【Paper Explanation】Conformer: Great Speech Recognition Model
Original paper: Conformer: Convolution-augmented Transformer for Speech Recognition (2020)
1. What is Conformer?
Conformer is a convolution-augmented transformer model developed by google researchers for speech recognition.
This was motivated from the fact that CNN can exploit local featues efficiency, and Transformer models are good at capturing content-based grobal interactions. Authors purposed to achieve great result by combining both mothod.
Index Terms: speech recognition, attention, convolutional neural networks, transformer, end-to-end
2. Conformer Model
First, I show the srchitecture of conformer encoder model.

Quote: [1]
2.1 Multi-Headed Self-Attention Module
They employed multi-headed self-attention(MHSA) while integrating an important technique from Transformer-XL, the relative sinusoidal positional encoding scheme. This allows the self attention module to generalize better on different input length and the resulting encoder is more robust to the variance of the utterace length.
We use pre-norm residual units with dropout which helps training and regularizing deeper models.
・Mluti-Headed Self-Attention module(with relative positional embedding)

Quote: [1]
2.2 Convolution Module
・Convolution module

Quote: [1]
・Simple description of leyers
Layernorm: To normalize (and to prevent overfitting)
Pointwise Conv: To reduce number of channel direction's layer
Glu Activation: Works like avtivation layer, for expand to model expression
1D depthwise Conv: Functions as a convolution by using it in conjunction with Pointwise Conv after this
Batchnorm: To normalize
Swish Activation: Activation layer similar to ReLU, it smoother than. fro expand model expression
Pointwise Conv: Functions as a convolution by using it in conjunction with 1D depthwise Conv before this
Dropout: To normalize
It using many technics, especially, convolution by depthwise and pointwise is little different from normal convolution becouse it only using one kernel for each input cannels and it extract feature after kernel calulation.
But it perform almost same result to normal convolution with less parametor, so it's ok to think as efficient Convolution layer.
The other layer exist for activate(for expand model expression), and normalize(for prevent model's overfitting)
2.3 Feed Forward Module
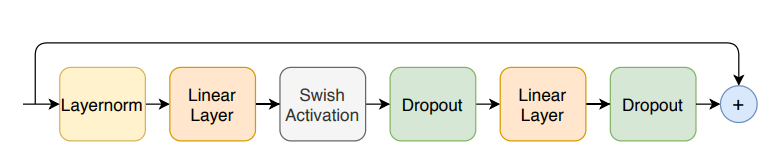
Quote: [1]
Above one is the feed forward module. It was deployed after. This is composed of two liniear transformations and a nonlinear activation in between.
A residual connection is also added to this modeule, followed by layer normalization, this structure is adopted by Transformer ASR models.
This module is a little simply.
2.4 Conformer Block
・Conformer Block(right side)
Quote: [1]
The right side block of this is the Conformer block's architecture.
This block contains two feed forward modules sandwiching the MHSA moduleand Convolution module.
This sandwich structure is inspired by Macaron-Net[2], it purposes repracing the original transformer's feed forward layer, and this perform better than transformer in Translation task score(BLEU) on IWSLT14 De-En and WMT14 En-De testsets.
The formula of Conformer block:
2.4.1 Considering of architecture
They tried to ablation study and surched best structure.
Result, two Macaron-net style feed forward layers with half step residual connections sandwitching the attention and convolution modelues in between probides a significant improvement over having a single feed forward module in Conformer's architecture.
The combination of convolution and self-attention has been studied before, and many ways to achieve Layernorm Linear can be imagined.
They found that stacking the convolutional module after the self-attention module worked best for speech recognition.
3. Performance
・Conparison with a few state-of-the-art models(LibriSpeech test-clean/test-other)

Without a language model, the performance of the moderate model has already achieved competitive results of 2.3/5.0 in tests/testother, the most well-known Transformer, LSTM-based models, or outperform convolutional models of similar size. With the addition of language models, these models achieve the lowest word error rates of all existing models. This clearly demonstrates the effectiveness of combining Transformer and convolution in a single neural network.
4. Summary
This time, I introduled about conformer.
A squeezeformer, which is a reconsideration of this conformer, has also been proposed, so I would like to see that as well if I have a chance.
thank you for reading.
References
[1] Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, Ruoming Pang, "Conformer: Convolution-augmented Transformer for Speech Recognition", arxiv, 2020
[2] Yiping Lu, Zhuohan Li, Di He, Zhiqing Sun, Bin Dong, Tao Qin, Liwei Wang, Tie-Yan Liu, "Understanding and Improving Transformer From a Multi-Particle Dynamic System Point of View", arxiv, 2019
[3] yu4u, "Kaggleで学ぶ系列データのための深層学習モデリング"
Discussion