【ML Paper】YOLOv2 Summary
This time, I'll explain the YOLOv2 image detection model with paper.
This is the summary of yolo explain articles part 1 to 13.
Original Paper: https://arxiv.org/abs/1612.08242
1. Overview
Authors published the YOLO9000(as known v2) model that can detect over 9000 object categories.
Using a novel, multi-scale training method the same YOLOv2 model can run at varying sizes, offering an easy tradeoff between speed and accuracy.
YOLO v2 Performances:
At 67 FPS, gets 76.8 mAP on VOC 2007.
At 40 FPS, gets 78.6 mAP.
These results outperforming state-of-the-art methods like Faster RCNN with ResNet and SSD while still running significantly faster.
The authors develop a joint training method for YOLO9000, using both COCO and ImageNet datasets. This allows YOLO9000 to detect classes without labeled detection data, achieving 19.7 mAP on ImageNet with 44 classes and 16.0 mAP on 156 additional classes. YOLO9000 can recognize over 9,000 categories while maintaining real-time performance.
2. Introduction
2.1 Introduction
General-purpose object detection aims to achieve high speed and accuracy while recognizing a diverse range of objects. Although neural network advancements have enhanced detection frameworks, most existing methods remain limited to recognizing a relatively small set of objects.
This limitation is primarily due to the constrained size of current object detection datasets compared to those available for classification and tagging tasks.
2.2 Dataset Limitations
Object detection datasets typically consist of thousands to hundreds of thousands of images with dozens to hundreds of object categories.
In contrast, classification datasets encompass millions of images with tens or hundreds of thousands of categories.
The scalability of detection systems is hindered by the high cost of labeling images for detection, making it unlikely that detection datasets will reach the scale of classification datasets in the near future.
2.3 Proposed Methodology
To overcome the limitations of existing detection datasets, a novel method is proposed that leverages the extensive classification data available. This approach utilizes a hierarchical view of object classification, enabling the combination of distinct datasets.
Additionally, a joint training algorithm is introduced to train object detectors using both detection and classification data.
This method allows the model to precisely localize objects using labeled detection images while expanding its vocabulary and enhancing robustness through classification images.
2.4 Implementation: YOLO9000
Applying the proposed method, YOLO9000, a real-time object detector, was developed to recognize over 9000 different object categories.
The implementation began with enhancing the base YOLO detection system to create YOLOv2, achieving state-of-the-art real-time detection performance. Subsequently, the dataset combination technique and joint training algorithm were employed to train the model on more than 9000 classes from ImageNet alongside detection data from COCO.
3. Better
3.1 Methodology
YOLO (You Only Look Once) faces several limitations compared to contemporary detection systems, including localization errors and lower recall rates than region proposal-based methods like Fast R-CNN.
The goal with YOLOv2 is to improve recall and localization accuracy while preserving the model’s efficiency, without scaling up the network’s complexity or size.
YOLOv2 combines techniques from prior work with novel ideas to create a faster, more accurate detector.
3.2 Key Enhancements
3.2.1 Batch Normalization
Incorporating batch normalization into all convolutional layers results in faster convergence and reduces the need for additional regularization techniques.
This adjustment leads to an improvement of over 2% in mean Average Precision (mAP), allowing the model to eliminate dropout layers without causing overfitting.
3.2.2 High-Resolution Classifier
Unlike previous methods where classifiers are typically trained on low-resolution images (around 224x224), YOLOv2 first fine-tunes the classifier at a higher 448x448 resolution on the ImageNet dataset for 10 epochs,
allowing the network’s filters to adjust to high-resolution inputs.
This high-resolution classifier contributes to an additional mAP increase of nearly 4%.
3.3 Results
The changes introduced in YOLOv2 achieve improved localization accuracy and higher recall, thereby addressing YOLO’s primary limitations. This modified network maintains classification accuracy while offering significant performance gains, as summarized in Table 2.

3.4 Summary
By integrating batch normalization and adopting a high-resolution classifier, YOLOv2 becomes more accurate without the need for larger or deeper architectures, balancing speed and precision effectively for real-time applications.
These strategies allow YOLOv2 to remain a competitive option for efficient object detection in computer vision tasks.
3.5 Convolutional With Anchor Boxes
In modifying the YOLO architecture, the fully connected layers were removed in favor of using anchor boxes to predict bounding boxes.
This approach aligns YOLO more closely with the methodology of Faster R-CNN, which utilizes a region proposal network (RPN) to predict offsets and confidences for predefined anchor boxes through convolutional layers.
To enhance the resolution of the convolutional feature maps, one pooling layer was eliminated, and the network was resized to accept input images of 416×416 pixels instead of the original 448×448. This adjustment ensures an odd number of locations in the feature map, resulting in a single center cell that is advantageous for accurately predicting objects, particularly large ones, that are typically centered in images.
The convolutional layers in YOLO downsample the input image by a factor of 32, producing a 13×13 output feature map. Additionally, the introduction of anchor boxes decouples class prediction from spatial location, enabling the model to predict class probabilities and objectness scores for each anchor box individually. The objectness score reflects the Intersection over Union (IOU) between the ground truth and the proposed box, while class predictions represent the conditional probability of each class given the presence of an object.
3.5.1 Results
Implementing anchor boxes resulted in a minor decrease in mean Average Precision (mAP) from 69.5 to 69.2. However, this modification significantly improved the recall from 81% to 88%.
While the number of predicted bounding boxes per image increased from 98 to over a thousand, the enhanced recall indicates that the model is better at identifying relevant objects, offering greater potential for further improvements despite the slight reduction in mAP.
3.5.2 Discussion
The integration of anchor boxes into the YOLO framework introduces a trade-off between precision and recall.
Although there is a marginal decrease in mAP, the substantial increase in recall suggests that the model becomes more effective at detecting objects, particularly those that occupy central positions within images.
3.6 Dimension Clusters
To address the challenges associated with manually selecting anchor box dimensions in YOLO, the authors propose an automated approach using k-means clustering on the training set's bounding boxes.
Unlike standard k-means, which employs Euclidean distance and tends to favor smaller boxes by generating larger errors for bigger boxes, the authors introduce a distance metric based on Intersection over Union (IOU).
Specifically, the distance between a box and a centroid is defined as:
This metric ensures that the selection of priors focuses on achieving high IOU scores irrespective of box sizes. The clustering process is executed for various values of ( k ), and the average IOU with the closest centroid is evaluated to determine the optimal number of clusters.
3.6.1 Results
The experiments reveal that selecting ( k = 5 ) offers a balanced tradeoff between model complexity and recall, achieving an average IOU of 61.0. This performance is comparable to using 9 hand-picked anchor boxes, which yield an average IOU of 60.9.
Moreover, increasing the number of centroids to ( k = 9 ) significantly enhances the average IOU to 67.2, indicating a superior alignment with the bounding box distribution.
The cluster centroids derived from this method differ markedly from the manually selected anchor boxes, characterized by fewer short and wide boxes and a greater prevalence of tall and thin boxes.
3.6.2 Discussion
The utilization of k-means clustering with an IOU-based distance metric provides a more effective initialization for anchor boxes in YOLO.
This approach not only simplifies the learning process for the network by offering a better starting representation but also enhances the overall detection performance, as evidenced by the higher IOU scores with increased ( k ).
3.6.3 Limitations
While the clustering approach shows promise, the choice of ( k ) remains a hyperparameter that requires careful tuning. Additionally, the method's effectiveness may vary with different datasets, necessitating further validation across diverse scenarios.
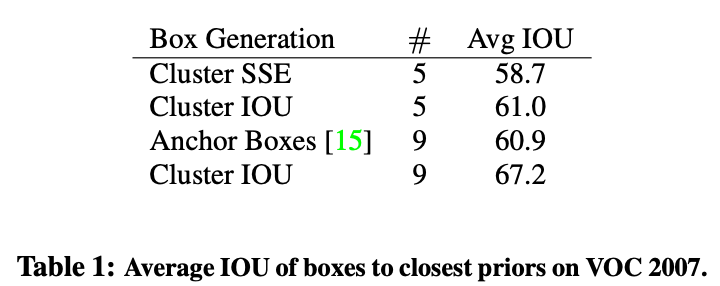
The table illustrates that clustering-based methods, particularly with ( k = 9 ), achieve higher average IOU compared to traditional hand-picked anchor boxes, highlighting the efficacy of the proposed approach.
Direct Location Prediction
In the context of using anchor boxes with YOLO, a significant challenge arises from model instability, particularly during the initial training iterations.
This instability primarily stems from the prediction of the
Here,
For instance, a prediction of
To mitigate this issue, the approach adopted by YOLO involves predicting location coordinates relative to the grid cell's position.
By bounding the ground truth coordinates between 0 and 1 using a logistic activation function, the network's predictions are constrained within this range. Specifically, the network predicts five bounding boxes per cell in the output feature map, each characterized by five parameters:
Given a cell offset
This constrained parameterization simplifies the learning process, enhancing the network's stability.
Additionally, leveraging dimension clusters and directly predicting the bounding box center locations results in an approximate 5% performance improvement over the traditional anchor box approach.
Fine-Grained Features
The modified YOLO architecture performs detections on a
However, accurately localizing smaller objects benefits from higher-resolution features.
Unlike Faster R-CNN and SSD, which utilize multiple feature maps at varying resolutions for their proposal networks, the enhanced YOLO incorporates a passthrough layer to integrate finer-grained features.
This passthrough layer extracts features from an earlier layer with a
Instead of merging spatial locations, adjacent features are stacked into different channels, analogous to the identity mappings in ResNet. Consequently, the
The detector operates on this augmented feature map, gaining access to detailed information that aids in the localization of smaller objects. This modification yields a modest performance increase of approximately 1%.
Multi-Scale Training
YOLOv2 improves robustness to varying image sizes through a multi-scale training approach. Unlike the original YOLO with a fixed input resolution of
Utilizing only convolutional and pooling layers allows the model to resize dynamically during training. Every 10 batches, the network randomly selects a new image dimension from multiples of 32 within the range of
At lower resolutions, such as
At higher resolutions, YOLOv2 reaches a state-of-the-art mAP of 78.6 on the PASCAL VOC 2007 dataset while maintaining real-time processing speeds. This flexibility allows users to balance speed and accuracy based on their specific needs.
Further Experiments
YOLOv2's performance was further tested on additional datasets. When trained on the PASCAL VOC 2012 dataset, YOLOv2 achieved a mAP of 73.4, outperforming other detection systems in speed. On the COCO dataset, YOLOv2 reached a mAP of 44.0 at an Intersection over Union (IOU) threshold of 0.5, matching the performance of SSD and Faster R-CNN models.
Table below compares YOLOv2's performance with other detection frameworks on the PASCAL VOC 2007 dataset:
| Detection Framework | Train | mAP | FPS |
|---|---|---|---|
| Fast R-CNN | 2007+2012 | 70.0 | 0.5 |
| Faster R-CNN VGG-16 | 2007+2012 | 73.2 | 7 |
| Faster R-CNN ResNet | 2007+2012 | 76.4 | 5 |
| YOLO | 2007+2012 | 63.4 | 45 |
| SSD300 | 2007+2012 | 74.3 | 46 |
| SSD500 | 2007+2012 | 76.8 | 19 |
| YOLOv2 288 × 288 | 2007+2012 | 69.0 | 91 |
| YOLOv2 352 × 352 | 2007+2012 | 73.7 | 81 |
| YOLOv2 416 × 416 | 2007+2012 | 76.8 | 67 |
| YOLOv2 480 × 480 | 2007+2012 | 77.8 | 59 |
| YOLOv2 544 × 544 | 2007+2012 | 78.6 | 40 |
All metrics are measured on a Geforce GTX Titan X GPU (original model, not Pascal). YOLOv2 consistently outperforms previous detection methods in both speed and accuracy.
Its ability to operate at different resolutions with the same trained model allows YOLOv2 to maintain high mAP scores while running in real-time, making it versatile for applications like real-time video processing and deployment on resource-constrained hardware.
Faster
YOLOv2 is engineered for high-speed detection, crucial for applications such as robotics and self-driving cars that require low-latency predictions.
Traditional detection frameworks typically utilize VGG-16 as the base feature extractor, which, despite its robust classification capabilities, demands approximately
In contrast, YOLO employs a custom network inspired by the GoogLeNet architecture, reducing the computational load to
This modification results in a slight decrease in accuracy, with YOLO achieving an 88.0% top-5 accuracy on ImageNet compared to VGG-16’s 90.0%, while significantly enhancing processing speed.
Darknet-19
To further optimize performance, YOLOv2 introduces Darknet-19 as its new classification model. Darknet-19 consists of 19 convolutional layers and 5 max-pooling layers, leveraging primarily
Incorporating concepts from Network in Network (NIN), Darknet-19 utilizes global average pooling for predictions and integrates
This streamlined architecture requires only
For a full description see Table 6.

Classification Training
The network was trained on the standard ImageNet 1000-class classification dataset for 160 epochs using stochastic gradient descent (SGD) with an initial learning rate of 0.1.
A polynomial learning rate decay with a power of 4, weight decay of 0.0005, and momentum of 0.9 were applied within the Darknet neural network framework. Standard data augmentation techniques, including random crops, rotations, and hue, saturation, and exposure shifts, were utilized during training.
After the initial training phase, the network was fine-tuned at a larger resolution of
Detection Training
For detection tasks, the network architecture was modified by removing the last convolutional layer and adding three
Specifically, for the VOC dataset, the model was configured to predict 5 bounding boxes per image, each with 5 coordinates and 20 class probabilities, resulting in 125 filters.
Additionally, a passthrough layer was integrated from the final
Joint Training Approach
The authors introduce a joint training mechanism that leverages both classification and detection datasets to enhance object detection capabilities. This approach utilizes images labeled for detection to learn detection-specific features, such as bounding box coordinate prediction and objectness scores, while simultaneously classifying common objects.
Additionally, images with only class labels are incorporated to broaden the range of detectable categories. During training, images from detection and classification datasets are interleaved.
When the network processes a detection-labeled image, it backpropagates using the complete YOLOv2 loss function. Conversely, for classification-labeled images, backpropagation is restricted to the classification-specific components of the architecture.
Label Merging Strategy
A critical aspect of the method is the coherent integration of labels from both datasets.
Detection datasets typically include general labels like "dog" or "boat," whereas classification datasets, such as ImageNet, offer a more granular taxonomy with over a hundred dog breeds, including "Norfolk terrier," "Yorkshire terrier," and "Bedlington terrier."
To effectively train on both datasets, it is essential to merge these labels in a manner that accommodates their hierarchical and non-mutually exclusive nature.
Challenges
One of the primary challenges in this joint training approach is the incompatibility of label structures between classification and detection datasets.
Classification models often employ a softmax layer across all possible categories to determine the final probability distribution, inherently assuming that classes are mutually exclusive. This assumption complicates the integration of datasets like ImageNet and COCO, where labels such as "Norfolk terrier" and "dog" overlap and are not mutually exclusive.
An alternative is to adopt a multi-label model that does not enforce mutual exclusivity. However, this strategy disregards the inherent structure of the data, such as the mutual exclusivity of COCO classes, potentially undermining the model's performance.
Proposed Solution
To address these challenges, the method avoids relying solely on softmax-based classification. Instead, a strategy is implemented that allows for the coexistence of detailed and general labels without enforcing mutual exclusivity.
This enables the model to recognize both specific categories from classification datasets and general categories from detection datasets, thereby expanding the range of detectable objects while maintaining the structural integrity of the data.
Hierarchical Classification
The study leverages the hierarchical structure of WordNet to enhance classification within ImageNet.
Unlike traditional flat classification approaches, the authors construct a hierarchical tree, termed WordTree, from the visual nouns in ImageNet by tracing their paths through the WordNet graph to the root node, "physical object." Given that WordNet is a directed graph with multiple paths for some synsets, the tree construction prioritizes shorter paths to minimize complexity. During classification, WordTree predicts conditional probabilities at each node, such as
For validation, the Darknet-19 model is trained on a modified version of WordTree, referred to as WordTree1k, which includes 1,369 labels by incorporating intermediate nodes from the original 1,000 ImageNet classes. During training, ground truth labels are propagated up the tree, ensuring that an image labeled as a "Norfolk terrier" is also associated with broader categories like "dog" and "mammal." The model predicts a vector of 1,369 values, and a softmax function is applied over synsets that are hyponyms of the same concept to determine the conditional probabilities.
Results
The hierarchical Darknet-19 model, trained using the WordTree1k structure, achieved a top-1 accuracy of 71.9% and a top-5 accuracy of 90.4%. This performance was attained despite expanding the label space by 369 additional concepts and maintaining the hierarchical tree structure. The marginal drop in accuracy indicates the robustness of the hierarchical approach compared to flat classification methods.
Discussion
Implementing a hierarchical classification system offers several advantages. The model exhibits graceful degradation when encountering new or unknown object categories. For instance, if the network identifies an image as a "dog" but is uncertain about the specific breed, it maintains high confidence in the general category "dog" while distributing lower confidence levels among its hyponyms. This capability ensures that the model remains reliable even when faced with ambiguous or unfamiliar inputs.
Furthermore, the hierarchical approach extends to object detection tasks. By integrating with YOLOv2’s objectness predictor, the system can determine
Inference
The hierarchical classification framework presented effectively utilizes the structured relationships within WordNet to enhance image classification and detection. By systematically predicting and combining conditional probabilities along a hierarchical tree, the model achieves high accuracy while accommodating an expanded and nuanced label set. This approach not only maintains performance levels comparable to flat classification models but also provides enhanced interpretability and adaptability in diverse classification scenarios.
Dataset Combination with WordTree
WordTree facilitates the integration of multiple datasets by mapping their categories to synsets within the tree structure.
For instance, labels from ImageNet and COCO are combined seamlessly using WordTree, as illustrated in Figure 6. Given the extensive diversity of WordNet, this method is applicable to a wide range of datasets, enabling a unified framework for category representation.
Joint Classification and Detection
Leveraging WordTree to merge datasets allows for the training of a joint model that handles both classification and detection tasks.
An extensive detector is trained using a combined dataset comprising the COCO detection dataset and the top 9000 classes from the complete ImageNet release. To ensure comprehensive evaluation, additional classes from the ImageNet detection challenge, not previously included, are incorporated. The resulting WordTree for this dataset encompasses 9418 classes. To balance the significantly larger ImageNet dataset, COCO is oversampled, maintaining a ratio where ImageNet is only four times larger.
Training YOLO9000
YOLO9000 is trained on the combined dataset using the YOLOv2 architecture, modified to include only three priors instead of five to reduce output size.
During training, when the network processes a detection image, loss is backpropagated normally. For classification loss, only losses at or above the label's corresponding level in the tree are backpropagated. For example, if the label is "dog," errors are not assigned to more specific predictions like "German Shepherd" or "Golden Retriever" due to the lack of detailed information.
Conversely, when processing a classification image, only the classification loss is backpropagated. This involves identifying the bounding box with the highest probability for the class and computing the loss based on its predicted tree, assuming an Intersection over Union (IOU) of at least 0.3 with the ground truth to backpropagate objectness loss.
Evaluation on ImageNet Detection
YOLO9000's performance is assessed on the ImageNet detection task, which shares 44 object categories with COCO. This means that for the majority of test images, YOLO9000 has only encountered classification data rather than detection data.
The model achieves an overall mean Average Precision (mAP) of 19.7, with a mAP of 16.0 on the 156 disjoint object classes that lack labeled detection data. This performance surpasses that of Deformable Parts Models (DPM), despite YOLO9000 being trained on different datasets with partial supervision. Additionally, YOLO9000 is capable of detecting 9000 other object categories in real-time.
Performance Analysis
Analyzing YOLO9000's performance on ImageNet reveals that the model effectively learns new animal species but faces challenges with categories related to clothing and equipment.
The successful learning of new animals is attributed to the generalization of objectness predictions from the animals present in COCO. In contrast, categories such as "sunglasses" or "swimming trunks" are problematic because COCO does not provide bounding box labels for clothing items, limiting YOLO9000's ability to model these categories accurately.
Overview of YOLO Systems
YOLOv2 and YOLO9000 are real-time object detection systems that set new standards in speed and accuracy. YOLOv2 outperforms existing detectors across multiple datasets and allows adjustable image sizes to balance speed and precision.
Expanding Detection with YOLO9000
YOLO9000 extends detection to over 9000 object categories by optimizing detection and classification simultaneously. It utilizes the WordTree structure to integrate data from ImageNet and COCO, reducing the dataset size gap between detection and classification tasks.
YOLO9000 employs the WordTree representation for a richer classification output. It combines datasets through hierarchical classification and uses multi-scale training to enhance performance across various visual tasks, including classification and segmentation.
Conclusion
YOLOv2 and YOLO9000 advance real-time object detection with enhanced flexibility and performance. Their innovative methodologies not only improve detection and classification but also enable future advancements in the field of computer vision.
End
This is the end of the ind¥troducing articles about YOLOv2, thank you for reading!
Discussion