【Kaggle】HMS 2nd Solution explaind


This time, I'll explain the 2nd solution of HMS competition on kaggle.
the original solution is here:
0. Competiton explanation
This competition's purpose is classification to the 182 type bird calls.
The validation method is AUC-ROC, so we had to predict all of birds classes.
Competition host provide the random length audio calling data over 240000 samples as training data, and data not labeled for utilize to augmentation or otehrs.
As the problem must be addressed were:
unbalanced data, probably noisy and mixed test data, data while bird not calling, etc..
Additionaly point to be noted is the limitation of submittion. This competition only allow CPU and under 120 minutes for inference. We have to both infer and process the data in time.
If you wanna know details, reccoemnd you check the competition overview and dataset.
0.1 Technique used
- Use MNE-tool for signal(eeg) processing
- Use scipy.signal for filtering(scipy has various fiter)
- hgnet: is this?
0.2 Point to see
- 2D-CNN is not well-equipped to capture positional information with in the channels. Because there is not pad in channel direction.
- Using 3D-CNN model with 16channnel input fitered by 0.5~20Hz
- Same model but different library's(mne and scipy) filter for diversity.
- Double feature head(eeg + spectrum) (chap 1.4)
- 2 stage learning (chap 3)
- Random offset sampling and average as label (chap 3)
After here is the solution.
1. Model
In early time, feeding a bsx4xHxM input to the 2D-CNN produce worse result than the one-image method. Then author start to think why?
Due to the position-sensitive nature of labels(LPD, GPD, etc.), We should take care of the channel dimention. 2D-CNN is not well-equipped to capture positional information with in the channels. Because there is not pad in channel direction. And that's why they need to concat the spectrum into one image for a vision model other than a bsx16xHxW image(double banana montage: spectrum created from 16 types of signals depending on the location of the brain).
So author decided to use 3d-CNN for spectrum, and 2D-CNN model for raw-eeg signal.
total solution like this:

- mne 0.5-20Hz means use MNE-tool do filter.
- scypy.signal means use scipy.signal to do filter.
- For the reshape operator and the stft params please refer to the codes below.
- And the number in () means final weights of the ensemble.[0.2, 0.2, 0.2, 0.1, 0.1, 0.2]
1.1 ×3d-l (spectrum model)
After double banana montage, +- 1024 clip and 0.5-20Hz filter, use stft to extract the spectrum, then feed to a 3d-CNN(x3d-l).
explanation of words(My interpretation):
・Double banana montage: This is a specific montage setup used in EEG signal processing where signals from pairs of electrodes are subtracted from each other to emphasize differences and reduce common noise.
・±1024 clip: Limits the signal amplitude to the range between -1024 and +1024.
・0.5-20Hz filter: Applies a bandpass filter to retain frequencies between 0.5 Hz and 20 Hz, which is typical for isolating certain EEG signal components.
・STFT (Short-Time Fourier Transform): Transforms the time-domain signal into the frequency domain over short time segments to extract the spectrum.
・3D-CNN (x3d-l): A 3D Convolutional Neural Network model that processes the spectral data.
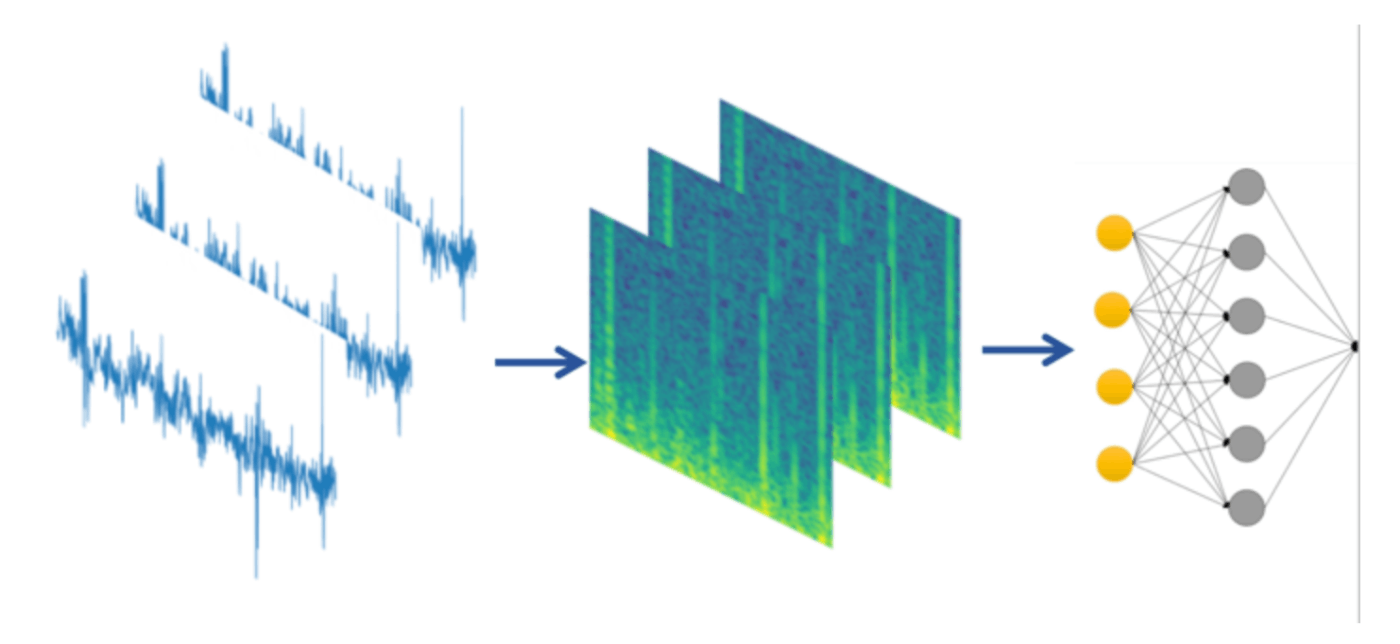
The input data is a 16-channls spectrum image.
X3d-l cv 0.21+, public lb 0.25, private lb 0.29.
stft code like below, use it as a nn.Module:
class Transform50s(nn.Module):
def __init__(self, ):
super().__init__()
self.wave_transform = torchaudio.transforms.Spectrogram(n_fft=512, win_length=128, hop_length=50, power=1)
def forward(self, x):
image = self.wave_transform(x)
image = torch.clip(image, min=0, max=10000) / 1000
n, c, h, w = image.size()
image = image[:, :, :int(20 / 100 * h + 10), :]
return image
class Transform10s(nn.Module):
def __init__(self, ):
super().__init__()
self.wave_transform = torchaudio.transforms.Spectrogram(n_fft=512, win_length=128, hop_length=10, power=1)
def forward(self, x):
image = self.wave_transform(x)
image = torch.clip(image, min=0, max=10000) / 1000
n, c, h, w = image.size()
image = image[:, :, :int(20 / 100 * h + 10), :]
return image
class Model(nn.Module):
def __init__(self):
super().__init__()
model_name = "x3d_l"
self.net = torch.hub.load('facebookresearch/pytorchvideo',
model_name, pretrained=True)
self.net.blocks[5].pool.pool = nn.AdaptiveAvgPool3d(1)
# self.net.blocks[5]=nn.Identity()
# self.net.avgpool = nn.Identity()
self.net.blocks[5].dropout = nn.Identity()
self.net.blocks[5].proj = nn.Identity()
self.net.blocks[5].activation = nn.Identity()
self.net.blocks[5].output_pool = nn.Identity()
def forward(self, x):
x = self.net(x)
return x
class Net(nn.Module):
def __init__(self, num_classes=1):
super().__init__()
self.preprocess50s = Transform50s()
self.preprocess10s = Transform10s()
self.model = Model()
self.pool = nn.AdaptiveAvgPool3d(1)
self.fc = nn.Linear(2048, 6, bias=True)
self.drop = nn.Dropout(0.5)
def forward(self, eeg):
# do preprocess
bs = eeg.size(0)
eeg_50s = eeg
eeg_10s = eeg[:, :, 4000:6000]
x_50 = self.preprocess50s(eeg_50s)
x_10 = self.preprocess10s(eeg_10s)
x = torch.cat([x_10, x_50], dim=1)
x = torch.unsqueeze(x, dim=1)
x = torch.cat([x, x, x], dim=1)
x = self.model(x)
# x = self.pool(x)
x = x.view(bs, -1)
x = self.drop(x)
x = self.fc(x)
return x
1.2 one image
It's a 2d vision model, efficientnetb5, public lb 0.262490 prvate lb 0.304877.
For 2d model, author concat 16 channels spectrum image like many peple does.
image = torch.reshape(image, shape=[n, 2, -1, w])
x1 = image[:, 0:1, ...]
x2 = image[:, 1:2, ...]
image = torch.cat([x1, x2], dim=-1)
image = torch.cat([image, image, image], dim=1)
Author check the submission score, combine these two spectrum model, get 0.28 private lb.
1.3 eeg model
View eeg (bsx16x10000) as an image. So expand dim=1(bsx1x16x10000), but the time dimention is too large. Then author make a reshape.
The model define as below:
rclass Net(nn.Module):
def __init__(self,):
super(Net, self).__init__()
self.model = timm.create_model('efficientnet_b5', pretrained=True, in_chans=3)
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(2048, out_features=6, bias=True)
self.dropout = nn.Dropout(p=0.5)
def extract_features(self, x):
feature1 = self.model.forward_features(x)
return feature1
def forward(self, x):
# extarct batch size
bs = x.size(0)
# reshape (bs, 16, 10000) -> (bs, 16, 1000, 10)
reshaped_tensor = x.view(bs, 16, 1000, 10)
# pemute to (bs, 16, 10, 1000)
reshaped_and_permuted_tensor = reshaped_tensor.permute(0, 1, 3, 2)
# reshape (bs, 16, 10, 1000) -> (bs, 160, 1000)
reshaped_and_permuted_tensor = reshaped_and_permuted_tensor.reshape(bs, 16 * 10, 1000)
# add new dimention at index 1, shape will be (bs, 1, 160, 1000)
x = torch.unsqueeze(reshaped_and_permuted_tensor, dim=1)
# concat the image to simulate RBG channel and increasing capacity, shape is (bs, 3, 160, 1000)
x = torch.cat([x, x, x], dim=1)
bs = x.size(0)
x = self.extract_features(x)
x = self.pool(x)
x = x.view(bs, -1)
x = self.dropout(x)
x = self.fc(x)
return x
forward_features() function in timm can extarct feature as like CNN, and it is used here.
The eeg 'reshaped' to bsx3x160x1000. With efficientnetb5, actives public lb 0.230978, private lb 0.282873.
There are 3models, but slightly different, mne-filter-efficientnetb5, scipy-filter-efficientnetb5 and mne-filter-hgnetb5
And the scires are slightly different,also.
1.4 Doublehead (eeg+spectrum)
Author use x3d-l to extarct the spectrum feature (with transform50s only), efficientnetb5 to extract the raw eeg feature.
Like the solution figure, concat the last feature, public lb 0.24, private lb 0.29? not sure.
2. Preprocess
- 2.1 Double banana montage, eeg as 16x10000
- 2.2 Filter with 0.5-20Hz
- 2.3 Clip by +-1024
3. Train
- 3.1 Stage 1, 15 epochs, with loss weght voters_num/20, Adamw lr=0.001, cos schedule
- 3.2 Stage 2, 5epoch, loss weight=1, voters_num>=6, Adamw lr=0.0001, cos schedule
- 3.3 use eeg_label_offset_seconds. Author random choose an offset for each eegid, and the target is average according to eegid for each train iter.
- 3.4 Augmentation: mirror eeg, flip between left brain data and right brain data
- 3.5 10 folds, then move 1000 samples from val to train, left 709 samples in val set. And use vote_num>=6 to do validation.
* voters_num equal number of vote, the competion data has number of voter for determine what the symptoms are.
4. Ensemble
By combining these models, author thinks it could get their current score. However their score is 6 model emsemble, but not improvement that much (0.28->0.27 private lb).
Final ensemble including:
- 2 spectrum model(x3d, efficientnetb5)
- 3 raw eeg model(efficientnetb5 with mne.filter, efficientnetb5 -butter filter, 1 ghnetb5 mne.filter)
- 1 eeg-spectrum mix model, butter filter
With weigts = [0.1,0.1,0.2,0.2,0.2,0.2].
ps. with-mne.filter means use mne lib to do filter, butter filter means use scipy.signal, just to add some diversity.
5 Some thought
Author thinks raw eeg is more important in this task. Feeding raw EEG data into a 2D visual model is somewhat similar to how humans observe EEG signals. Observe in time and channel dimensions!
6. Summary
Author using
- raw eeg as 160x1000 data
- spectrum as input of 2d-cnn and 3d-cnn
- extract feature from both of eeg(efficientnetb5) and spectrum(x3d-l) for mix model
- 2stage train(only high quality data in stage 2), augmentation
- different filter
and impotant others. This is a great work and solution!

I think top-tier kaggler do all of basically things, and trying new methods with solid evidence of some experimental results. This is the important thing to win the competiton.
But, also enjoying competition is one of the most important thing, let we don't forget that!
Reference
[1] coolz, 2nd place solution, kaggle
Discussion