【ML Paper】DeiT: There are only fewer images for ViT? Part4
The summary of this paper, part4.
The authors proposed an improved Vision Transformer, DeiT(Data-Efficient image Transformer)
Original Paper: https://arxiv.org/abs/2012.12877v2
4. Experiments
Some experiments results.
They proposed the three models DeiT-B(Based on ViT-B), DeiT-S, DeiT-Ti(smaller models).
・Variants of models

The only parameters that vary across models are the embedding dimension and the number of heads, and it keeps the
dimension per head constant (equal to 64). Smaller models have a lower parameter count, and a faster throughput. The throughput is measured for images at resolution 224×224.
・Model comparison
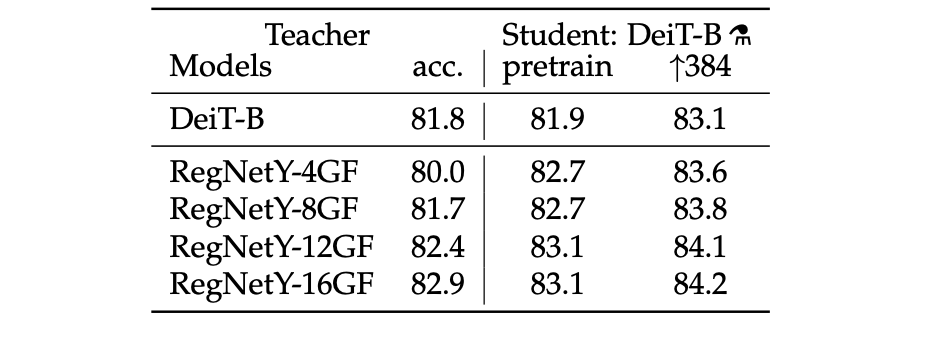
4.1 Convnets teachers
Models using the convolution layer as teacher outperform transformer models.
The fact that the convnet is a better teacher is probably due to the inductive bias inherited by the transformers through distillation, as explained in Abnar et al.
In all of their subsequent distillation experiments, the default teacher is a RegNetY-16GF [40] (84M parameters) that they trained with the same data and same data-augmentation as DeiT. This teacher reaches 82.9% top-1 accuracy on ImageNet.
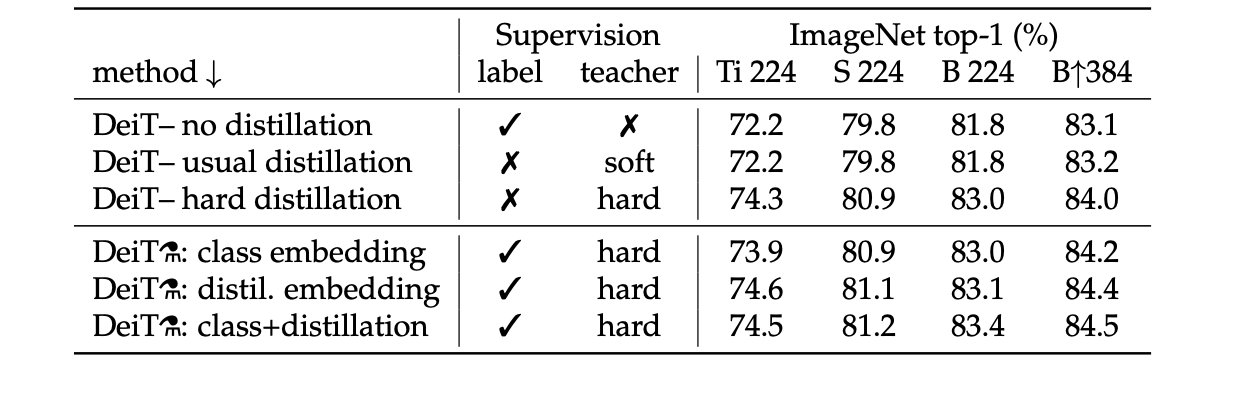
・ Distillation experiments on Imagenet with DeiT, 300 epochs of pertaining.
They separately report the performance when classifying with only one of the class or distillation token embeddings, and then with a classifier taking both of them as input.
Discussion