR scheduler
- Initinal learning rate 1e-3 to 3e-3
- 7-12 epochs
- Batch sie = 96
Data augmentation:
- random audio segment
- XV masking
- horizontal cutmix
Training details
First of all, they use only CE loss, not BCE (BCE shows significantly wrose results than CE). It can be connected with the specificity of train data. There are too many labels(182), and almost always, only one them is present (with augmentations up to 2-3). So, the problem is reduced to a multiclass one. During the training, CE loss leads to the multiclass problem, and logits are passed through SoftMax. However, in the inference, they don't use softmax and pass logits through sigmoid (postprocessing is discussed in the next section in detail).
Second, they use audio segmentation. During the epoch, the model sees only one random chunk from each file. The problem is that the train_audio has many small files (+ some really lerge ones), and unlabeled_soundscape have few large files. So, they devide the audio into X-second segments that are considered as separate files. They tried X = {20, 30, 60}, which led to a different number of epochs: the smaller the X, the fewer the number of epochs (because the number of steps per epoch is greater). As a result, they balance the train_audio and unlabeled_soundscapes.
Postprocessing
To predict chunk n, the models take 10 seconds: 5 seconds from the chunk n and 2.5 seconds from the previous and next chunks.

Although logits are passed through softmax during the train, they use sigmoid in the inference. The two most important things in the inference pipeline are chunks averaging and ensembling with min() reduction. In the figure below, they demonstrate the best pipeline for each class in chunk n.

Using the sigmoid with CE-trained models leads to the predictions being noisy, so min() just lowers uncertain predictions.
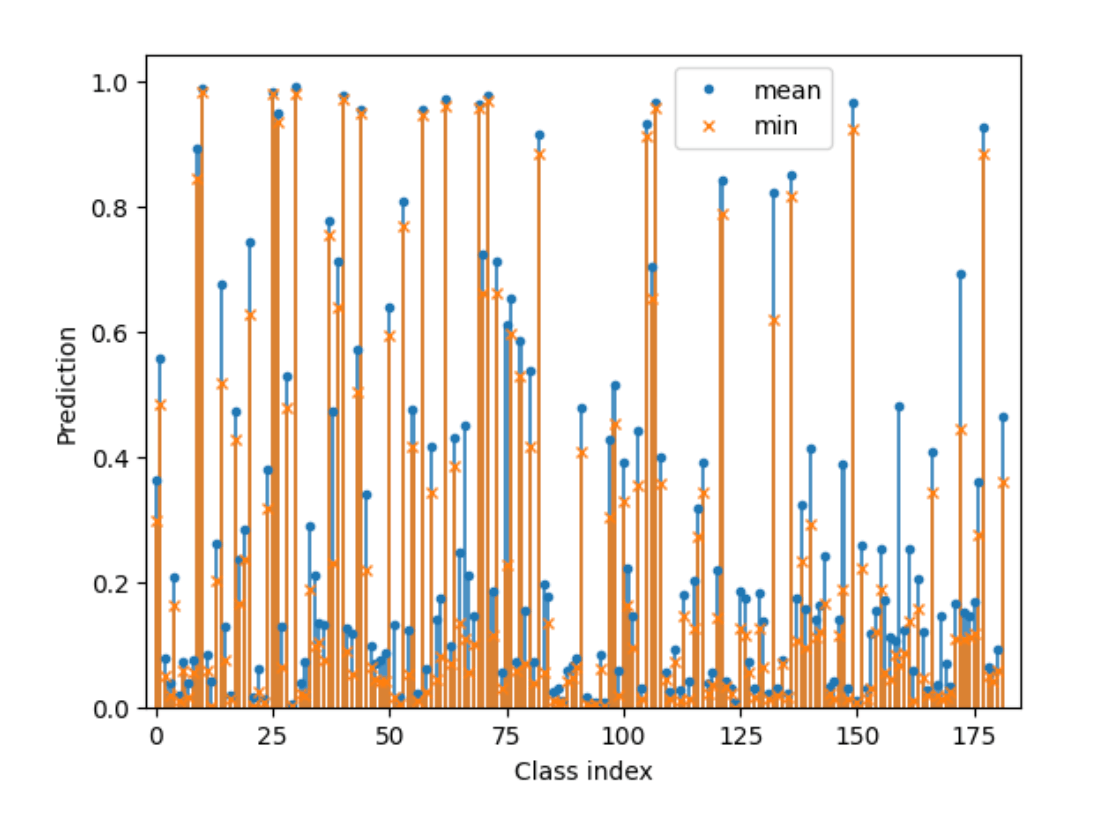
All of there are great ideas. Why authors could come up with ideas like this...?
3.2 Inference time optimization
- Compilation with OpenVINO (fixed model input)
- Parallel mel spectrograms computing with joblib
- Storing all the computed mel spectrograms in RAM
These techniques are inconspicuous, but very important in this competition. These allow above many model's inference and faster creating melspecs.
4. What didn't work
everything else...
Negligible change in score
- 183 “nocall” class
We add nocall samples from external data to the train and use an additional 183 class. For inference, we take only 182 classes with bird calls. There was no improvement in the public score. Now, we observe a significant increase in private score (0.655 -> 0.671)… - Mel spectrogram normalization
- Other mel spectrogram parameters
- Input image size 224x224
- 15 second chunk as model input
- Softmax temperature
- Weight averaging (SWA and EMA)
- Pseudo labeling with softmax temperature
- Pretraining on the previous years data
Noticeable decrease in score
- BCEloss, BCEloss with positive weights, focalloss
- Other augmentations (mixup, noise, pixdrop, blur, audio 1d augmentations)
- STFT instead of mel spectrogram
- Additional data from Xeno-canto
We tried different approaches to improve the quality of additional data, such as filtering with Google classifier or BirdNet, taking random fold, and taking some quantile of statistics T. The best solution is not to use additional data… The private score also proves it. - Pseudo labeling of train data with high coefficient
It seems that pseudo-labeling for train_audio is a way of label smoothing, so it is better to use a small coefficient. - Train on 10 second chunks and inference on 5 second chunks
- Train additional models to detect bird calls
- The scores for such models are close to random/constant prediction
- Multistage training
We tried to train several epochs on the train_audio and then on the unlabeled_soundscapes and vice versa. We also tried to train on the whole data and finetune on the train_audio or unlabeled_soundscapes.
5. Main steps to success
The table below shows changes relative to the baseline (our 1st submission) pipelinr that gives noticeable improvement to the score.
baseline
efficientnet_b0- CEloss
- softmax for the inference
- first 5 seconds from each file
- fold0 out of
train_audiowithout duplicates
| Main steps | Private score | Public score |
|---|---|---|
| baseline | 0.544028 | 0.599798 |
| sigmoid for the inference | 0.588338 | 0.628777 |
| random 5 second chunk | 0.601803 | 0.638572 |
| XY masking | 0.601909 | 0.639358 |
| horizontal cutmix | 0.615368 | 0.670460 |
| pseudo labeled unlabeled_soundscapes | 0.639777 | 0.687000 |
| 60 second segmentation | 0.649936 | 0.691752 |
| secondary labels | 0.642781 | 0.695215 |
| filtering train_audio chunks with Google classifier | 0.655190 | 0.703051 |
| 10 seconds input | 0.670410 | 0.716058 |
| ensemble (mean) 5 efficientnet_b0 | 0.686169 | 0.724319 |
| ensemble (min) 5 efficientnet_b0 | 0.688977 | 0.734945 |
| ✅ ensemble (min) 6 efficientnet_b0 | 0.689146 | 0.738566 |
| ensemble: mean[min(3 efficientnet), min(3 regnety)] | 0.691749 | 0.733836 |
| ✅ ensemble: mean[3 efficientnet, 3 regnety] | 0.690391 | 0.729178 |
Surprisingly, the results are very stable: correlation of public and private score is 0.96.
6. Point to see
- statistics
T = std + var + rms + pwrtrick that has solid evidence (chap 1) - Data Extraction from another model(google classifier) (chap 1)
- method to predict chunk n (chap 3.1 Postprocessing)
- Parallel mel spectrograms computing with joblib (chap 3.2)
- Storing all the computed mel spectrograms in RAM (chap 3.2)
7. Summary
It was so great solution, and very learnable write-up.
All of works are based on solid evidence. That is one of most important skill to be winner, but it's so difficult.
I recommend to you to see this solution on kaggle and upvote to theirs powerful works.
Discussion