【Kaggle】BIrdCLEF2024 4th Solution explained


I'll explain about kaggle's BirdCLEF Competition.
Today's Solution is 4th by team Cerberus(TmT, yokuyama, HB).
Published article yesterday is deleted by mistake operation...
I'll rewrite this article briefly.
0. Competiton Overview
This competition's purpose is classification to the 182 type bird calls.
The validation method is AUC-ROC, so we had to predict all of birds classes.
Competition host provide the random length audio calling data over 240000 samples as training data, and data not labeled for utilize to augmentation or otehrs.
As the problem must be addressed were:
unbalanced data, probably noisy and mixed test data, data while bird not calling, etc..
Additionaly point to be noted is the limitation of submittion. This competition only allow CPU and under 120 minutes for inference. We have to proccess the data and inference in time.
Next, let see the solution of Cerberus.
1. TL;DR
Summary of solution is here.
- Ensemble of Melspec Models and Signal Models
- TTA (test time augmentation)
- OpenVINO
- Post Processing
These are powerfull method for signal data, but I think actual impremetation is difficult.
2. Model's Score
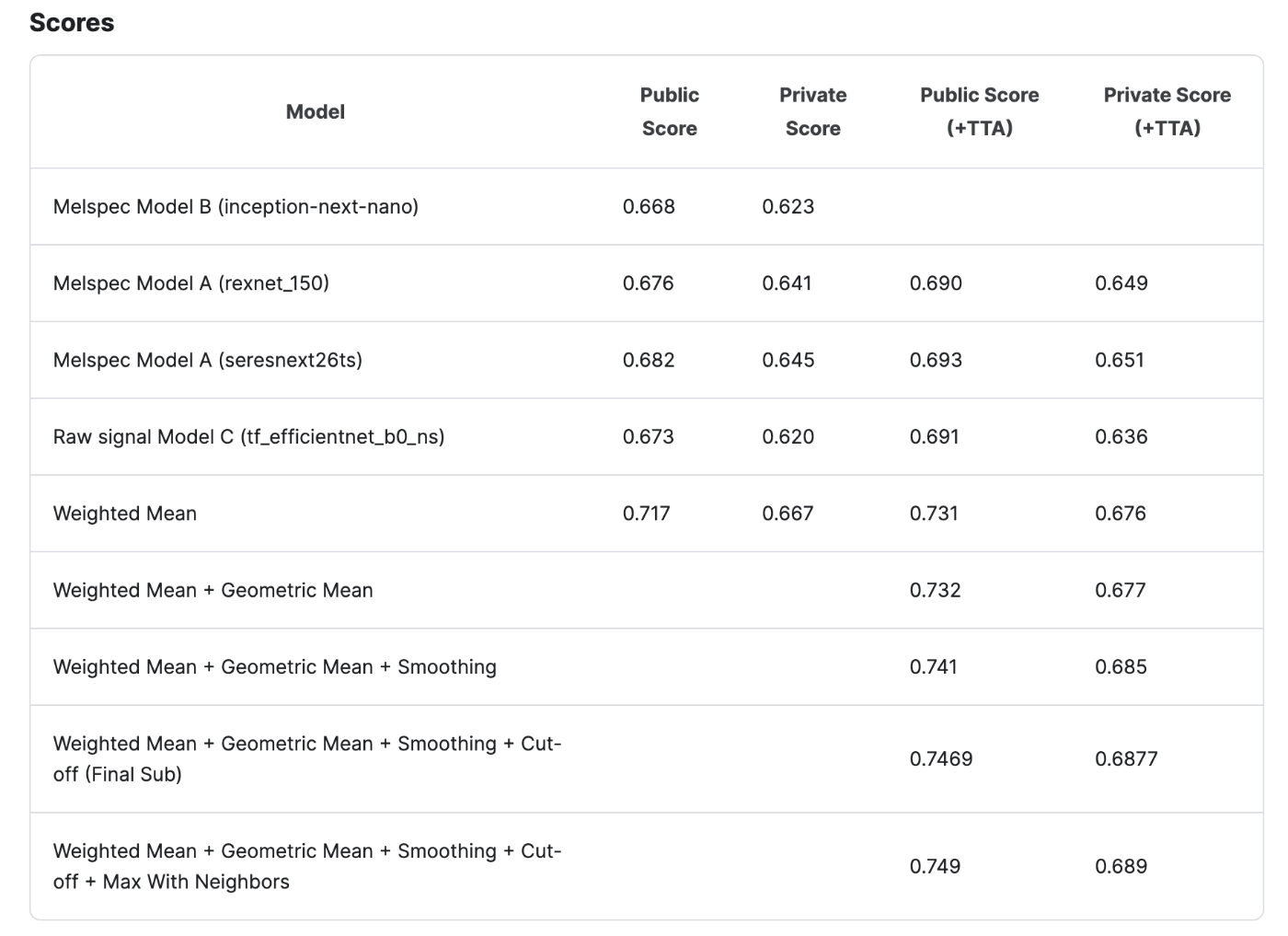
・Weighted Mean
0.15*Model B + 0.25*Model A (rexnet_150) + 0.3*Model A (seresnext26ts) + 0.3*Model C
・Geometric Mean
(0.15*Model B + 0.25*Model A (rexnet_150) + 0.3*Model A (seresnext26ts) + 0.3*Model C) + 0.3*(Model A (rexnet_150) * Model C)**(0.5)
They achived slight improvement by adding Geometric mean component 0.3*(Model A (rexnet_150) * Model C)**(0.5)
Geometric mean is used for growing rate or geometory field calculations.
It seems Model A,C weight is bigger.
3. Models
3.1 Model A: 2021-2nd Melspec CNNs
The authors heavily referenced the code from the 2023 2nd place solution to build their training and inference pipeline for this model. They made a few modifications to create a single model with an LB score of 0.68.
Dataset
- BC2024
- Some models pretrained on 2021, 2022, and 2023's datasets
- Random 15-20 seconds from audio at training, first 5 seconds at validation
Preprocessing
- n_mels=128, n_fft=2048, f_min=0, f_max=16000, hop_length=627, top_db=80
Data Augmentation
- AddBackgroundNoise (datasets)
- Gain
- Noise Injection
- Gaussian Noise
- Pink Noise
- Mixup
Model
- seresnext26ts
- rexnet_150
- 2021-2023 pretrained
Loss Function
- BCELoss
- Class sampling weights proposed by 1st place of 2023 competition
3.2 Model B: Simple Melspec CNNs
Dataset
- BC2024 + xeno-canto-additional-cleaned (see Validation Strategy section)
- Random 5 seconds from audio for training, first 5 seconds for validation
Data Augmentation
- AddBackgroundNoise (datasets)
- Gain
- Noise Injection
- Gaussian Noise
- Pink Noise
- Mixup
- Sumup
Model
- inception-next-nano with attention head
3.3 Model C: Raw signal CNN
This model is inspired by the HMS 2nd place solution.
Dataset
- BC2024
- Removed duplicate data
- Added several samples from the minority class using data from xeno-canto
- Applied stratified 5-fold cross-validation grouped by author
- Classes with fewer than 15 samples were upsampled to 15 samples during training
Preprocessing
- Used the first 5 seconds of each audio sample
- Downsampled the audio to half the original rate (from 32000 Hz to 16000 Hz)
- Reshaped the downsampled audio data from a size of 80000 to 625x128
Data Augmentation
- Annotated 50 background segments from unlabeled data and added them as background noise
- Gain
- Noise Injection
- Gaussian Noise
- Pink Noise
- Random Volume
- Mixup
- Cutmix
Model
- tf_efficientnet_b0_ns with SED head
Loss Function
- Focal loss
4. Validation Strategy
The authors switched to a synthetic data approach for validation.
- Sampled files for 40 out of 182 classes from the xeno-canto-additional dataset and cropped the segments where the birds were vocalizing to create a clean dataset
- Sampled audio files containing only background noise (without bird calls) from the unlabeled soundscape dataset
- Combined the clean dataset and background noise to create a test-like dataset with time-series labels
- Calculated the ROC AUC score using the synthetic dataset
5. TTA
The authors employed sub-pixel super-resolution-like techniques to enhance the accuracy of their time series predictions.
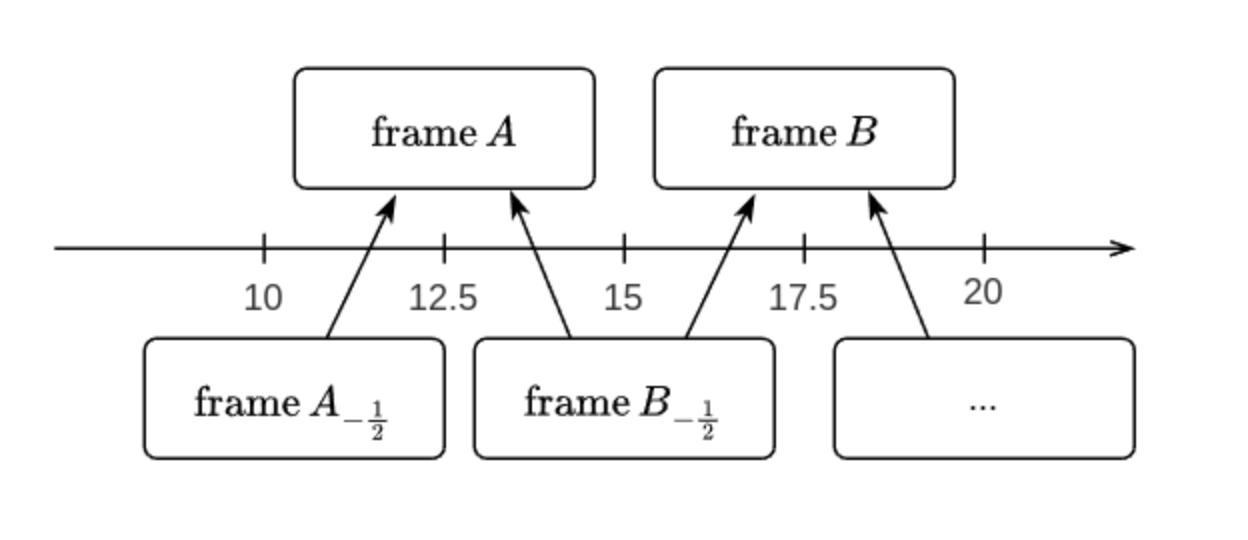
- Predicted 5-second frames and frames shifted by 2.5 seconds during inference
- Combined the results as a TTA
6. OpenVINO + INT8 Post Training Quantization
The authors used OpenVINO and post-training quantization to speed up their model's inference time.
- Used the model's training dataset with augmentations like background noise addition and gain changes for quantization calibration
- Excluded head layers from quantization to improve the model's accuracy
- Achieved 30-40% faster inference speed with the quantized model
7. Post Processing
The authors used several tricks to improve their scores by approximately 0.01 on both the private and public leaderboards.
- Smoothing: Took the moving average of adjacent segments
- Cut-off: Halved the probability if there were no birdsong (0.10 or less) in all 48 sections of the 4-minute audio
- Max With Neighbors: Selected the maximum value including the previous and next two rows
8. What didn't work
- Pseudo labeling using unlabeled data
- Data cleansing and hand-labeling for training data
- Novel loss functions (BCE and Focal Loss performed almost the best)
- Manifold Mixup, D-Mixup
- PCEN
- CWT, CQT, VQT
- Trainable frontends: Leaf, trainable filterbank, trainable stft, Conv1D
- Reparameterized model
- Mobilenet V4
- BirdNET embeddings
9. Point to see
- synthetic validation strategy (chap 4)
- sub-pixel TTA (chap 5)
- INT8 models quantization(faster for 30-40%) (chap 6)
10. Summary
This solution used so many technics and performed great score. I reccomend to read the original solution and upvote for them on kaggle.
Discussion