【ML Paper】DeiT: Summary
This is a summary of the explanation of the DeiT paper, Let's start.
The authors proposed an improved Vision Transformer, DeiT(Data-Efficient image Transformer)
Original Paper: https://arxiv.org/abs/2012.12877v2
0. Abstract
The high performance of ViT requires hundreds of millions of images using a large infrastructure.
In this work, they produce convolution-free transformers by training on Imagenet only. It achieved a top-1 accuracy of 83.1%(single crop) with a single computer in less than 3days.
There is a teacher-student strategy for transformers. It relies on a distillation token ensuring that the student learns from the teacher through attention.
This token-based distillation, especially when using a convnet as a teacher gives them 85.2% accuracy, competitive results to convnets.
1. Introduction
・Accurary and Throughput

・The throughput is measured as the number of images processed per second on a V100 GPU.
・DeiT-B is identical to VIT-B, but the training is more adapted to a data-starving regime.
・It is learned in a few days on one machine.
・The symbol ⚗refers to models trained with their transformer-specific distillation.
The vision transformer (ViT) introduced by Dosovitskiy et al. is an architecture directly inherited from Natural Language Processing.
The paper concluded that transformers “do not generalize well when trained on insufficient amounts of data”, and the training of these models involved extensive computing resources.
They build upon the visual transformer architecture from Dosovitskiy et al. and improvements included in the timm library. With their Data-efficient image Transformers (DeiT), they report large improvements over previous results.
They introduce a token_based strategy specific to transformers and denoted by DeiT⚗, and show that it advantageously replaces the usual distillation.
1.1 Introduction Summary
In summary, their work makes the following contributions:
・It was developed to handle the problem amount of the dataset.
・Achieve competitive results against the state of the art on ImageNet with no external data.
・They introduce a new distillation procedure based on a distillation token, which plays the same role as the class token, except that it aims at reproducing the label estimated by the teacher. Both tokens interact in the
transformer through attention. This transformer-specific strategy outperforms vanilla distillation by a significant margin.
・It also works well for downstream tasks such as fine-grained classification.
2. Terms
2.1 Knowledge Distillaton
Knowledge Distillation is a method that uses the teacher model's output as an auxiliary loss of the student model.
・Knowledge Distillation Image

[1]
2.2 Class Token
Class Token is a vector that represents the information of all the other tokens in sequence by self-attention with them.
The class token acts as a way to aggregate information from all tokens and is designed specifically to handle this task. For tasks like classification, this final representation of the class token is used as the input to a classifier (a fully connected layer followed by softmax, for example) to make a prediction.
3. Distillation through attention
3.1 Soft distillation
Soft distillation minimizes the Kullback-Leibler divergence between the softmax of the teacher and the softmax of the student model.
The Loss is:
Where
ground truth labels y
3.2 Hard-label distillation
They introduce a variant of distillation where they take the hard decision of the teacher as a true label. Let
The Loss is:
Use the teacher's prediction to answer CE loss as like auxilially loss.
For a given image, the hard label associated with the teacher may change depending on the specific data augmentation. We will see that this choice is better than the traditional one, while being parameter-free and conceptually simpler: The teacher prediction
Note also that the hard labels can also be converted into soft labels with label smoothing, where the true label is considered to have a probability of
3.3 Distillation token
They add a new token, the distillation token, to the initial embeddings.
Their distillation token is used similarly as the class token: it interacts with other embeddings through self-attention, and is output by the network after the last layer for loss for distillation.
The distillation embedding allows our model to learn from the output of the teacher, as in a regular distillation, while remaining
complementary to the class embedding.
The average cosine similarity between these tokens is equal to 0.06. As the class and distillation embeddings are computed at each layer, they gradually become more similar through the network, and it will be 0.93 at the last layer. But still lower than 1, This is expected since as they aim at producing targets that are similar but not identical.
・Distillation token
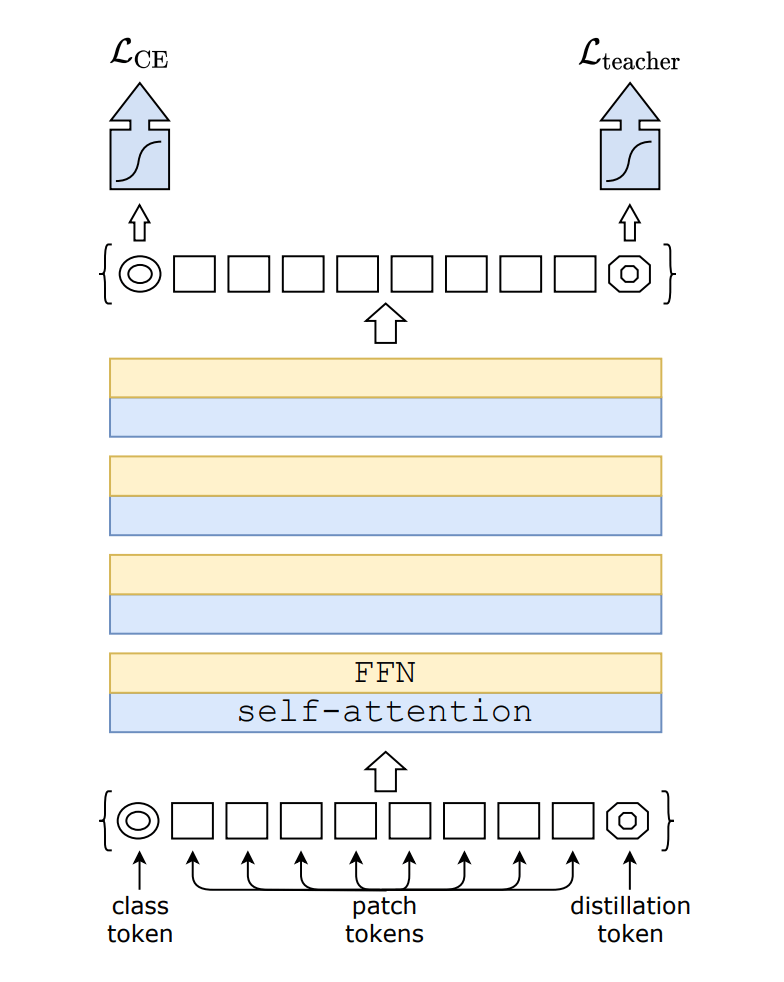
They tried adding the 2nd class token with calculate loss with true label
In contrast, it shows their distillation strategy provides a improvement over a vanilla distillation baseline.
3.4 When fine-tuning
Use both the true label and teacher's predictions during the fine-tuning stage at higher resolution. They have also tested with true labels only but this reduces the benefit of the teacher and leads to a lower performance.
3.5 Inference method: joint classifiers
At test time, both the class or the distillation embeddings produced by the transformer are associated with linear classifiers and able to infer the image label. Yet their referent method is the late fusion of these two separate heads, for which they add the softmax output by the two classifiers to make the prediction.
4. Experiments
Some experiments results.
They proposed the three models DeiT-B(Based on ViT-B), DeiT-S, DeiT-Ti(smaller models).
・Variants of models

The only parameters that vary across models are the embedding dimension and the number of heads, and it keeps the
dimension per head constant (equal to 64). Smaller models have a lower parameter count, and a faster throughput. The throughput is measured for images at resolution 224×224.
・Model comparison
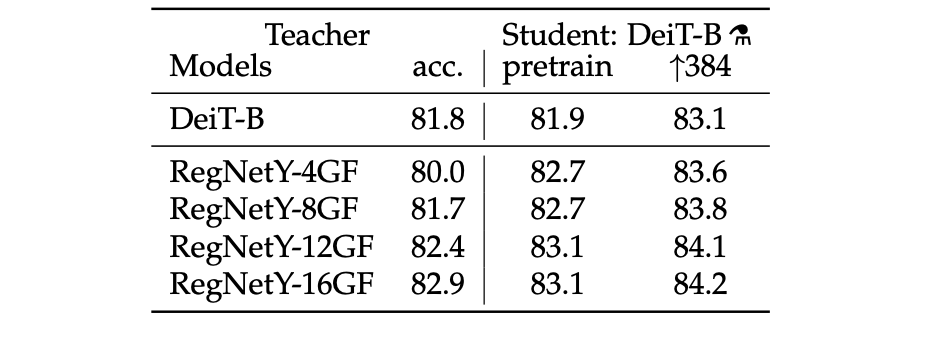
4.1 Convnets teachers
Models using the convolution layer as a teacher outperform transformer models.
The fact that the convnet is a better teacher is probably due to the inductive bias inherited by the transformers through distillation, as explained in Abnar et al.
In all of their subsequent distillation experiments, the default teacher is a RegNetY-16GF [40] (84M parameters) that they trained with the same data and same data-augmentation as DeiT. This teacher reaches 82.9% top-1 accuracy on ImageNet.
・ Distillation experiments on Imagenet with DeiT, 300 epochs of pertaining.
They separately report the performance when classifying with only one of the class or distillation token embeddings, and then with a classifier taking both of them as input.
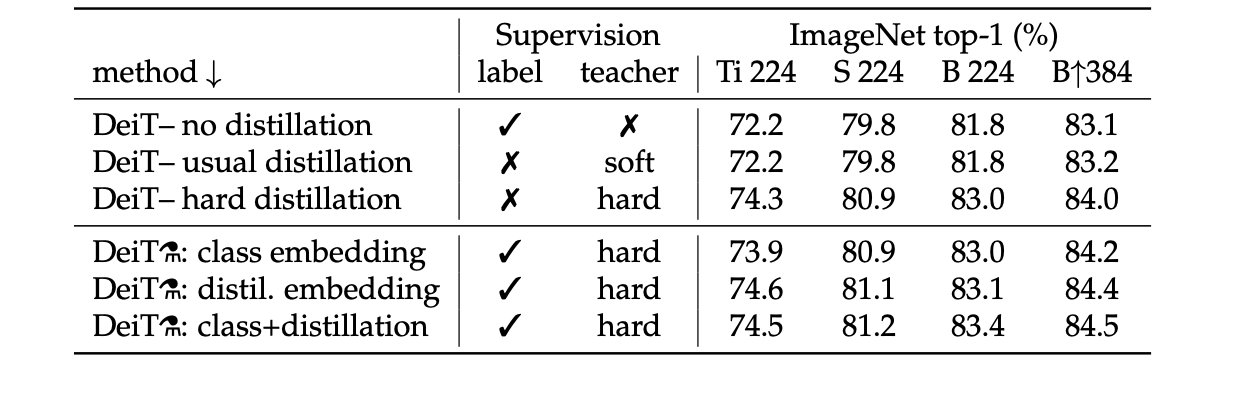
4.2 Comparison of distillation methods
They compared the performance of different distillation strategies.
・Hard distillation significantly outperforms soft distillation when even using only a class token.
・ Proposed distillation strategy further improves the performance, showing that the two tokens provide complementary information useful for classification: the classifier on the two tokens is significantly better than the independent class and distillation classifiers.
4.3 Agreement with the teacher & inductive bias?
The architecture of the teacher has an important impact.
Does it inherit existing inductive bias that would facilitate the training?
The proposed distilled model is more correlated to the convnet than with a transformer learned from scratch. As to be expected, the classifier associated with the distillation embedding is closer to the convnet that the one associated with
the class embedding, and conversely the one associated with the class embedding is more similar to DeiT learned without distillation.
・Disagreement analysis between convnet, image transformers and distillated transformers.

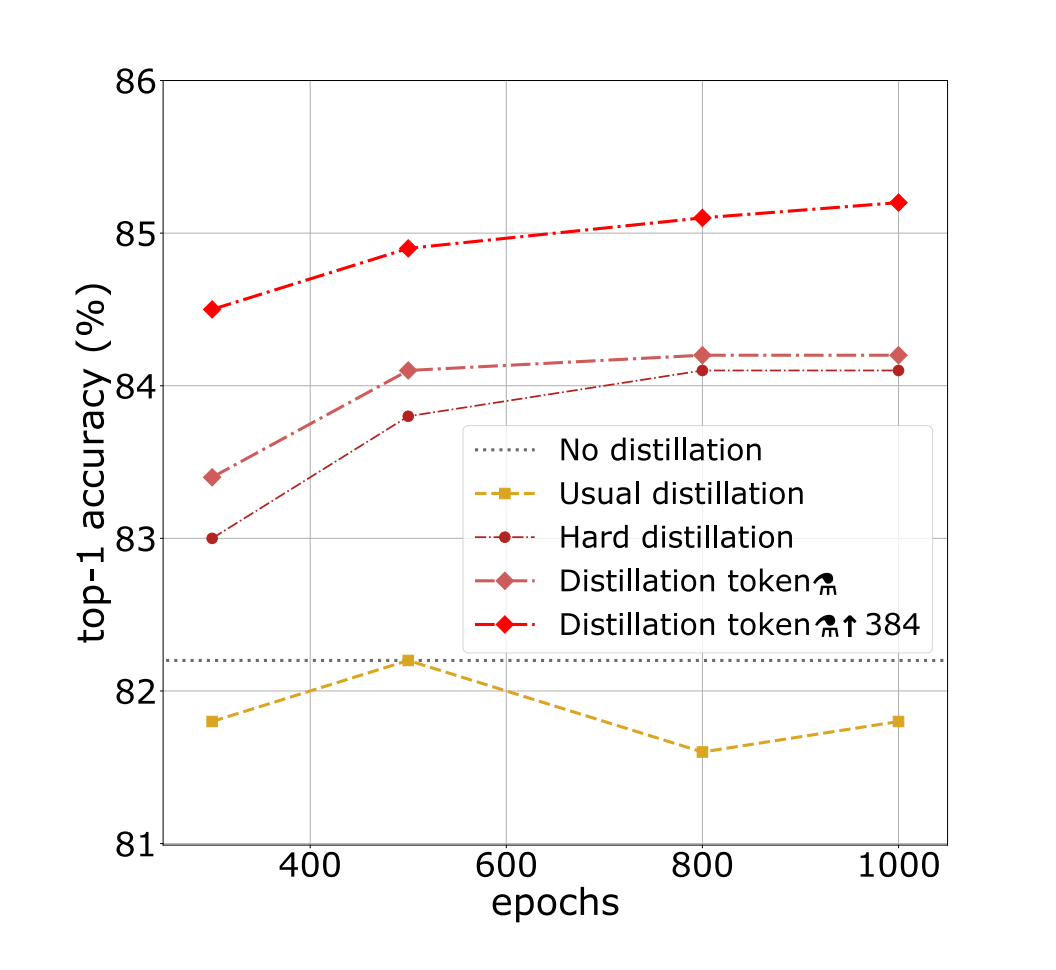
4.5 Number of epochs
Increasing the number of epochs significantly improves the performance of training with distillation.
With 300 epochs, proposed distilled network DeiT-B⚗ is already better than DeiT-B. But while for the latter the performance saturates with longer schedules, proposed distilled network clearly benefits from a longer training time.
・The proposed method performs better when the training time is long.
4.6 Efficiency vs Accuracy
The image classification methods are often compared as a compromise between accuracy and another criterion, such as FLOPs, number of
parameters, size of the network, etc.
The proposed method DeiT is slightly below EfficientNet, which shows that we have almost closed the gap between vision transformers and convnets when training with Imagenet only. These results are a major improvement (+6.3% top-1 in a
comparable setting) over previous ViT models trained on Imagenet1k only.
Furthermore, when DeiT benefits from the distillation from a relatively weaker RegNetY to produce DeiT⚗, it outperforms EfficientNet. It also outperforms by 1% (top-1 acc.) the Vit-B model pre-trained on JFT300M at resolution 384 (85.2% vs 84.15%), while being significantly faster to train.
・Throughput(images processed per second) on and accuracy
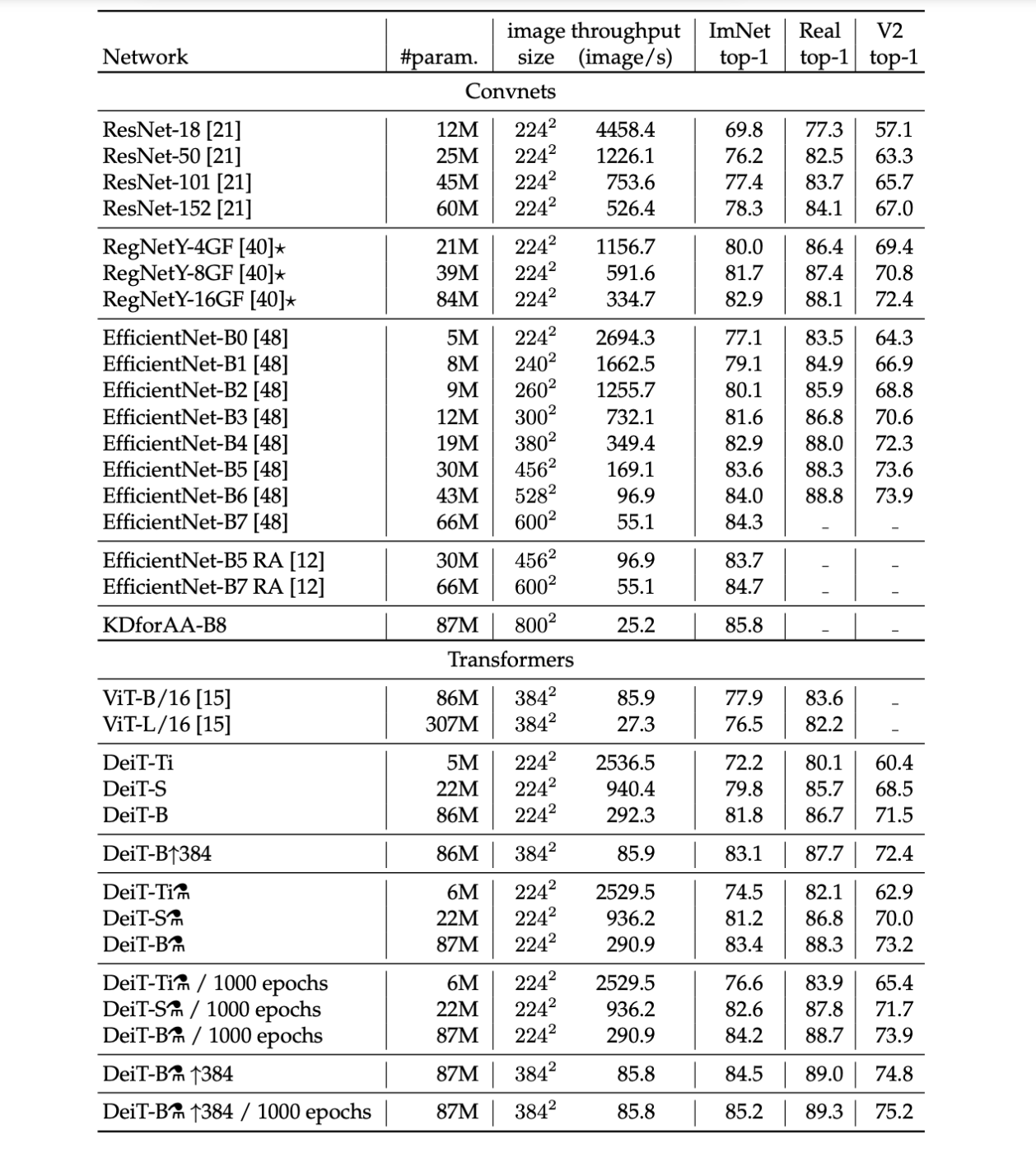
・The throughput is measured as the number of images that we can process per second on one 16GB V100 GPU.
・take the largest possible batch size.
・ Distillation on ImageNet with DeiT-B: performance as a function of the number of training epochs. The model without distillation saturates after 400 epochs(straight line).
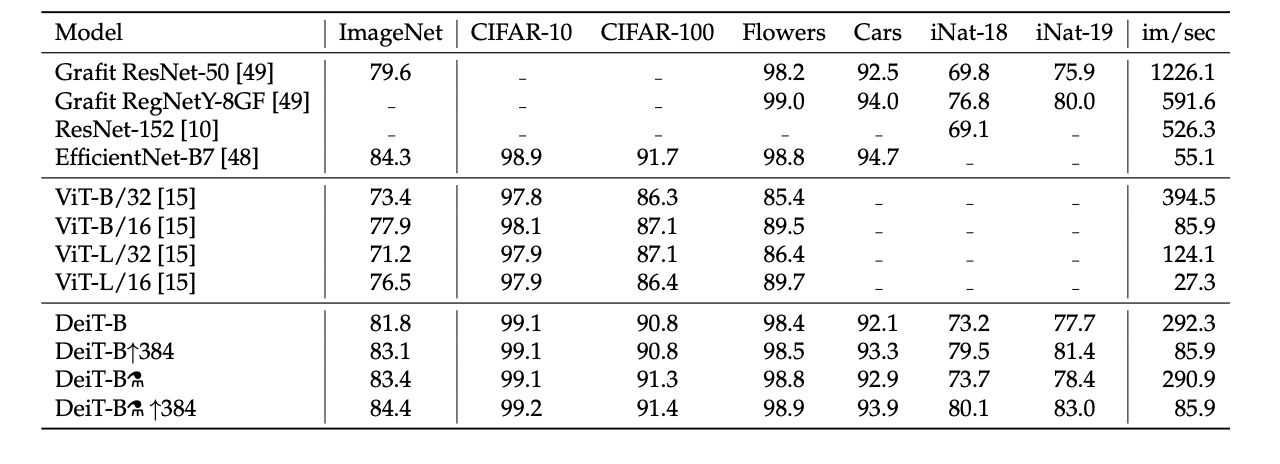
4.7 Transfer learning: Performance on downstream tasks
It is important to evaluate them on other datasets with transfer learning in order to measure the power of generalization of DeiT. They evaluated this on transfer learning tasks by fine-tuning on the datasets. The below compares DeiT transfer learning results to those of ViT and state of the art convolutional architectures. DeiT is on par with competitive convnet models, which is in line with our previous conclusion on ImageNet.
The results are not as good as with Imagenet pre-training (98.5% vs 99.1%), which is expected since the network has seen a much lower diversity. However they show that it is possible to learn a reasonable transformer on CIFAR-10 only.
It also performed well without pre-training(scratch) with a small dataset.
The table below is the performance of CIFAR-10, which is small both w.r.t. the number of images and labels:
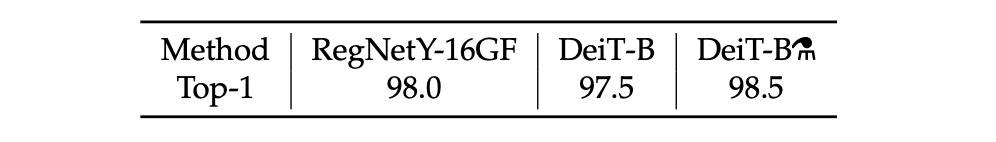
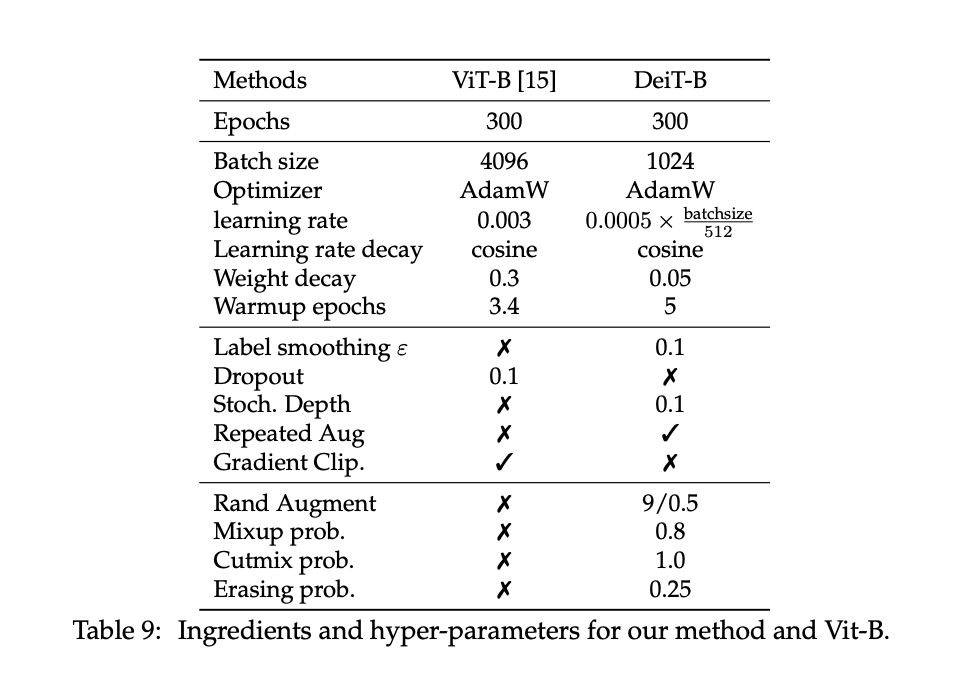
5. Training details & ablation
5.1 Initialization
The transformer is sensitive to initial values, after several test experiments, some of them not converging.
They used the recommendation of Hanin and Rolnick to initialize the weights with a truncated normal distribution.
・Default configuration (unless stated otherwise)
For distillation, they follow the recommendations from Cho et al. The typical values τ = 3.0 and λ = 0.1 for the usual (soft) distillation.
5.2 Data augmentation
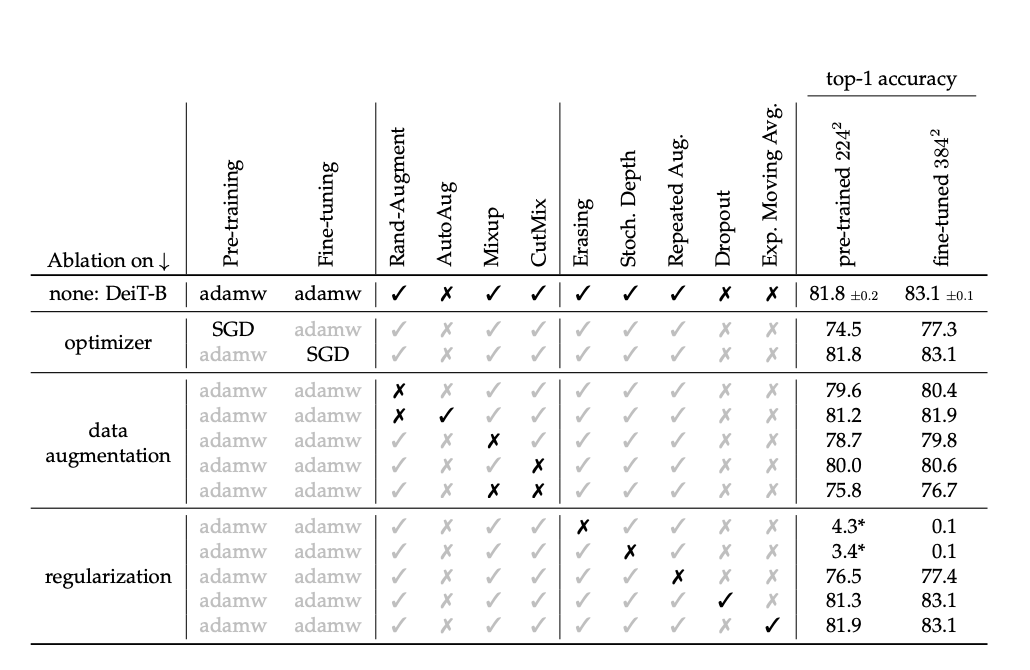
They used Rand-Augment(instead of Auto-Augment by ablation study) and random erasing, which improved the results.
Overall their experiments confirm that transformers require strong data augmentation.
One exception is dropout, which they exclude from their training procedure.
・Ablation study
The hyper-parameters are fixed according to Table 9, and may be suboptimal.
5.3 Optimizers & Regulatization
The best results use the AdamW optimizer with the same learning rates as ViT but with a much smaller weight decay, as the weight decay reported in the paper hurts the convergence in our setting.
We have employed stochastic depth, which facilitates the convergence of transformers, especially deep ones.
Regularization like Mixup and Cutmix improve performance. They also use repeated augmentation, which provides a significant boost in performance and is one of the key ingredients of the proposed training procedure.
5.4 Exponential Moving Average (EMA).
About EMA of the network obtained after training.
There are small gains, which vanish after fine-tuning: the EMA model has an edge of is 0.1 accuracy points, but when fine-tuned the two models reach the same (improved) performance.
5.5 Fine-Tuning
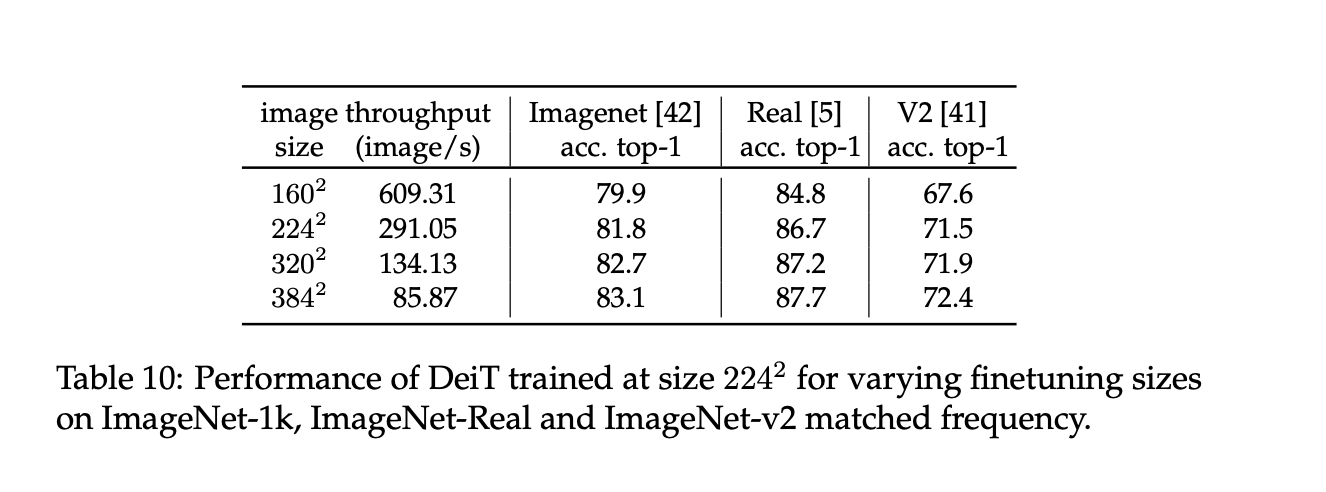
The authors follow a fine-tuning schedule similar to FixEfficientNet but with full data augmentation. When changing resolutions, they interpolate positional embeddings, preferring bicubic interpolation over bilinear to maintain vector norms, which preserves the pre-trained model's accuracy. Using bilinear interpolation can reduce the vector norm, hurting performance. They fine-tune with optimizers like AdamW or SGD and typically train at a resolution of 224x224 before fine-tuning at a higher resolution of 384x384.
Fine-tuned model results for each model are this:
5.6 Training time
Training the DeiT-B model (Base version) for 300 epochs takes 37 hours on 2 nodes or 53 hours on a single node. Compared to a similar model, RegNetY-16GF, DeiT-B's training is about 20% faster.
Smaller models like DeiT-S (Small) and DeiT-Ti (Tiny) can be trained in less than 3 days on 4 GPUs. Fine-tuning DeiT-B at a higher resolution (384x384) takes 20 hours on a single node (8 GPUs) for 25 epochs.
Since DeiT doesn't rely on batch normalization, smaller batch sizes can be used without performance loss, making training of larger models easier. Due to repeated augmentation, only one-third of the dataset is seen per epoch.
6 Conclusion
This is an introduction of DeiT, which are image transformers that
do not require very large amount of data to be trained, thanks to improved training and in particular a novel distillation procedure.
DeiT has started the existing data augmentation and regularization strategies pre-existing for convnets, not introducing any significant architectural beyond their novel distillation token. Therefore it is likely that research on dataaugmentation more adapted or learned for transformers will bring further gains.
It would rapidly become a method of choice considering their lower memory footprint for a given accuracy.
・Inprementation
https://github.com/facebookresearch/deit.
7 Summary
This time, I read the DeiT paper.
DeiT is a new VIT method to handle the problem of VIT requiring a large amount of data.
It incorporates a distillation token and learns from the teacher model's prediction to imitate the ability of the teacher models.
The various normalization and distillation token provide the power that makes VIT able to predict from a lower dataset than usual VIT.
Reference
[1] Training data-efficient image transformers
& distillation through attention
Discussion