【Kaggle】BirdCLEF2024 3rd place Solution explained
Hi, this time I will explain the team NVBird's 3rd solution of BridCLEF2024 to understand it deeper.
0. Competiton explanation
This competition's purpose is classification to the 182 type bird calls.
The validation method is AUC-ROC, so we had to predict all of birds classes.
Competition host provide the random length audio calling data over 240000 samples as training data, and data not labeled for utilize to augmentation or otehrs.
As the problem must be addressed were:
unbalanced data, probably noisy and mixed test data, data while bird not calling, etc..
Additionaly point to be noted is the limitation of submittion. This competition only allow CPU and under 120 minutes for inference. We have to both infer and process the data in time.
If you wanna know details, reccoemnd you check the competition overview and dataset.
0.1 Technique used
- Additive mixup: The labels used are max of each label.
- Normalization with std of 1
- Efficientvit-b0 and mnasnet
- Large batch size to fit models pseudo labeled datasets.
0.2 Point to see
- Restrict the number of records per species to 500 for balanced data.
- AVES model : recent waveform based model
- mnasnet-100 as light CNN (model that NAS applied to MobileNetV2)
- Masking Loss for secondary labels and it improves LB by about 0.01
- Predict smoothing by weight [0.1, 0.2, 0.4, 0.2, 0.1]
1. Overview
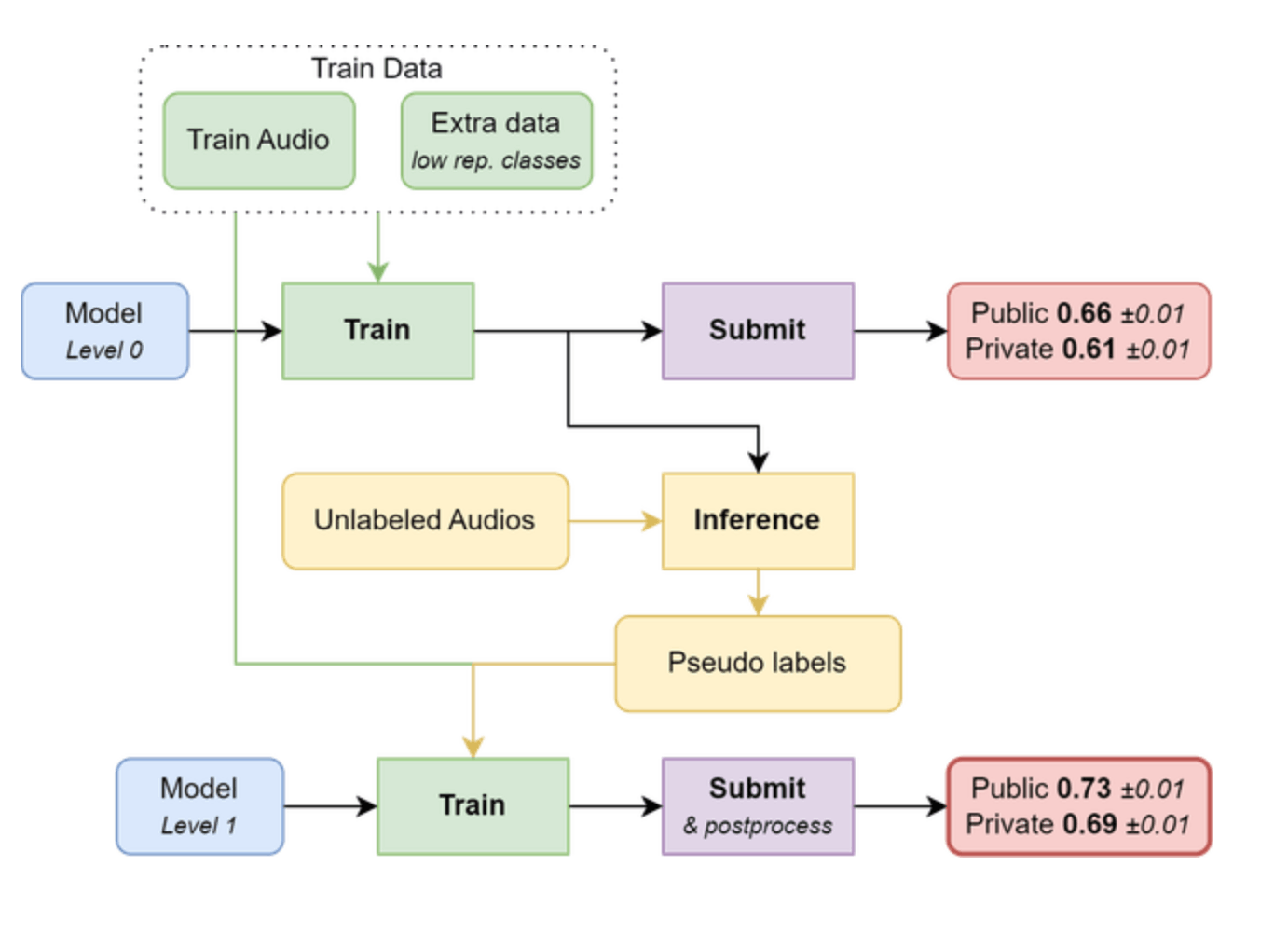
Their pipeline is summarized below.
Key ingredient:
- pseudo labeling with soundscape
- model distillation
A number of models were trained with the training data, then used to predictt lables on 5 second clips from unlabelled soundscapes. These were added to the orginal training data to train a new set of models used for the final submission.
2. Data
Overall, they referenced to knowledge acquired during previous competitions, and added some extra samples to fight class imbalance.
they used previous years data and data on Xeno Canto as additional data.
They capped the number of records per species to 500, keeping the most recent ones. Indeed, adding all extar data leads to severe class imbalance that was detrimental to model accuracy.
Low frequency classes are upsampled so that there are at least 10 samples for each class in the training folds.
To train models, they use the following processing and augmentations:
They didn't use all training data. For each record we use a random crop of 5 seconds clip among the first 6 seconds, or the last 6 seconds of a record. If record length is smaller than 5 seconds, random padding so that the middle of the signal is between 2 and 3 seconds in the 5 sec resulting clip.
For most of th emodels they used time shifting with a one seconds window as the only augmentation besides mixup. An exception are some models which are inspired by BirdCLEF2023 2nd place SED models use the same augmentaion as used there.
They use additive mixup: primary lables are the max of primary labels of the two audios to be mixed. Secondary labels are the concatenation of secondary labels.
We mostly use image models that take log mel spectrograms as input. For these we compute mel spectrograms with parameters chosen to have an image size of 224x224 or 288x288 depending on the image model we use. Input waveforms are normalized to have a std of 1.
3. Models
3.1 First level models
The cup-only environment quite restrict to submission, but this doesn't apply for pseudo label generation, so they used some big backbones than 2nd level. Then, they perform what is known as modle distillation. This is a powerful techniques in general.
Models:
- Efficientvit_b0.224.in1k on 224x224 log mel spectrograms
- Efficientvit_b1.r288_in1k on 288x288 log mel spectrograms
- A variety of CNNs (efficientnets, mobilenets, tinynets, mnasnets, mixnets) and Efficientvits (b0, b1, m3 trained on 224x224 log mel spectrograms.
- SED model with tf_efficientnetv2_s_in21k on 128x313log mel spectrograms?
- They also fine-tuned aves-large and aves-base, which is a recent waveform based model.
Depending on the pipeline one or more of there models were used to predict pseudo labes on unlabelled soundscapes. They trained most models on full data with 5 different seeds.
3.2 Second label models
They used efficientvit-b0 primarily and mnasnet-100 on 224x224 log mel spectrograms. efficientvet-b0 showed great performances while still being very fast to infer. 5folds take 40 minutes to submit using ONNX.
They tried sevral models with similar throughput to effeffvit-b0, and decided to also use an mnasnet-100 for diversity.
They used same mel hyper params whole time because it take long time when using different params to all signals.
For training second level models we added the unlabelled soundscapes with the predicted pseudo labels to the training data. This looks simple but it took several attempts to find the correct way to do it. What worked fine was to use rather large batch sizes(128. 256 seemed to lower performance hence they stopped at 128),
They used the two folloeing strategies:
- Add extra soundscapes to each batch. Each soundscape is split into 5 second clips, which means we added 48 x 4 = 192 clips with pseudo labels to the 128 samples with actual labels in each batch.
- Add 128 samples with pseudo labels, taken from random soundscapes this time.
4. Final ensemble
At the end they had an ensemble of 14 model weights via 3 pipelines, one pipeline per team member:
Pipeline 1 - 5 seeds
- Level 0: efficientvit_b0
- Level 1: efficientvit_b0
Pipeline 2 - 2 seeds + 2
- Level 0: efficientvit_b1, mobilenetv2, efficientnet_b0, efficientnetv2_b0, efficientvit_b0, efficientvit_m3, aves-base, aves-large
- Level1 2x mnasnet-100
- Level 0: Efficientvit_b0, mixnet_s, mnasnet_100, tinynet_b, efficientvit_b0, efficientvit_b1, mobilenetv3
- Level 1: 2x efficientvit_b0,
Pipeline 3 - 5 seeds
- Level 0: efficientvit_b1_288, 5x efficientnet_v2_s sed, aves-base, aves-large
- Level 1: 5x efficientvit_b0
That ensemble scored 0.689970 private, and 0.742124 public.
5. Training
It was a bit tricky to tweak parameters without a validation set. They have two training pipelines with different parameters, and it is rather unclear what actually mattered.
They used BCEWithLogitLoss, without any smoothing. Labels ware defined by primary labels, and the secondary labels were ignored because it is uncertainly and includes risk that model trains incorrect direction.
They mask the loo for those, so secondary labels info is not used for backpropagation. Masking secondary label loss improves LB by about 0.01
They didn't use early stopping, using last epoch one.
6. Post Processing
They used several post processing, to incorporate soundscape-level infromation.
6.1 Enhance the birds appered
The first one worked well on public LB with a 0.02 boost initially. Experiments after competition end show that its effect is much smaller (0.004 on our best unselected submission), and even detrimental on our best selected submission (- 0.002). The idea is that if a bird appears anywhere in the soundscape then its probability to appear in any 5 second slice is increased.
For a given soundscape, once they have a 48x182 logits array or predictions P, they compute the maximum P_max of P over the time dimension. They then replace P with:
P + (P_max + P.mean() - P_max.mean()) * 0.8.
・example code
import numpy as np
# Example logits array P (48x182)
P = np.random.rand(48, 182)
# Compute maximum over time dimension (P_max)
P_max = np.max(P, axis=0)
# Compute mean of P and mean of P_max
P_mean = np.mean(P)
P_max_mean = np.mean(P_max)
# Adjust predictions
P_adjusted = P + (P_max + P_mean - P_max_mean) * 0.8
# P_adjusted now contains the adjusted logits
The 0.8 weight can be tuned further.
6.2 Predict smoothing
The second postprocessing had a smaller impact on LB the first time it was tried but it had a larger impact of +0.01 on our best selected sub. The idea is to smooth predictions for each 5 second clip by blending it a bit with the previous two and the following two clips. They used a convolution for smoothing predictions with the kernel [0.1, 0.2, 0.4, 0.2, 0.1].
7. What didn't work
7.1 About reliable CV
A lot. Main issue was that they could not find a reliable local validation scheme. They mainly looked at train data cross-validation like most of the participants, but also put some effort in looking at past BirdCLEF train / test differences individually for each yaer.
They thought that this might help to understand what augmentations might be bridging the train (= xeno-canto) / test (= PAM soundscape recordings) gap. However, the results were quite inconclusive. Probably because soundscapes are quite different each year. Whatever they tried lost correlation with the public LB once scores were high enougth.
7.2 P boost post processing
One thing that seemed to work great and didn't in the end was the post processing based on max probability per soundscape.
7.3 aves model
Another one was the Aves model which improved public LB by about 0.01 each time it was used, but appeared to be detrimental on private LB.
7.4 augmentation
They tried a number of augmentations, including those documented in previous competitions or in academic papers, but noneseemed to really help.
7.5 ONNX and Openvino
ONNX did not bring much speedup (maybe 10%) and Openvino was much faster (almost 2x speedup compared to pytorch). However they noticed a drop of about 0.01 when using Openvino compared to ONNX, and decided not to use it. Maybe the speedup from openvino would have been compensated by the larger number of models we could use in the final ensemble?
7.6 Model choice
Their final model selection seems did not work that well in the end. they had individual models submitted with private scores above 0.70, but they did not include them in our ensemble given their relatively low public scores.
Summary
This was a 3rd place solution of BirdCLEF2024.
The strong point I think is this:
- Using soundscape data with psuedo label, and making it work with large batch size or more adjustment
- Balaneced data from restriction 500 samples and upsampling to 10 with few labeled data
- Predict smoothing by weight [0.1, 0.2, 0.4, 0.2, 0.1]
Authors performed great work. I reccomend you see the original solution and upvote them.
Reference
[1] CPMP, christofhenkel, theoviel. 2024. BirdCLEF2024 3rd solution
Discussion