ゴリラで学ぶ交差エントロピー誤差
今回は交差エントロピー誤差について解説します。
交差エントロピー誤差:
Σがあると分かりづらいので中の要素だけを見てみると、
ここで
これを踏まえて
キリンとゾウについてはt=0のためE=0
ゴリラは
ちなみにlogのグラフは以下のようになっており、yの値(x軸)が0に近づくほど、大きくマイナスになっていくことが分かります。

さて、元々の交差エントロピー誤差は
これはゴリラ要素の
また上の図から分かるように、yが0に近づくほど大きくなり、予測値(0~1)が1に近づく(ゴリラである確率が高い)ほどEは小さくなります。
まとめ
交差エントロピー誤差は、正解ラベルに対する予測値のみで決まり、その値はlog(y)の負の数となる。つまり予測値の変化に対して、以下のグラフのような値になります。(最高値は1)
・交差エントロピー誤差
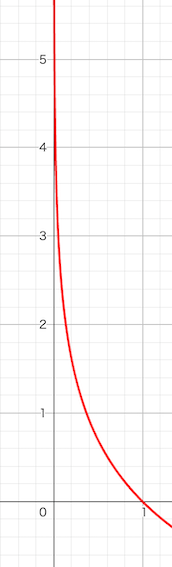
この特性から、「予測値が正解に近いほど、値が小さくなっていく」という損失関数としての役割を果たしています。
正解データが1に近いほど交差エントロピー誤差は小さくなるので、間接的に他の予測データが0に近づくように学習されるのです。
説明は以上です。間違いがありましたら教えて下さい!誰かの役に立っていれば幸いです!
Discussion