【ML Paper】DeiT: There are only fewer images for ViT? Part6
The summary of this paper, part6.
The authors proposed an improved Vision Transformer, DeiT(Data-Efficient image Transformer)
Original Paper: https://arxiv.org/abs/2012.12877v2
4.6 Efficiency vs Accuracy
The image classification methods are often compared as a compromise between accuracy and another criterion, such as FLOPs, number of
parameters, size of the network, etc.
The proposed method DeiT is slightly below EfficientNet, which shows that we have almost closed the gap between vision transformers and convnets when training with Imagenet only. These results are a major improvement (+6.3% top-1 in a
comparable setting) over previous ViT models trained on Imagenet1k only.
Furthermore, when DeiT benefits from the distillation from a relatively weaker RegNetY to produce DeiT⚗, it outperforms EfficientNet. It also outperforms by 1% (top-1 acc.) the Vit-B model pre-trained on JFT300M at resolution 384 (85.2% vs 84.15%), while being significantly faster to train.
・Throughput(images processed per second) on and accuracy
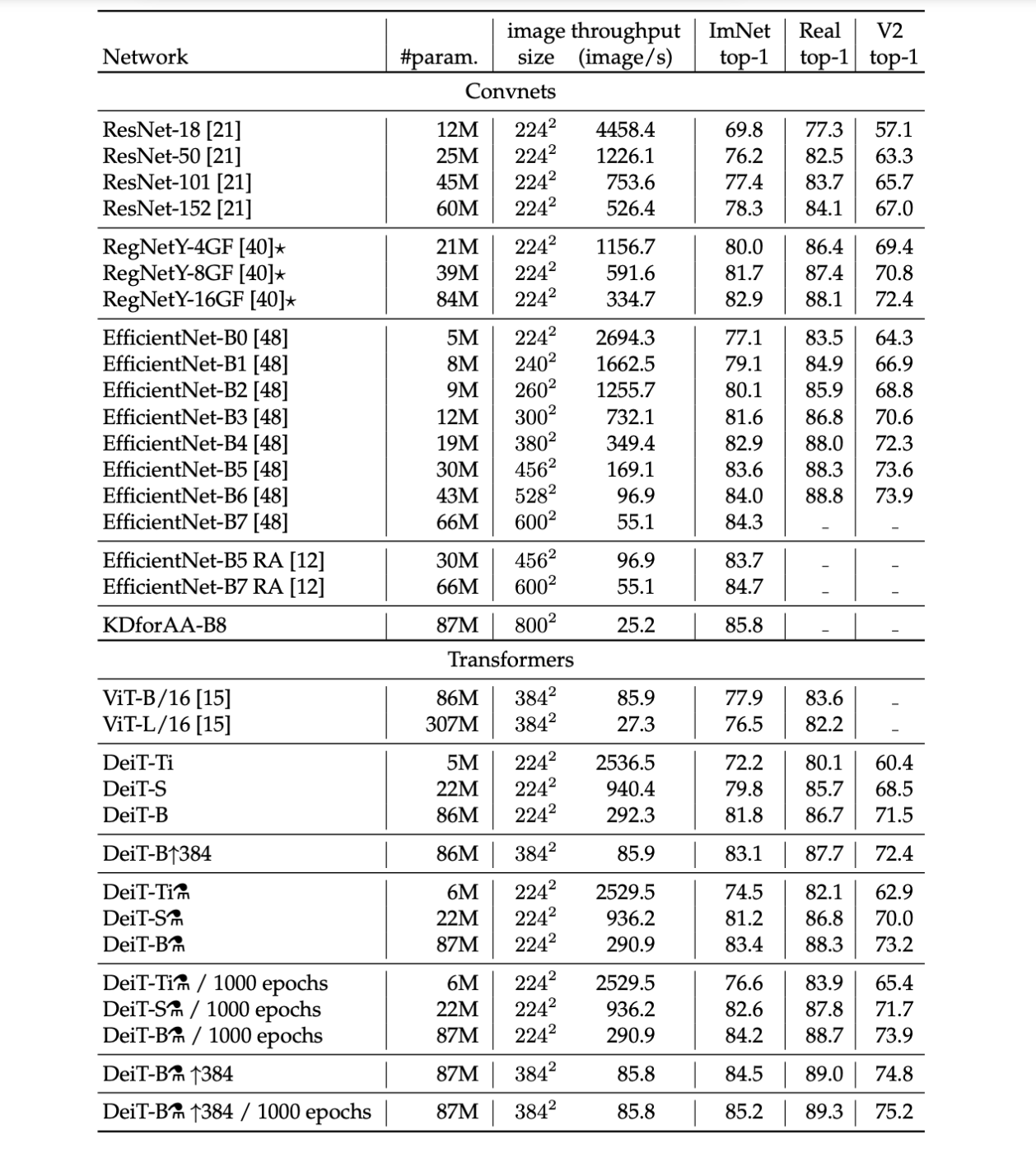
・The throughput is measured as the number of images that we can process per second on one 16GB V100 GPU.
・take the largest possible batch size.
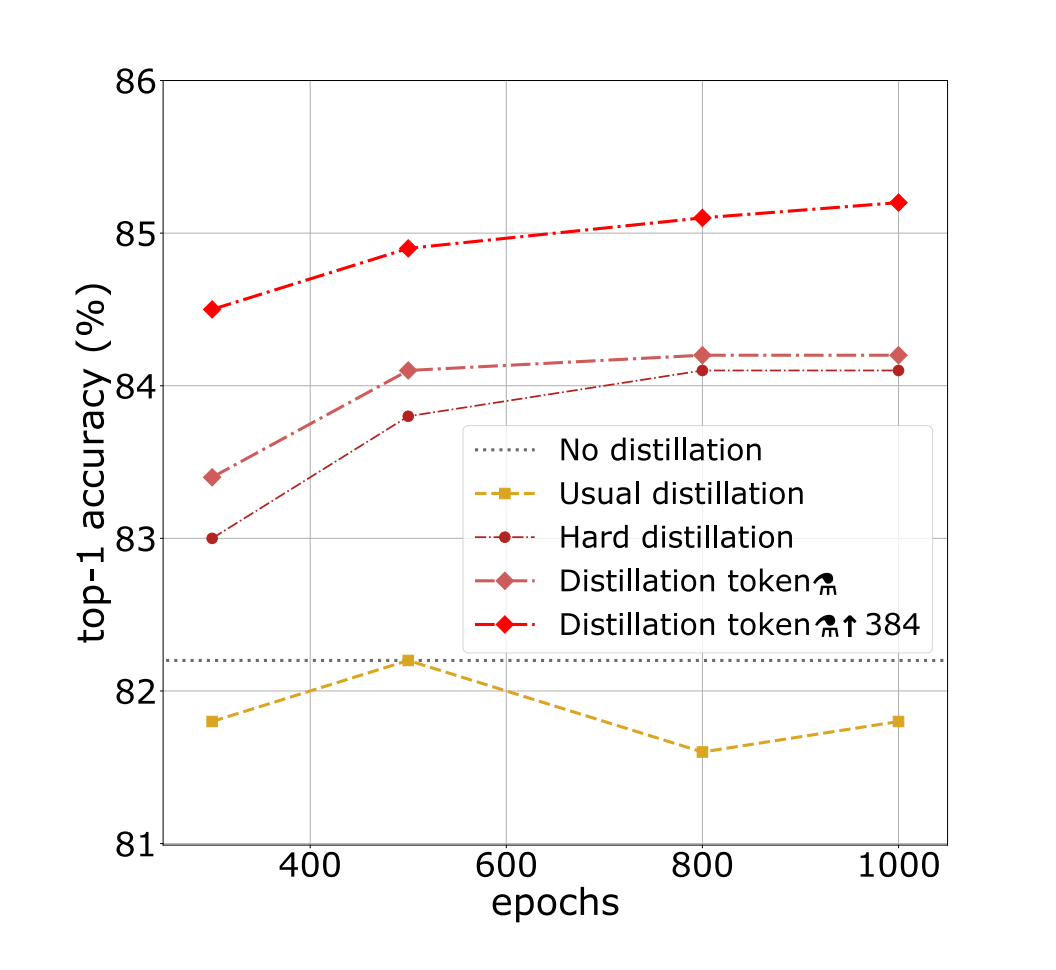
・ Distillation on ImageNet with DeiT-B: performance as a function of the number of training epochs. The model without distillation saturates after 400 epochs(straight line).
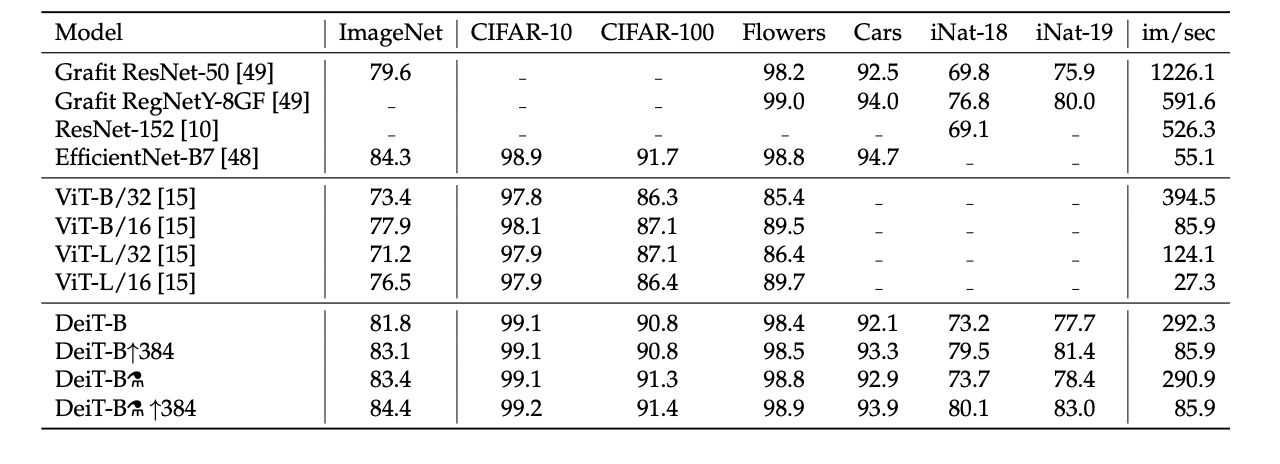
4.7 Transfer learning: Performance on downstream tasks
It is important to evaluate them on other datasets with transfer learning in order to measure the power of generalization of DeiT. They evaluated this on transfer learning tasks by fine-tuning on the datasets. The below compares DeiT transfer learning results to those of ViT and state of the art convolutional architectures. DeiT is on par with competitive convnet models, which is in line with our previous conclusion on ImageNet.
The results are not as good as with Imagenet pre-training (98.5% vs 99.1%), which is expected since the network has seen a much lower diversity. However they show that it is possible to learn a reasonable transformer on CIFAR-10 only.
It also performed well without pre-training(scratch) with a small dataset.
The table below is the performance of CIFAR-10, which is small both w.r.t. the number of images and labels:
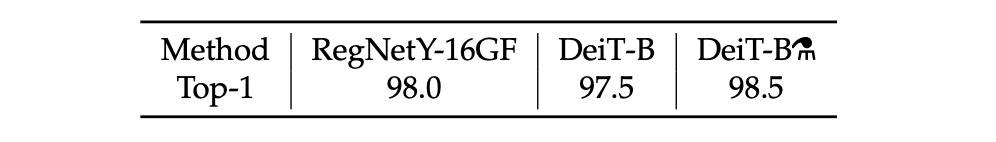
Discussion