【ML】How to use the XGBoost
1. XGBoost
XGBoost is one of the decision tree algorithms.
1.1 Advantages
Here are the advantages of XGBoost. It is one of the oldest and most mature gradient boosting libraries, and have great flexibility, room for adjustment.
So it can over the other libraries by precise parameter tuning.
-
Extensive Hyperparameter Control
XGBoost offers a wide range of hyperparameters that allow fine-tuning of the model's structure, regularization, and complexity, enabling it to be tailored precisely to the specific data and task.・LightGBM and CatBoost:
Both libraries offer extensive hyperparameter tuning options, but XGBoost typically provides a broader range of parameters and finer control over the model's behavior. For example, XGBoost’s control over regularization (L1/L2) and its tree-building process is more detailed. -
Custom Objective and Evaluation Functions
XGBoost supports custom objective functions and evaluation metrics, providing flexibility to optimize the model for specialized tasks and unique problem requirements.・LightGBM:
Supports custom objective functions, but its implementation is generally less flexible compared to XGBoost.
・CatBoost:
Focuses more on ease of use and often works well with default settings, so it doesn't emphasize custom objectives to the same extent. It does support custom loss functions but is less commonly used for this purpose. -
Advanced Tree Pruning and Regularization
XGBoost uses depth-wise pruning and offers robust L1/L2 regularization, allowing for precise control over model complexity and helping to prevent overfitting while maximizing performance.・LightGBM:
Uses leaf-wise tree growth, which is different from XGBoost’s depth-wise pruning. While this can lead to faster training and often better accuracy, it’s less flexible in controlling overfitting.
・CatBoost:
Also has built-in regularization techniques, but XGBoost’s depth-wise pruning and regularization parameters provide more granular control, which can be a significant advantage when precision is critical.
1.2 Disadvantages
Inversely, the disadvantages of the XGBoost are here.
XGBoost may have many disadvantage to other libraries like LGBM(fast) and CatBoost(handle categorical). This is because new libraries often incorporate functionality from existing libraries and then provide new features to differentiate them.
But, it has stable imprementation from long history, and of course have different architecture and parameters from other libraries, so can contribute to model diversity.
・Disadvantages
- Training speed
- Mmeory usage
- Handling of categorical features
- Ease of use
- Feature importance reliability(less reliable compared to CatBoost)
- Scalability with big data(also memory usage, GPU scalability)
- Overfitting
XGBoost is sometimes more prone to overfitting compared to LGBM and CatBoost, especially when the model is not properly tuned. CatBoost, in particular, has built-in mechanisms to prevent overfitting - Parameter Tuning Complexity(trade off to flexibility)
Totally, we should use XGBoost for sub model.
2. Code
I'll explain with code from here.
2.1 Step
- Create Dataset
Prepare the train and valid dataset (+test dataset) - Set Parameters
Set parameters of train and configlation of model and evaluate. - Train
Train the model with some hyperparameters. Please try the optimization of hyperprams by optuna(auto) or wandb(manual). - Predict and Postprocess
Predict by model.predict_proba(X_test). This time, using same dataset to valid and test, but typically, they should be separated(because using fold spilit).
After prediction, calculate score. - (option) Show the Importance
GBDT can show the importance of features. This indicate us what featture is important and we can use this information for another models like NN. This is so useful, I explain below about more detail settings.
Well, let's see the code. The below is an example code.
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import xgboost as xgb
# Load the breast cancer dataset
data = load_breast_cancer()
X = data.data
y = data.target
# Feature names (optional, useful for plotting and interpretation)
feature_names = data.feature_names
df = pd.DataFrame(X, columns=feature_names)
df['target'] = y
display(df.head())
# Split data
X_train, X_test, y_train, y_test = train_test_split(df.drop(columns=['target']), df['target'], test_size=0.2, random_state=42)
# Convert the data into DMatrix format for XGBoost
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# Set parameters for XGBoost
params = {
'objective': 'binary:logistic', # Objective for binary classification
'eval_metric': 'logloss', # Evaluation metric
'learning_rate': 0.1, # Learning rate
'max_depth': 6, # Depth of each tree
'lambda': 1.0, # L2 regularization term
'alpha': 0.5, # L1 regularization term
'seed': 42, # Random seed for reproducibility
'verbosity': 1 # Verbosity level
}
# Train the model
evals = [(dtrain, 'train'), (dtest, 'eval')]
bst = xgb.train(params, dtrain, num_boost_round=100, evals=evals, early_stopping_rounds=10, verbose_eval=True)
# Predict probabilities
y_pred_prob = bst.predict(dtest)
# Convert probabilities to binary outputs
y_pred = [1 if prob > 0.5 else 0 for prob in y_pred_prob]
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy on test set: {accuracy * 100:.2f}%')
# Plot feature importance
xgb.plot_importance(bst, importance_type='weight', title='Feature Importance by Weight', xlabel='Importance', ylabel='Feature')
plt.show()
xgb.plot_importance(bst, importance_type='gain', title='Feature Importance by Gain', xlabel='Importance', ylabel='Feature')
plt.show()
xgb.plot_importance(bst, importance_type='cover', title='Feature Importance by Cover', xlabel='Importance', ylabel='Feature')
plt.show()
# Optional: Perform cross-validation
cv_results = xgb.cv(
params=params,
dtrain=dtrain,
num_boost_round=100,
nfold=5,
metrics={'logloss'},
early_stopping_rounds=10,
seed=42,
verbose_eval=True
)
print(f"CV mean logloss: {cv_results['test-logloss-mean'].min():.4f}")
・Result
- table

- log
...
[98] train-logloss:0.01427 eval-logloss:0.11929
[99] train-logloss:0.01420 eval-logloss:0.11889
Accuracy on test set: 95.61%
...
[98] train-logloss:0.01576+0.00094 test-logloss:0.12623+0.03479
[99] train-logloss:0.01567+0.00093 test-logloss:0.12610+0.03489
CV mean logloss: 0.1261
- Importance
XGBoost has three option of showing importance "wight", "gain" and "cover".-
Weight, also known as frequency, refers to the number of times a feature is used in all the trees of the model to make a split.
A higher weight indicates that the feature is used more frequently across all the trees, suggesting that the feature is considered important by the model for making decisions. However, it doesn't account for how much the feature improves the model's predictive performance. -
Gain measures the average improvement in the model's accuracy brought by a feature when it is used in a split. It represents the reduction in the loss function due to splits on a particular feature.
A higher gain indicates that the feature contributes more to improving the model's predictions, making it a key indicator of feature importance in terms of performance impact. Gain is often considered the most important and informative of the three metrics. -
Cover measures the number of observations affected by the splits involving a particular feature. It essentially represents the number of instances a feature helps to classify or differentiate in the trees.
A higher cover value suggests that the feature is used in splits that impact a large portion of the dataset, indicating its significance in distinguishing data points. However, it doesn't necessarily mean the feature is effective at improving accuracy.
-
Weight, also known as frequency, refers to the number of times a feature is used in all the trees of the model to make a split.
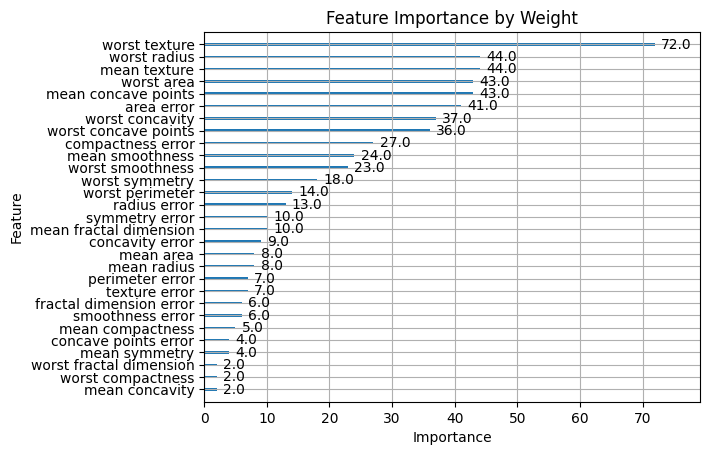


-
Logloss

-
Logloss()CV

3. Summary
This time, I explained about XGBoost, I explained other GBDT like LGBM and CatBoost, I'd be happy if you read that too.
Discussion