【Kaggle】HMS 1st Solution Explanation
今回はHMSコンペの1位解法を和訳してまとめます。
0. コンペ概要
患者の脳波が示す活動の種類を分類する。専門家の評価を正解として予測を行うコンペです。
このコンペでは、生の脳波波形(eeg)とスペクトログラム(spectrogram)の両方が提供されており、スペクトログラムは10分、脳波波形は50秒です、またこれらのデータの中央の50秒は同じデータであり、この期間は同じデータを二つの表現方法で提示しています。
eeg: 一般に想像する波形データ(株価など)
spectrogram: 一般的にスペクトログラムとは、電極から得られた電気信号に対して、短い時間窓で区切ったうえで短時間フーリエ変換(STFT: Short-Time Fourier Transform)を適用して得られる三次元(時間、周波数、パワースペクトル密度)の情報を持ったデータのことである。つまり、datasetのspectrogramファイルはすべてeegデータのフーリエ変換後の情報である。下図の色で囲まれた枠内の電極からのデータで、計4つのスペクトログラム(LL、LP、RP、RR)の作成ができる。

より詳しく知りたい方は、コンペの概要と以下のデータ説明を読むと分かりやすいと思います。
1. 概要
本解法は、4人(yamash, suguuuuu, kfuji, Muku)のモデルのアンサンブルです。
以下ではそれぞれのモデルについて解説していきます。
・アーキテクチャ(各モデルとアンサンブル)

・yamash's partより抜粋
各モデルの推論をアンサンブルには、softmaxをentmaxに置き換えた各モデルの予測値を特徴量として、非負線形回帰を使用しました。
非負線形回帰によって、訓練データに過剰適合してもCVとLBの相関が維持されることに気づいたため、これを採用しました。
1.1 チームの評価手法戦略
モデルの評価にはChrisさんの手法を使用しています。
評価手法戦略
・正解ラベルはEEGごとに総計したものを正規化して使用しました。
・Fold手法は、Group K-foldで分割数は5です。
・データは投票数が10以上の物のみ採用します。
2. yamash's part
2.1 概要
EEG波形を縦に18個連結し、それぞれ異なる期間(2000,5000,10000)で切り抜いたあと、形を修正して2D CNNに投入しています。
longitudinal bipolar montage: 縦方向にデータを結合
bandpass filter: 特定の周波数のみ抽出

最終提出には、ランダムシードとbandpass filterの領域を変更した4つのモデルと、1つのInceptionモデル(GoogLenetのもの?)のアンサンブルを使用しました。
2.2 アンサンブル
アンサンブルには非負線形回帰を使用しました。
非負線型回帰: パラメータが全て0か正の線型回帰。
最初は全てのモデルの平均と、各モデルに対する重みを使用していましたが、非負線形回帰を使用することで訓練データに過剰適合してもLBとCVの相関が維持されることに気づいたため、これを採用しました。
2.3 Replacing softmax with entmax
softmax関数は、出力の全ての値において0になることはあり得ません(数式より、出力の最小値が0にならない)。しかし、訓練データの多くが特定のクラスの確率が0になっていました。
そこで、sparsemaxとentmaxの採用を考えました。これらはsoftmaxに対してより離散的に結果を出力します。
最終的に、全ての単一モデルに対して小さいアルファパラメータのentmaxを適用することに決定しました。これによって、パブリック及びプライベートのLBスコアが0.004向上しました。
パブリックLBデータ: コンペ開催中のsubmissionに対する評価用データ
プライベートLBデータ: コンペ終了時の最終評価時に使用する評価用データ
3. suguuuu's part
3.1 概要
最初にモデル1を作成しました。モデル2は、yamashさんの前処理を組み合わせました。
・モデル1

EEGデータに対して、CWT(Continuous wavelet transform)を適用しました。
CWT: 特定のwaveletの成分がどの程度データに含まれるかと言う情報から、データの周波数成分を調べる手法で、2次元のスカログラムが得られます。waveletによって様々なデータが得られ、STFTに対して時間や周波数軸の情報損失を抑えられる可能性があります。
得られたスカログラムを縦に結合し、MaxVIT_baseモデルに入力します。
MaxVIT: 軽量なVITを目的に提案された、入力がスケーラブルなVITモデルです。
・モデル2
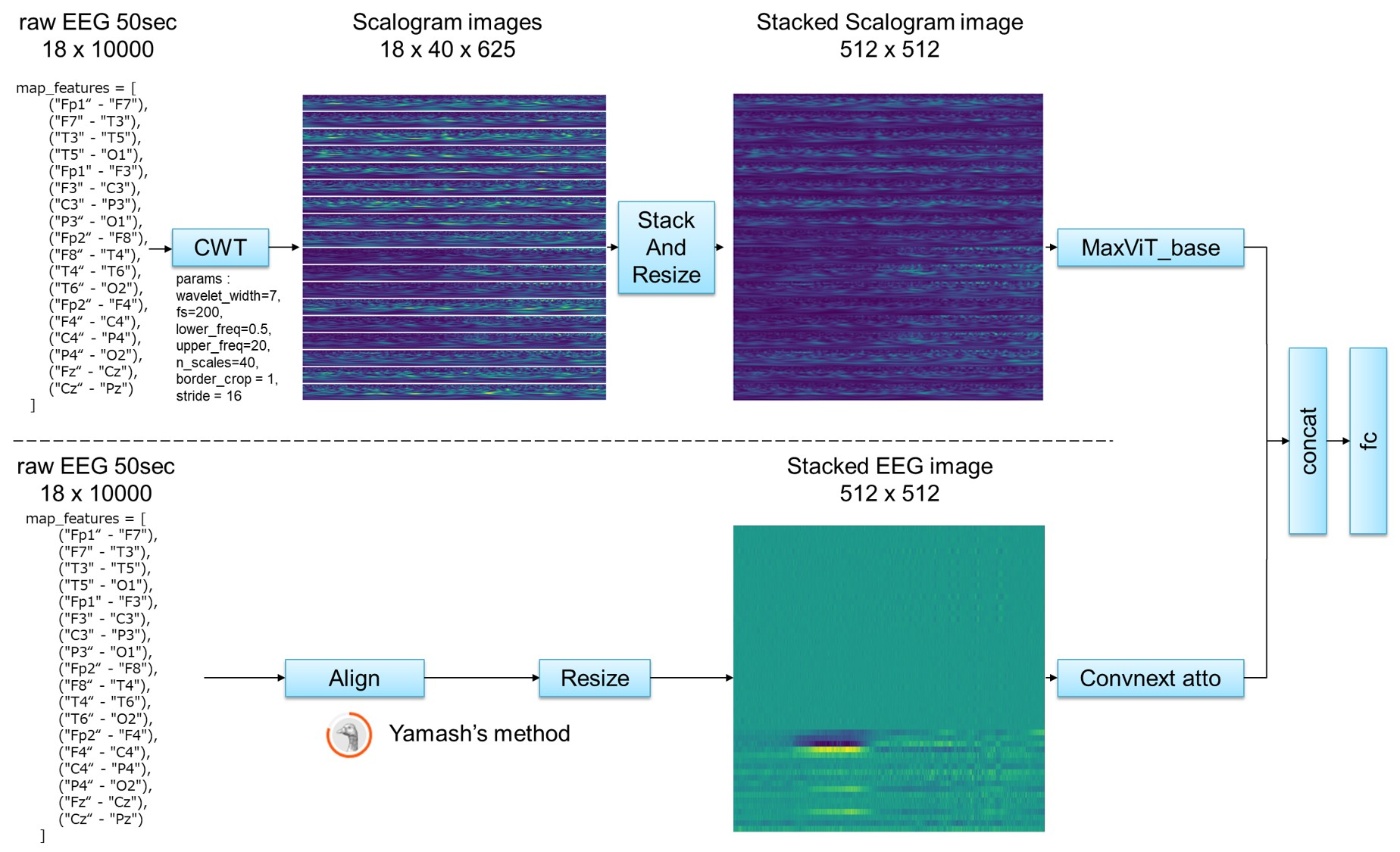
convnextモデルが追加され、CWTによるVITモデルと結合されています。
3.2 前処理(スカログラムの作成)
どのようにスカログラムを作成したか説明します。
スカログラムの作成手順
- 波形xをEEGから取得
- xを-1024から1024の範囲に丸め、32で割って正規化
- xの中心50秒(10,000 frames)を切り取る。 (25秒や10秒の切り取りより効果的)
- 連続ウェーブレット変換(CWT)の適用
コード
設定: wavelet_width=7, fs=200, lower_freq=0.5, upper_freq=40, n_scales=40, border_crop=1, stride=16.
0.5-40Hzに調整されており、デフォルトの0.5-20HzのCWTよりも良い結果を得られました。
入力: EEG 18×10000, スカログラム: 18×40×625 - 得られた18個のスカログラムを縦に結合
- 512×512にリサイズ
3.3 学習
2ステージ学習を行いました。(5epoch → 15epoch)
拡張: XYmasking, Mixup
最適化: Adam
スケジューラー: コサインアニーリング
3.4 モデル
MaxVIT_baseがスカログラムに最適でした。
3.5 機能しなかったもの
・STFT(短期間フーリエ変換)、 Kaggle提供のスペクトログラム、 CQT(Q変換)
・プロットされた画像による学習
・様々なEEGの合成画像
3.6 なぜCWTを使用したのか?
STFTを試しましたが、うまくいきませんでした。
そこで、ChatGPTに相談し、以下の情報を得ました。
To capture the local characteristics of signals with high non-stationarity, it's essential to choose an analysis method that can adapt to the varying nature of the signal. Considering the strengths and weaknesses of Wavelet Transform, Superlet Transform, and Short-Time Fourier Transform (STFT), let's determine the best option.
### Short-Time Fourier Transform (STFT)
- **Strengths:**
- Relatively easy to implement and widely used.
- Offers an intuitive presentation of time-frequency information.
- **Weaknesses:**
- Fixed window size creates a trade-off between time and frequency resolution.
- Limited ability to capture local features of highly non-stationary signals.
### Wavelet Transform
- **Strengths:**
- Capable of multi-resolution analysis, capturing signal characteristics at different scales.
- Excellently captures local features of non-stationary or complex signals.
- Suitable for detecting short-duration events, analyzing abrupt changes, and non-linear characteristics within signals.
- **Weaknesses:**
- Requires the selection of an appropriate wavelet function, which can demand specialized knowledge.
- Implementation and interpretation can become complex.
### Superlet Transform
- **Strengths:**
- Provides high time-frequency resolution, capturing fine details of the signal.
- High capability to distinguish overlapped or short-duration signal components.
- Particularly effective for analyzing signals with high non-stationarity, such as complex brain wave patterns.
- **Weaknesses:**
- Relatively new, with potentially limited resources or examples of implementation available.
- May incur high computational costs.
### Best Transform for Analyzing High Non-stationary Signals
To capture the local characteristics of highly non-stationary signals, **Wavelet Transform** or **Superlet Transform** are particularly suitable. These methods provide high flexibility and adaptability to temporal and frequency changes in the signal, making them effective for analyzing complex, varying signals. Wavelet Transform, with its versatility and local feature extraction capability, is broadly adopted. The Superlet Transform may be chosen for even higher time-frequency resolution needs or when analyzing extremely complex signals.
4. kfuji's part
4.1 概要
PaulをマザーウェーブレットとしたCWTで生成されたスカログラムを使用した、VITモデル
4.2 前処理
- (EKG/心臓データを除く)全てのEEGデータを使用して、異なるEEGの18個のペアから差分信号を取得します。
- 18個の信号に対して、suguuuuさんの手法のCWTを適用します。データの種類を増やすために、Morletの代わりにPaulをマザーウェーブレットとして使用しました。実装はこれを使用しました。
- 最終ステップとして、得られたスカログラムを縦に結合し、512×512にリサイズします。

4.3 モデル
maxvit_base_tf_512.in21k_ft_in1kを使用しました。
4.4 学習
- 学習を通して、eeg_sub_idはeeg_idからランダムに選ばれました。
10000フレーム(50秒)の入力データは、対応するeeg_label_offset_secondsから開始されています。さらに、eeg_sub_idに割り当てられたデータは学習に利用されました。 - 学習率: 1e-3
- スケジューラー: コサインアニーリング
- 最適化: Adam
- 拡張: XYMasking
- 2ステージ学習
- ステージ1: 全データを使用
- ステージ2: 投票数が10以上のデータを使用
4.5 評価
インプット長とPaulのパラメータを変えて学習された以下の3モデルは、チームの最終submissionに統合されました。
・2000frame(10sec), Paul(m=4), CV:0.2475
・5000 frame(25sec), Paul(m=4), CV:0.2309
・5000frame(25sec), Paul(m=16), CV:0.2311
4.6 うまくいかなかったこと
・Paulの代わりにDOG(Derivative of Gaussian)を使用する。(境界線検出の手法)
・より長いインプット長(単体ではうまく機能しますが、アンサンブルには貢献しませんでした)
5. Muku's part
5.1 概要
・アーキテクチャ

5.2 モデル概要
EEGから生成した16チャネルの前後方向のモンタージュ(合成画像)に基づいて2種類の画像表現を取得し、timmによる2DCNNに入力します。
また、2種類の手法で2DCNNへの入力を作成し、各CNNの結果をアンサンブルします。
5.3 入力
・入力1
- 1D畳み込みを使用して、仮の特徴量を取得します。参考: EEGNet, G2Net Gravitational Wave Detection 1st Solution
カーネルサイズはサンプリング周波数と同じ200に設定します。 - 1D畳み込みによって得られた特徴マップを縦に結合し、timmの2DCNNに入力します。
- オプション: 得られた特徴マップをそのままGRUに入力し、アンサンブルの入力にすることもできます。
・入力2
- superletによるCWTを使用します。(使用リポジトリ)
設定:
min_freq, max_freq = 0.5, 20.0
base_cycle, min_order, max_order = 1, 1, 16
Adjusted for better resolution in the time direction
superletはSTFTと比較して時間/周波数分解能が高く、その表現は人間にも理解しやすいものとなります。
・例



5.4 モデル
timmの2DCNNを使用しました。
様々なtimmのバックボーン(基盤モデル)を探してアンサンブルを行なって下さい。
KLダイバージェンスは極端な誤差に敏感であるため、アンサンブルは有効です。
・全体として、小さなモデルの性能は良好でした
・ベストバックボーン: swinv2_tiny_window16 (CV: 0.2229)
・以下のモデルも、アンサンブルの精度向上に貢献しました。
caformer_s18
gcvit_xtiny
convnextv2_atto
maxvit_pico
inception_next_tiny
poolformerv2_s12
5.5 学習
- 2ステージ学習
- ステージ1: 投票数1より上のデータを使用
- ステージ2; 投票数9より上のデータを使用
投票数1のデータは信頼性が低いようです。学習から除外しました。(擬似ラベリングの構想もありましたが、時間が足りませんでした)
- 学習率: 1e-3(ステージ1), 1e-4(ステージ2)
- 損失関数: KLダイバージェンス, AUX(各2DCNNの出力に対して)
- スケジューラー: コサインアニーリング
- 最適化: Adam
- データ選択: 固有のeeg_idとlabelを持つデータを抽出(複数のサンプルが同じeeg_idから生成されているようです)
- ラベルスムージング: 正規化の前に0.02のオフセットをラベルに追加しました。これによってラベルが分散するため、比較的信頼度の低いと考えられる投票数の少ないラベルに、より強力な正規化が適用されます。
- データ拡張
・±5秒のランダム時間変動
・ランダムbandpass filter(波形のみ)
・XYMasking(スペクトログラムのみ) - butter bandpass filter(波形のみ)
上側のカットオフ周波数を30~40Hzに設定。高周波ノイズが増えると、'other'の投票が増える傾向にあるため、これは重要であると考えました。
5.6 うまくいかなかったこと
STFT: 時間もしくは周波数の分解能が失われるため。
感想
・CNNが優勢そうだったので、VITは頭から抜けていました。データ数10000くらいなら使用できることを覚えておきましょう。また前提のように書いてありましたが、正解ラベルの正規化は結構精度に影響しているような気もします。
・2ステージ学習において、後半は信頼性の高いデータのみを使用すると言う手法は、簡単かつ効果的に感じます。データラベル自体の正確性を疑うことも大切だと学びました。
・アンサンブルには、重み付け平均だけでなく、各モデルの予測値を利用した(非負)線形回帰を使用する手法もあることを知りました。使ってみたいです。
やはり上位陣は基礎を押さえた上で、CWTやentmaxの使用などの有効そうな手法を考案している印象です。
今回は以上です。
Discussion