【ML Paper】YOLO: Unified Real-Time Object Detection Summary
This time, I'll explain the YOLO image detection model with paper.
This is the summary of yolo explain articles part 1 to 10.
Original paper: https://arxiv.org/abs/1506.02640
1. Preface
First, YOLO has many versions(probably v11 is the latest in 2024/10/17), so we'll start with the first one.
2. Introduction
YOLO ("You Only Look Once") is an object detection system that reframes the detection task as a single regression problem, directly predicting bounding box coordinates and class probabilities from image pixels. Unlike traditional methods that rely on complex pipelines involving classifiers applied at various locations and scales (such as sliding windows or region proposals), YOLO uses a single convolutional neural network to simultaneously predict multiple bounding boxes and their associated class probabilities.
Key Advantages of YOLO:
-
Speed: YOLO is extremely fast, capable of processing images at 45 frames per second with its base network and over 150 fps with a faster version. This enables real-time processing of streaming video with minimal latency.
-
Global Reasoning: By training on full images, YOLO incorporates contextual information about object classes and their appearances, reducing background errors compared to methods that only consider local regions.
-
Generalization: YOLO learns generalizable object representations, outperforming top detection methods like DPM and R-CNN when applied to new domains such as artwork. This makes it less likely to fail with unexpected inputs.
Limitations:
- Accuracy: While YOLO is fast, it lags behind state-of-the-art detection systems in terms of precision, especially in localizing small objects within images.
Despite these limitations, YOLO's unified architecture simplifies the detection pipeline and makes it easier to optimize. Its open-source training and testing code, along with pre-trained models, are available for download, facilitating further research and application development.
3. Unified detection
3.1 Introduction to Unified Object Detection
In this approach, we unify various components of object detection into a single neural network. The network predicts bounding boxes and class probabilities for the entire image simultaneously. This unified system allows for global reasoning about all objects in an image and enables end-to-end training with real-time speeds, while maintaining high precision in object detection.
3.2 Image Grid Division and Responsibility for Detection
The input image is divided into an
3.3 Bounding Box Predictions
Each bounding box prediction contains five values:
-
x y -
w h - A confidence score, which is the product of the probability of an object being present and the Intersection Over Union (IOU) between the predicted and actual bounding boxes.
3.4 Class Probability Predictions
Each grid cell predicts class probabilities conditioned on the presence of an object. Regardless of the number of bounding boxes, each grid cell predicts only one set of class probabilities, reflecting the likelihood of different classes within that cell.
3.5 Final Prediction
During testing, the system multiplies the class probabilities with the confidence of the bounding boxes to compute class-specific confidence scores. These scores encode both the probability of a specific class appearing in the box and how well the predicted box matches the object.
3.6 Model Structure and Tensor Representation
The model treats object detection as a regression problem. The image is divided into an
3.7 Example Application (PASCAL VOC)
For evaluation on the PASCAL VOC dataset, the parameters are set as
4. Network design
The network architecture is inspired by the GoogLeNet model for image classification.
The model network has 24 convolutional layers followed by 2 fully connected layers.
Instead of the inception modules used by GoogLeNet, simply use 1 × 1 reduction layers followed by 3 × 3 convolutional layers.
The final output of our network is the 7 × 7 × 30 tensor
of predictions.
The full network is shown below.

Our detection network has 24 convolutional layers followed by 2 fully connected layers. Alternating 1 × 1convolutional layers reduce the features space from preceding layers.
*model pretrained the convolutional layers on the ImageNet classification
task at half the resolution (224 × 224 input image) and then double the resolution for detection.
Fast YOLO
The authors also trained a fast version of YOLO. Fast YOLO uses aneural network with fewer convolutional layers (9 instead of 24) and fewer filters in those layers. Other than the size of the network, all training and testing parameters are the same between YOLO and Fast YOLO.
5. Inference
5.1 Inference
During inference, predicting detections for a test image requires only a single evaluation of the network, just like during training. On the PASCAL VOC dataset, the network predicts 98 bounding boxes per image along with class probabilities for each box. This efficiency makes YOLO extremely fast at test time compared to classifier-based methods, as it avoids multiple network evaluations.
The grid-based design enforces spatial diversity in bounding box predictions. Usually, it's clear which grid cell an object falls into, and the network predicts one box per object. However, for large objects or objects near the borders of multiple cells, multiple cells may localize the object well, leading to multiple detections. Non-maximal suppression can be applied to eliminate these duplicate detections, improving mean Average Precision (mAP) by about 2-3%, though it's not as critical for performance as in methods like R-CNN or DPM.
5.2 Limitations of YOLO
YOLO imposes strong spatial constraints on bounding box predictions because each grid cell predicts only two boxes and can only belong to one class. This constraint limits the model's ability to predict multiple nearby objects, making it struggle with small objects that appear in groups, such as flocks of birds.
Since the model learns to predict bounding boxes directly from data, it has difficulty generalizing to objects with new or unusual aspect ratios or configurations. Additionally, the model uses relatively coarse features for predicting bounding boxes due to multiple downsampling layers in the architecture, which affects localization precision.
Lastly, although the loss function approximates detection performance, it treats errors equally in small and large bounding boxes. A small localization error in a large box is generally benign, but the same error in a small box significantly affects the Intersection over Union (IOU) score. Consequently, the main source of error in YOLO is incorrect localization.
6. Comparison to Other Detection Systems
Object detection is essential in computer vision, aiming to identify and locate objects within images. Traditional methods often involve multiple separate steps, which can be slow and complex. Here's how YOLO (You Only Look Once) compares to other leading detection systems:
6.1 Deformable Parts Models (DPM)
DPM detects objects by sliding a window across the image and using separate processes for feature extraction, classification, and bounding box prediction. YOLO simplifies this by using a single neural network that handles all these tasks simultaneously. This unified approach makes YOLO faster and more accurate than DPM.
6.2 R-CNN
R-CNN generates many region proposals and processes each one through multiple stages, including feature extraction and classification, which makes it slow (over 40 seconds per image). YOLO improves efficiency by dividing the image into a grid and predicting bounding boxes and class probabilities in one step. This results in real-time performance and reduces the number of bounding boxes significantly.
6.3 Other Fast Detectors
Methods like Fast R-CNN and Faster R-CNN attempt to speed up the R-CNN framework by sharing computations and using neural networks for region proposals. While they are faster and more accurate than the original R-CNN, they still don't achieve real-time speeds. YOLO stands out by designing the detection system for speed from the ground up, avoiding the complexity of traditional pipelines.
6.4 Deep MultiBox and OverFeat
Deep MultiBox uses neural networks to predict regions of interest but still requires additional steps for classification. OverFeat focuses on localization but doesn't integrate detection tasks fully. YOLO combines all necessary detection steps into a single network, making the process more streamlined and efficient.
6.5 Conclusion
YOLO's all-in-one neural network architecture offers significant advantages over traditional object detection systems. By integrating feature extraction, bounding box prediction, and classification into a single process, YOLO achieves faster and more accurate real-time object detection, making it a powerful and efficient solution for a wide range of applications.
7. Experiments
7.1 Experiments overview
The study evaluates YOLO (You Only Look Once) against other real-time object detection systems using the PASCAL VOC 2007 and 2012 datasets.
7.2 Comparison with Other Real-Time Systems
YOLO stands out as the fastest detector on PASCAL VOC 2007, with Fast YOLO achieving 52.7% mAP at 155 FPS. The standard YOLO model improves accuracy to 63.4% mAP while maintaining 45 FPS. In contrast, other systems like DPM and Fast R-CNN either offer lower accuracy or much slower speeds. For example, Fast R-CNN reaches a higher mAP of 70.0% but only runs at 0.5 FPS, which is not suitable for real-time applications.
7.3 Error Analysis and Improvement
YOLO helps reduce background false positives when combined with Fast R-CNN detections. This collaboration enhances overall performance by leveraging YOLO's speed and accuracy to improve Fast R-CNN's results.
7.4 Performance on PASCAL VOC Datasets
YOLO maintains high accuracy and real-time performance on both PASCAL VOC 2007 and 2012 datasets. Fast YOLO achieves 52.7% mAP at 155 FPS, while the standard YOLO reaches 63.4% mAP at 45 FPS, outperforming other state-of-the-art methods in both speed and accuracy.
7.5 Generalization to New Domains
YOLO also performs well on new types of data, such as artwork datasets, demonstrating its ability to generalize better than other detectors.
8. Comparison to Fast R-CNN
8.1 VOC 2007 Error Analysis
They tested the YOLO and Fast R-CNN with VOC 2007 Error Analysis.
They use the methodology and tools of Hoiem et al. They look at the top N predictions for each category at test time. Each prediction is either correct or it is classified based on the type of error:
• Correct: correct class and IOU > .5
• Localization: correct class, .1 < IOU < .5
• Similar: class is similar, IOU > .1
• Other: class is wrong, IOU > .1
• Background: IOU < .1 for any object
Results
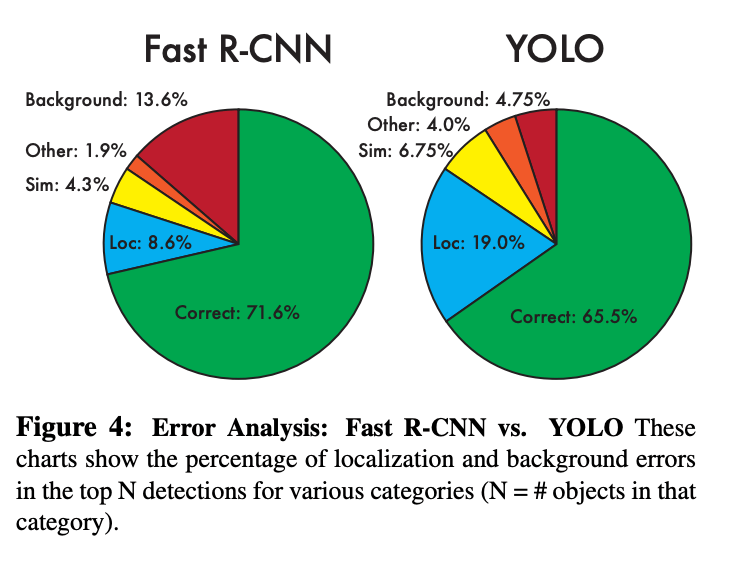
Figure 4 shows the breakdown of each error type averaged across all 20 classes.
YOLO can detect the correct class better than Fast R-CNN. Fast R-CNN makes much fewer localization errors but far more background errors. 13.6% of
it’s top detections are false positives that don’t contain any
objects.
Fast R-CNN has a high correct rate, but when loc and similar are included, YOLO significantly surpasses it in accuracy.
9. VOC 2012 Results
On the VOC 2012 test set, YOLO achieves a mean Average Precision (mAP) of 57.9%, trailing current state-of-the-art detection methods, with performance closer to that of the original R-CNN using VGG-16. YOLO encounters difficulty with small objects, especially in categories like "bottle," "sheep," and "tv/monitor," where it scores 8-10% lower than R-CNN or Feature Edit. However, YOLO performs competitively in categories like "cat" and "train," where it surpasses other methods.
A combined Fast R-CNN + YOLO model achieves high performance, with Fast R-CNN benefiting from a 2.3% mAP increase when integrated with YOLO, resulting in an improvement of five ranks on the public leaderboard.
Leaderboard:

9.1 Generalizability: Person Detection in Artwork
In object detection research, datasets typically use training and testing data from similar distributions. However, real-world applications often encounter domain shifts in data distribution, making performance on novel test data unpredictable. To evaluate YOLO’s robustness, comparisons were made against other methods on the Picasso and People-Art datasets, which feature artwork images focused on person detection.
When models trained on VOC 2007 data were tested on artwork, R-CNN, which uses Selective Search for bounding box proposals tuned for natural images, exhibited a sharp decline in accuracy. R-CNN’s reliance on precise bounding box proposals limited its adaptability to new domains.
Conversely, DPM (Deformable Part Model) demonstrated better generalizability due to its strong spatial models of object shape and layout, though it begins from a lower initial AP. YOLO showed promising adaptability, maintaining better performance on artwork than both R-CNN and DPM. YOLO’s capability to model object size, shape, and contextual relationships aids its detection accuracy across different visual domains. While artwork images differ from natural images at the pixel level, the consistency in object size and shape across domains enables YOLO to generate reliable bounding boxes and accurate detections.
10. Real-Time Detection In The Wild
YOLO is a fast, accurate object detector, making it ideal for computer vision applications.
After connecting the YOLO to the webcam including the time to fetch images from the camera and display the detections, the resulting system is interactive and engaging.
While YOLO processes images individually, when attached to a webcam it functions like a tracking system, detecting objects as they move around and change in appearance.
11. Conclusion
They introduce YOLO, a unified model for object detection that is simple to construct and can be trained directly on full images. Unlike classifier-based approaches, YOLO is trained on a loss function that directly corresponds to detection performance, with the entire model trained jointly. Fast YOLO stands as the fastest general-purpose object detector in the literature, and YOLO advances the state of the art in real-time object detection. Additionally, YOLO generalizes well to new domains, making it ideal for applications that require fast, robust object detection.
This is the end, thank you for reading!
References
[1]Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi, You Only Look Once: Unified, Real-Time Object Detection, https://arxiv.org/abs/1506.02640
Discussion