【ML Paper】DeiT: There are only fewer images for ViT? Part8
The summary of this paper, part8.
The authors proposed an improved Vision Transformer, DeiT(Data-Efficient image Transformer)
Original Paper: https://arxiv.org/abs/2012.12877v2
5.4 Exponential Moving Average (EMA).
About EMA of the network obtained after training.
There are small gains, which vanish after fine-tuning: the EMA model has an edge of is 0.1 accuracy points, but when fine-tuned the two models reach the same (improved) performance.
5.5 Fine-Tuning
The authors follow a fine-tuning schedule similar to FixEfficientNet but with full data augmentation. When changing resolutions, they interpolate positional embeddings, preferring bicubic interpolation over bilinear to maintain vector norms, which preserves the pre-trained model's accuracy. Using bilinear interpolation can reduce the vector norm, hurting performance. They fine-tune with optimizers like AdamW or SGD and typically train at a resolution of 224x224 before fine-tuning at a higher resolution of 384x384.
Fine-tuned model results for each model are this:
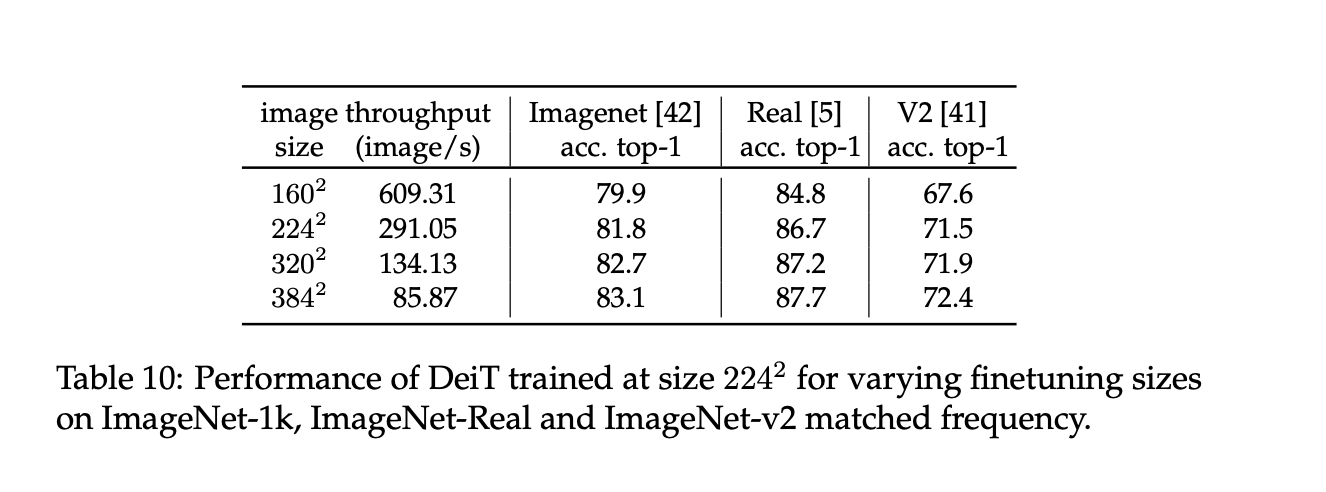
5.6 Training time
Training the DeiT-B model (Base version) for 300 epochs takes 37 hours on 2 nodes or 53 hours on a single node. Compared to a similar model, RegNetY-16GF, DeiT-B's training is about 20% faster.
Smaller models like DeiT-S (Small) and DeiT-Ti (Tiny) can be trained in less than 3 days on 4 GPUs. Fine-tuning DeiT-B at a higher resolution (384x384) takes 20 hours on a single node (8 GPUs) for 25 epochs.
Since DeiT doesn't rely on batch normalization, smaller batch sizes can be used without performance loss, making training of larger models easier. Due to repeated augmentation, only one-third of the dataset is seen per epoch.
Discussion