【ML】Swin Transformer V2 explained


Swin Transformer V2
Changes from Swin Transformer
The main changes from Swin Transformer are the following three.
• Changed the position of Layer Normalization.
• When using Attention, instead of simply taking the inner product, scale it by a learnable parameter 𝜏.
• Generate Relative Position Bias using MLP.
• Here, the relative position is scaled logarithmically.
With these improvements, we succeeded in making the model larger.
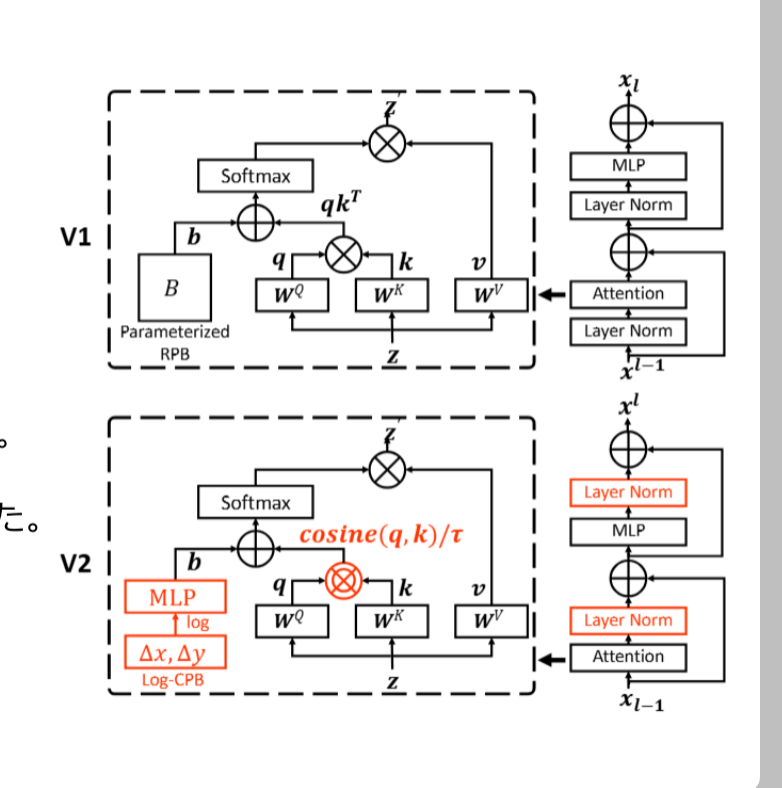
Post normalization
About the position of the normalization layer.
Conclusion: Normalizing after attention is less likely to increase the variance → stable
By changing to post-norm, the problem of the activation value increasing as the layer becomes deeper is solved. Learning becomes unstable if there is a difference in the magnitude of the activation value in each layer.
Scaled cosine attention
Especially in the case of post-norm, some pixel pairs often have a large impact on the whole.
To alleviate this problem, scaled cosine attention is used.
𝑆𝑖𝑚(𝒒𝑖 𝒌𝑗) = cos(𝒒𝑖,𝒌𝑗)/𝜏 +𝐵𝑖𝑗
𝜏 is a trainable scaler of 0.01 or more, and is independent for each head and layer.
Since it is normalized by cosine, the attention value does not become extreme.
Continuous relative position bias
Relative Position Bias: Instead of optimizing 𝐵 directly, generate it using MLP (by default, two layers with ReLU in between).
𝐵(∆𝑥,∆𝑦) = 𝒢(∆𝑥,∆𝑦)
𝒢 can generate 𝐵 continuously for any relative position, so it can respond to changes in window size.
However, in order to change the window size significantly (when fine-tuning from a pre-trained model with a small window to a model with a large window), the relative position coordinates are scaled using a logarithm as shown below (Log-spaced coordinates).

Ablation Study
Performance is improved by post-norm and scaled cosine attention. The effect of log-spaced coordinates is more pronounced as the difference in image size and window size increases before and after fine-tuning.

Summary
Summary of Swin Transformer and Swin Transformer V2
- Swin Transformer is an improvement of Vision Transformer to capture changes in object scale and process high-resolution images.
- Patch merging gradually changes patch size.
- Attention is calculated only within shifted windows.
- Swin Transformer V2 is an improvement of Swin Transformer to allow the model to be larger.
- Post-norm and scaled cosine attention suppress activation values.
- Continuous relative position bias supports enlarging window size.
Discussion