Neurips ADC 2024 上位解法簡易まとめ
今回は簡易的にNeurips2024の解法をまとめていきます。
(10thまで。1stと4thは解法未発表)
他に、気になっているもの(2nd,6th,18th等)は後で個別に記事にしようと考えています。
0. 全体の印象
・ノイズに対処するためのSavitzky-GolayフィルターやPCAによるスムージング(ノイズ除去)が広く使用されている(ほぼ全チーム)。欠損値の補完も大切そう(2,7th)
・基本的には多項式fittingが良い結果を出している(3,5,6,7,8,9,10th)
・2nd(データをノイズやトレンド、信号に分解し、ガウスプロセスでモデル化)と5th(データを分子スペクトルに分解、モデルで予測)は上手く合成データの解析に成功している
・予測値のstdによるsigmaの推定がうまくいっていそう(5,9th)
・transitの入り口と出口は、ガウスフィルタによる畳み込みや信号の導関数を使用(3, 10th)
1. Solutions
2nd: https://www.kaggle.com/competitions/ariel-data-challenge-2024/discussion/543853
・検出器のノイズ、ドリフト、transit深さなどを分解できると考えてそれぞれをベイズ推定でモデル化。
・欠損値に対して線形補完。意味のない値がバイアスにならないように。
・最終的にtransit深さをハイパラとして、勾配降下でGPを解く。
・機械学習は使用していない。

code: https://www.kaggle.com/datasets/jeroencottaar/my-ariel-library
3rd: https://www.kaggle.com/competitions/ariel-data-challenge-2024/discussion/543944
・信号強度が50%以上のもののみを使用→4%のノイズ削減
・トランジット外の信号の平均と分散を使用してSNRを計算し、SNRによって重み付け
・transitの入り口と出口を消去したデータ(transitには係数をかける)の5次多項式fitting
・ガウシアンフィルタの畳み込みによるtransitの検出ガウシアンフィルタの可視化

・次数 2、4、5 を順に評価し、次数の 2 乗でペナルティを課した RMS 誤差が最も大きい次数を選択→これにより過適合を軽減
・最後にノイズ低減のためにPCA
5th: https://www.kaggle.com/competitions/ariel-data-challenge-2024/discussion/543760
・合成データだったためデータの確認とlight curveのモデリングに注力。(合成データコンペの定石とのこと)
・既知の分子の吸収スペクトルと重ね合わせると、trainのlabelが H2O、CO2、および CH4 の混合物で構成されていることが分かる。しかしこれらを利用して予測するモデルを作ると、ローカルに過剰適合する。このことから未知の分子がtestに存在する。
・従って、より多くのデータを生成してトレーニングセットをより多くの分子に拡張することで、ここ数日で LB スコアが大幅に向上。Taurex3によって分子の吸収スペクトルを定義、さらに 9 つの分子の吸収スペクトルを生成 (all_molecules = [(H2O、CH4、CO2)、CO、NH3、HCN、C2H2、SO2、C2H4、H2S、PH3、TiO)。

sigmaについて:
・pred.std(-1) (各惑星の波長に対する標準偏差) と誤差に強い相関。平均sigmaをこの係数でスケーリングすると、ローカルバリデーションとLBスコアが約0.030向上した。
6th: https://www.kaggle.com/competitions/ariel-data-challenge-2024/discussion/543666
・多項式fitting。
・Savitzky-Golayフィルターによるスムージング
・ヒューリスティックとCNNを使用
・NNでは、transit内部とtransit外部(結合)を分けて入力として、その差分を予測する形式。そのままsiganlを入れるよりもNNがデータを理解しやすくなる。
code: https://www.kaggle.com/code/sergeifironov/new-blend-pdf?scriptVersionId=204505791
7th: https://www.kaggle.com/competitions/ariel-data-challenge-2024/discussion/543679
・窓10~30程度のスムージング
・多項式fitting
8th: https://www.kaggle.com/competitions/ariel-data-challenge-2024/discussion/543776
・多項式fitting
モデル:
- モデル1
・トランジット深度計算については、まず
\text{transit\_depth} = \frac{oot - it}{oot}
を最小二乗法(OLS)を用いて線形方程式を解く。
・分位回帰で初期フィットを行い、残差が大きい点を除去。その後、再度OLSでフィットし、異常点をモデル2でも除去して堅牢性を確保。 - モデル2
・全波長にSVDを適用し、主成分でデータを再構築。SNRに基づき波長を重み付け。
・近接波長には指数平滑化によるスムージングを適用。
・各波長を独立にOLSでフィットし、係数の共分散を標準誤差と残差相関に基づいて算出。
用語:
・多項式fitting
多項式を信号にfitさせるように最小二乗法で最適化。本コンペではtransit元の信号を近似するために利用された。
・最小二乗法(OLS)
線形方程式の係数を最適に推定するための回帰手法。
・分位回帰
データの異常値(残差の大きい点)を分位点によって識別・除去する手法。
・特異値分解(SVD)
データの主成分を抽出し、次元削減やノイズ除去を実現。
・一般化最小二乗法(GLS)
共分散を考慮した回帰手法で、係数の再構築に利用。共分散縮小を用いて、過小評価を防止。
・共分散縮小
共分散行列の不確実性を減少させることで安定性向上。
9th: https://www.kaggle.com/competitions/ariel-data-challenge-2024/discussion/543983
・多項式fitting
・wlの推定にtransit間の信号の平均の差を、高い方の平均で割ったものを使用(?)。これと多項式fittingの組み合わせてvaluesを予測。
sigmaについて:
・valuesのstdの値に基づいてsigmaを指定
10th: https://www.kaggle.com/competitions/ariel-data-challenge-2024/discussion/544189
・多項式fitting。
・transitの入り口と出口の検出に導関数の極値を使用。
・関数によるtransitの補正(定数倍)。
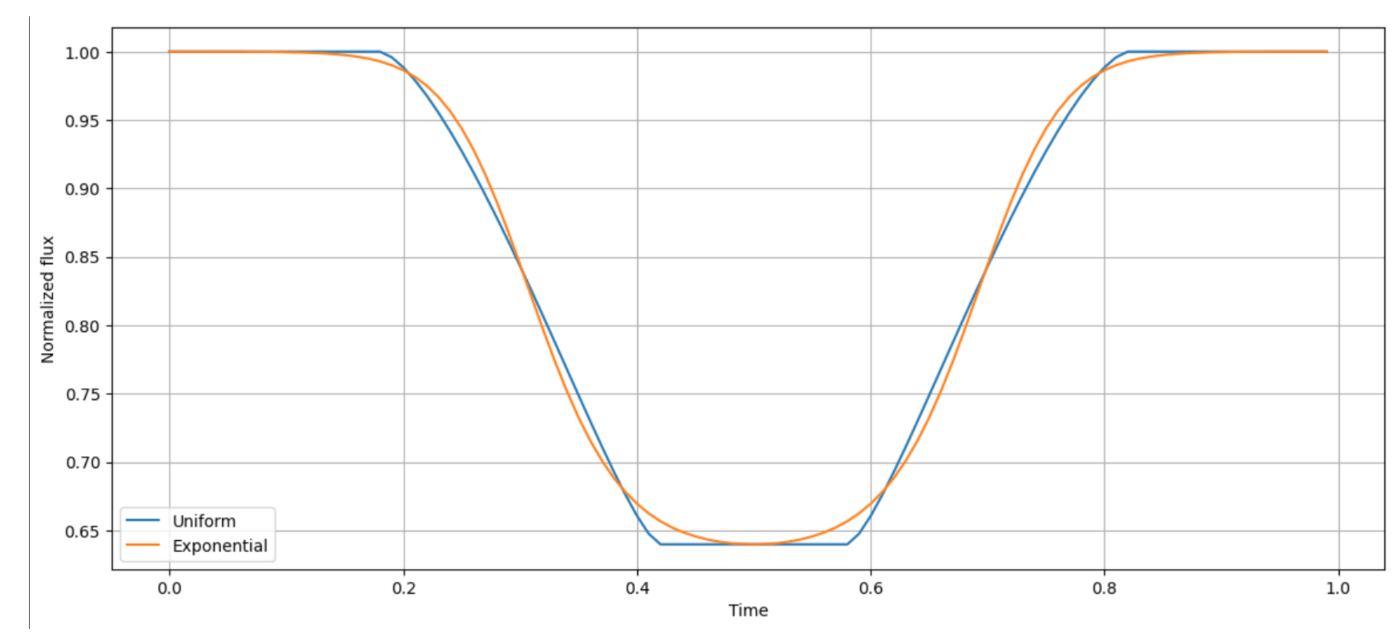

かなり上手くtransitを補正できている。
2. まとめ
今回は簡易的にNeurips2024の解法をまとめました。
今回のコンペでは解法がかなり多様的で勉強になりますので、ぜひ覗いてみて下さい。
Discussion