【ML Paper】YOLO: Unified Real-Time Object Detection part4


This time, I'll explain the YOLO image detection model with paper.
This is a part4, part5 will publish soon.
Original paper: https://arxiv.org/abs/1506.02640
4. Training
4.1 Pretraining the Convolutional Layers
We pretrained the first 20 convolutional layers of our model on the ImageNet 1000-class dataset. After these layers, we added an average-pooling layer and a fully connected layer. Using the Darknet framework, this network achieved a single-crop top-5 accuracy of 88% on the ImageNet 2012 validation set.
4.2 Adapting the Model for Detection
To adapt the model for object detection, we added four convolutional layers and two fully connected layers with randomly initialized weights. We increased the input resolution from
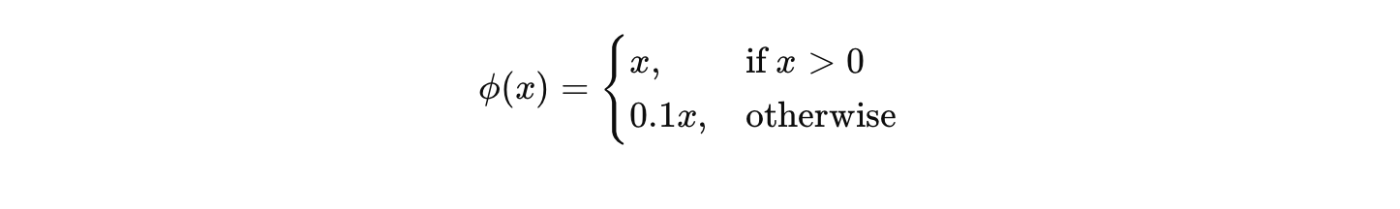
4.3 Loss Function Design
We employed a sum-squared error loss function to optimize the model. To address class imbalance and improve training stability, we adjusted the loss weighting. Specifically, we increased the loss for bounding box coordinate predictions by setting
The multi-part loss function used during training is defined as:

In this loss function,
4.4 Training Details
We trained the model for approximately 135 epochs using the PASCAL VOC 2007 and 2012 datasets. When testing on VOC 2012, we included the VOC 2007 test data in the training set. The training was conducted with a batch size of 64, a momentum of 0.9, and a weight decay of 0.0005. Our learning rate schedule involved gradually increasing the learning rate from
4.5 Data Augmentation and Regularization
To prevent overfitting, we applied dropout with a rate of 0.5 after the first fully connected layer to prevent co-adaptation between layers. We also performed extensive data augmentation by applying random scaling and translations up to 20% of the original image size. Additionally, we randomly adjusted the exposure and saturation of the images by up to a factor of 1.5 in the HSV color space.
Discussion