【PyTorch】学習率スケジューラー解説
今回はPyTorchの学習率スケジューラーを解説します。
1. 学習率スケジューラーとは
学習率スケジューラーを使用することで、モデルの学習中に学習率(パラメータの更新率)を変えることができます。
一般的に、学習の最初は大きな学習率を設定し、後半になるにつれて学習率を低下させることで学習が安定します。
# 学習率スケジューラー
from torch.optim import lr_scheduler
PyTorchは、学習率スケジューラーを利用するための
lr_scheduler
クラスを提供しています。
2. 使い方
for epoch in range(num_epochs):
for batch in dataloader:
# 学習
...
# 学習率の更新
scheduler.step()
各エポックの終わりに
scheduler.step()
を呼び出すことで、学習率が更新されます。
3. 学習率スケジューラー
PyTorchの提供する組み込み学習率スケジューラーをいくつか紹介します。
1. lr_scheduler.LambdaLR
引数: (optimizer, lr_lambda, last_epoch=-1, verbose=False)
# 1. LambdaLR
lambda_scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda epoch: 0.95 ** epoch)
lr_lambdaで指定された関数に基づいて、学習率を更新します。
lr_lambda: 現在のエポック数を引数として受け取り、学習率の倍率を返す関数
例えば、lr_lambda=lambda epoch: 0.95 ** epochとすると、毎エポック学習率が0.95倍に減衰します。
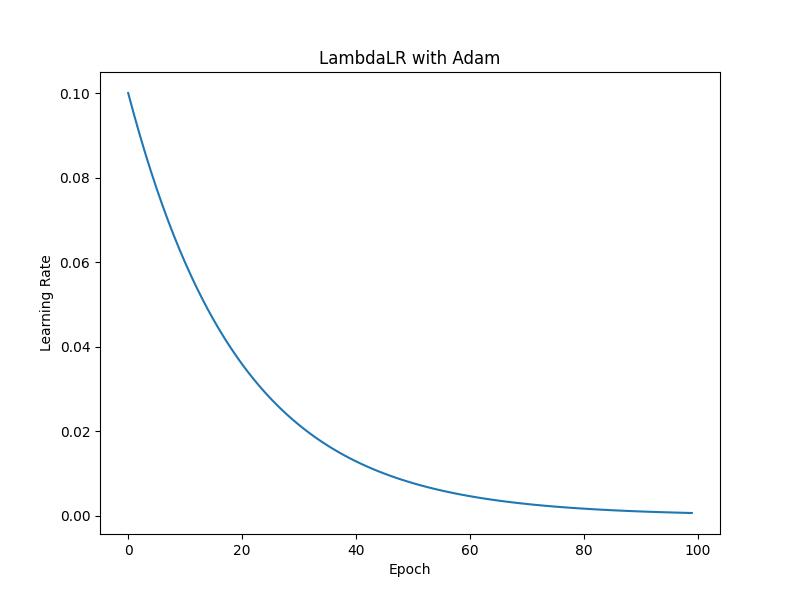
要約: lambdaの返り値が毎エポックの学習率になる
2. lr_scheduler.StepLR
引数: (optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False)
# 2. StepLR
step_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.8)
一定のエポック数(step_size)ごとに、学習率をgamma倍に減衰させます。
例えば、step_size=10、gamma=0.8とすると、10エポックごとに学習率が0.8倍に減衰します。

要約: step_sizeエポック毎に学習率がgamma倍になる
3. lr_scheduler.MultiStepLR
引数: (optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)
# 3. MultiStepLR
multistep_scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[30, 80], gamma=0.1)
指定したエポック数(milestones)に達したときに、学習率をgamma倍に減衰させます。
milestones: 学習率を減衰させるエポック数のリスト
例えば、milestones=[30, 80]、gamma=0.1とすると、30エポックと80エポックで学習率が0.1倍に減衰します。
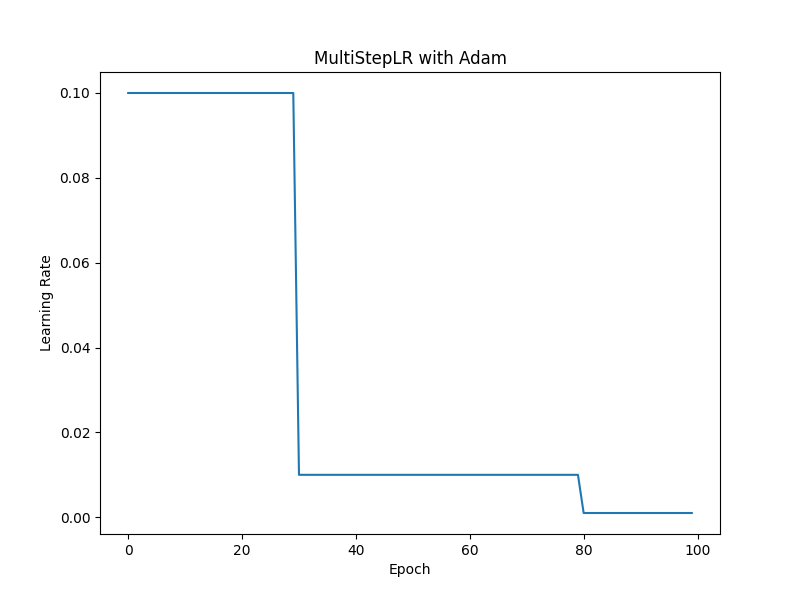
要約: milestonesで指定したエポックで学習率がgamma倍になる
4. lr_scheduler.ExponentialLR
引数: (optimizer, gamma, last_epoch=-1, verbose=False)
# 4. ExponentialLR
exponential_scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.95)
毎エポック、学習率をgamma倍に減衰させます。
gammaは0から1の間の値を指定します。
例えば、gamma=0.95とすると、毎エポック学習率が0.95倍に減衰します。

要約: 毎エポック学習率がgamma倍になる
5. lr_scheduler.CosineAnnealingLR
引数: (optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
# 5. CosineAnnealingLR
cosine_annealing_scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=20, eta_min=0)
コサイン関数に基づいて、学習率を減衰させます。
T_max: 学習率が最小値に達するまでのエポック数です。
eta_min: 学習率の最小値です。
例えば、T_max=20、eta_min=0とすると、20エポックかけて学習率が0に減衰します。

要約: コサイン関数に基づいて、繰り返し学習率を増減させる
6. lr_scheduler.ReduceLROnPlateau
引数: (optimizer, mode='min', factor=0.1, patience=10, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08, verbose=False)
# 6. ReduceLROnPlateau
reduce_on_plateau_scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=10)
指定した評価指標の改善が停滞した場合に、学習率を減衰させます。
mode: 評価指標を最小化する場合は'min'、最大化する場合は'max'を指定します。
factor: 学習率を減衰させる倍率です。
patience: 学習率を減衰させるまでに待つエポック数です。
threshold: 改善と見なされる評価指標の変化量のしきい値です。
threshold_mode: しきい値の解釈方法を指定します。'rel'は相対的な変化量、'abs'は絶対的な変化量を表します。
cooldown: 学習率を減衰させた後、再び減衰させるまでに待つエポック数です。
min_lr: 学習率の下限値です。
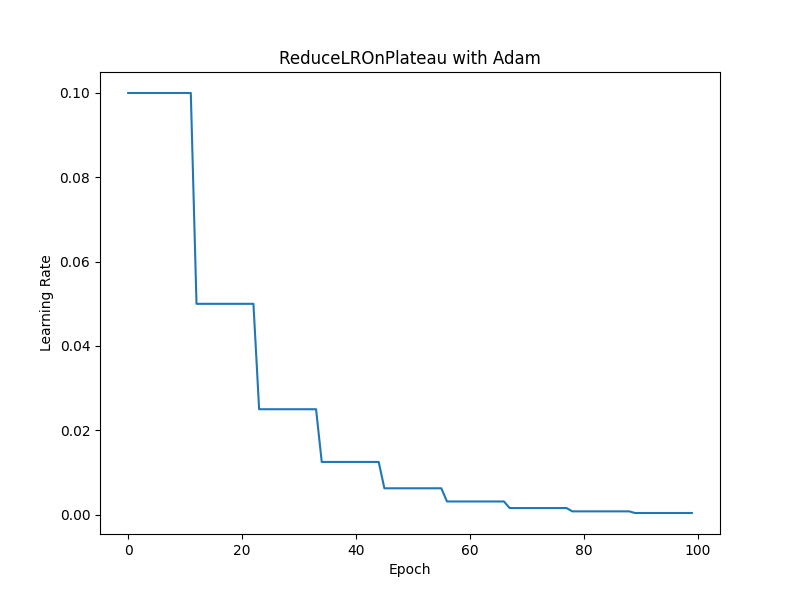
要約: 評価指標が改善しなくなると学習率を減少させる
7. lr_scheduler.CyclicLR
引数: (optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-1, verbose=False)
# 7. CyclicLR
cyclic_scheduler = lr_scheduler.CyclicLR(optimizer, base_lr=0.001, max_lr=0.1, step_size_up=20, mode='triangular')
学習率を、指定した下限(base_lr)と上限(max_lr)の間で周期的に変化させます。
step_size_up: 学習率が下限から上限に達するまでのステップ数です。
step_size_down: 学習率が上限から下限に戻るまでのステップ数です。Noneの場合、step_size_upと同じ値が使用されます。
mode: 学習率の変化のパターンを指定します。'triangular'、'triangular2'、'exp_range'から選択できます。
gamma: 'exp_range'モードで使用され、学習率の減衰率を指定します。
scale_fnとscale_mode: カスタムのスケーリング関数を指定するために使用します。
cycle_momentum: 学習率の変化に合わせてモーメンタム(前回の更新を加速度として利用)を変化させるかどうかを指定します。
base_momentumとmax_momentum: モーメンタムの下限と上限を指定します。
・trianglar
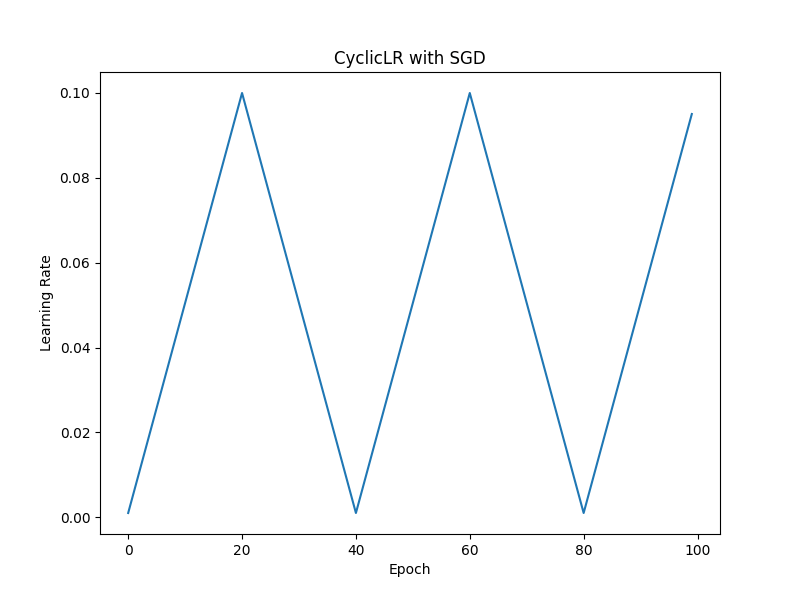
要約: 直線的な学習率の増減を繰り返します
・trianglar2

要約: 直線的な学習率の増減に、全体的な減少が追加されます
・exp_range

要約: 対数関数的な学習率の増減に、全体的な減少が追加されます
8. lr_scheduler.OneCycleLR
引数: (optimizer, max_lr, total_steps=None, epochs=None, steps_per_epoch=None, pct_start=0.3, anneal_strategy='cos', cycle_momentum=True, base_momentum=0.85, max_momentum=0.95, div_factor=25.0, final_div_factor=1e4, last_epoch=-1, verbose=False)
# 8. OneCycleLR
one_cycle_scheduler = lr_scheduler.OneCycleLR(optimizer, max_lr=0.1, total_steps=10000, pct_start=0.3, anneal_strategy='cos')
OneCycle学習率スケジューリングを実装します。
最初に急激に学習率を増加させ、徐々に減少させます。通常繰り返されることはなく、全体で1つのサイクルを実行します。これは、短い期間で良好な結果を得るために設計されています。
max_lr: 学習率の最大値です。
total_steps: 学習の総ステップ数です。epochsとsteps_per_epochが指定されている場合は、それらの積が使用されます。
pct_start: 学習率が最大値に達するまでのステップ数の割合です。
anneal_strategy: 学習率を増減させる方法を指定します。'cos'または'linear'を選択できます。
cycle_momentum: 学習率の変化に合わせてモーメンタム(前回の更新を加速度として利用)を変化させるかどうかを指定します。
base_momentumとmax_momentum: モーメンタムの下限と上限を指定します。
div_factorとfinal_div_factor: この数でmax_lrを割ることで、初期学習率と最終学習率を決定します。

9. カスタムスケジューラー
torch.optim.lr_schedulerクラスを継承して、学習率スケジューラーを自作することができます。
import torch
from torch.optim.lr_scheduler import _LRScheduler
class CustomLRScheduler(_LRScheduler):
def __init__(self, optimizer, last_epoch=-1):
super(CustomLRScheduler, self).__init__(optimizer, last_epoch)
self.base_lrs = [0.1]
def get_lr(self):
if self.last_epoch < 10:
return [lr * (1 - 0.1 * self.last_epoch) for lr in self.base_lrs]
else:
return [lr * 0.1 for lr in self.base_lrs]
# 使用例
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = CustomLRScheduler(optimizer)
for epoch in range(20):
optimizer.step() # パラメータの更新
scheduler.step() # 学習率の更新
print(f"Epoch {epoch}: Learning Rate is {scheduler.get_last_lr()[0]}")
学習率スケジューラーを自作する場合、引数としてoptimizerとlast_epochを受け取り、superで親クラスのメソッドを呼び出します。
last_epoch: 現在のエポック数を示す。step()が呼ばれるたびにインクリメントされます
またget_lrでは次の学習で使用する学習率をリストで返します。リストで返すのは、層ごとに学習率を変更したい要求などに対応するためで、一般的には単一要素を持つリストが返されます。

要約: last_epochとoptimizerを受け取って、get_lr()で[学習率]を返す
4. 使い方(再)
再度使い方を解説します。
学習ループ内で呼び出すことで、以降の学習率が変更されます。
通常、エポック毎に呼び出して学習率を調整します。
Copy code
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
for epoch in range(num_epochs):
for batch in dataloader:
# 学習の実装
...
#ここで学習率を更新
scheduler.step()
要約: scheduler.step()を呼び出すことで、以降の学習率が変更される
5. まとめ
今回は学習率スケジューラーについて解説しました。
実際には様々なスケジューラーを試し、より良い結果となるものを選択すると良いでしょう。
補遺
学習率可視化コード
import torch
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import matplotlib.pyplot as plt
def plot_scheduler(scheduler_class, optimizer_class, scheduler_params, optimizer_params, epochs, option_name=''):
optimizer = optimizer_class([torch.tensor(0.0, requires_grad=True)], **optimizer_params)
scheduler = scheduler_class(optimizer, **scheduler_params)
lr_log = []
for epoch in range(epochs):
lr_log.append(optimizer.param_groups[0]['lr'])
scheduler.step()
plt.figure(figsize=(8, 6))
plt.plot(range(epochs), lr_log)
plt.title(f"{scheduler_class.__name__} with {optimizer_class.__name__}")
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.savefig(f'{scheduler_class.__name__}' + f'{option_name}' + '.png')
plt.show()
# LambdaLR
plot_scheduler(lr_scheduler.LambdaLR, optim.Adam, {'lr_lambda': lambda epoch: 0.95 ** epoch}, {'lr': 0.1}, 100)
# StepLR
plot_scheduler(lr_scheduler.StepLR, optim.Adam, {'step_size': 10, 'gamma': 0.8}, {'lr': 0.1}, 100)
# MultiStepLR
plot_scheduler(lr_scheduler.MultiStepLR, optim.Adam, {'milestones': [30, 80], 'gamma': 0.1}, {'lr': 0.1}, 100)
# ExponentialLR
plot_scheduler(lr_scheduler.ExponentialLR, optim.Adam, {'gamma': 0.95}, {'lr': 0.1}, 100)
# CosineAnnealingLR
plot_scheduler(lr_scheduler.CosineAnnealingLR, optim.Adam, {'T_max': 20, 'eta_min': 0.001}, {'lr': 0.1}, 100)
# ReduceLROnPlateau
optimizer = optim.Adam([torch.tensor(0.0, requires_grad=True)], lr=0.1)
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=10)
lr_log = []
for epoch in range(100):
lr_log.append(optimizer.param_groups[0]['lr'])
scheduler.step(epoch)
plt.figure(figsize=(8, 6))
plt.plot(range(100), lr_log)
plt.title("ReduceLROnPlateau with Adam")
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.savefig('ReduceLROnPlateau.png')
plt.show()
# CyclicLR-triangular
plot_scheduler(lr_scheduler.CyclicLR, optim.SGD, {'base_lr': 0.001, 'max_lr': 0.1, 'step_size_up': 20, 'mode': 'triangular'}, {'lr': 0.1, 'momentum': 0.9}, 100, '-1')
# CyclicLR-triangular2
plot_scheduler(lr_scheduler.CyclicLR, optim.SGD, {'base_lr': 0.001, 'max_lr': 0.1, 'step_size_up': 20, 'mode': 'triangular2'}, {'lr': 0.1, 'momentum': 0.9}, 100, '-2')
# CyclicLR-exp_range
plot_scheduler(lr_scheduler.CyclicLR, optim.SGD, {'base_lr': 0.001, 'max_lr': 0.1, 'step_size_up': 20, 'mode': 'exp_range', 'gamma': 0.95}, {'lr': 0.1, 'momentum': 0.9}, 100, '-exp')
# OneCycleLR
plot_scheduler(lr_scheduler.OneCycleLR, optim.SGD, {'max_lr': 0.1, 'total_steps': 100, 'pct_start': 0.3, 'anneal_strategy': 'cos'}, {'lr': 0.1, 'momentum': 0.9}, 100)
Discussion