【ML paper】What is BBN 【Method】
1. What is BBN(Bilateral Branch Network)?
BBN is a neural network architecture conceived for handling the long-tail problem(dataset contains few classes with major data(head classes) and many classes with few data(tail classes)), it is toxic for machine learning models but a well-seen situation in the real world.
The original paper is here.
・Performances
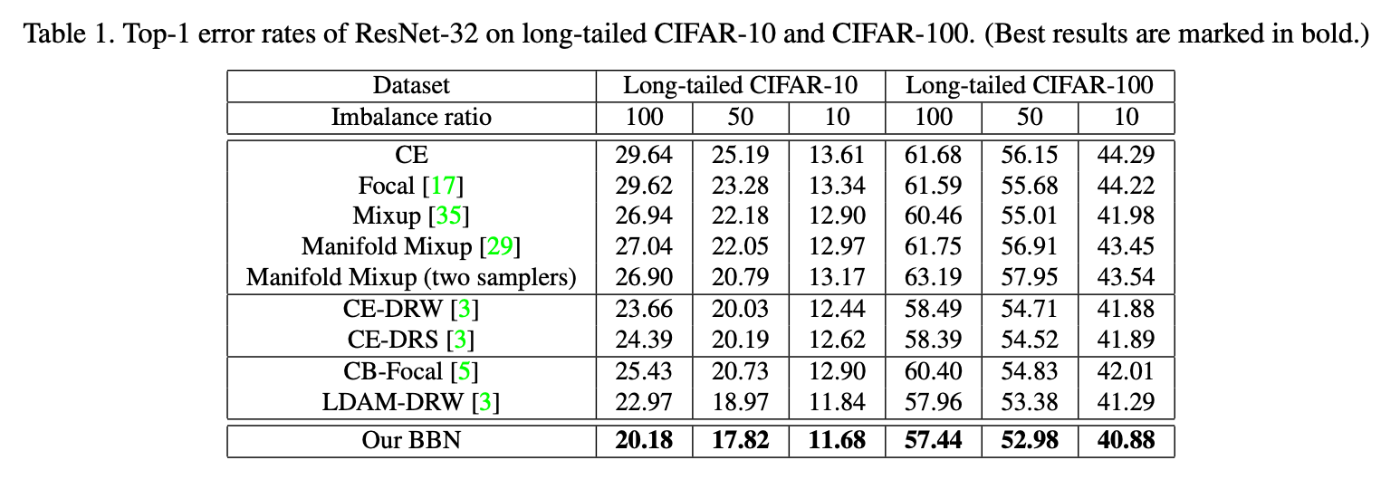
This seems to be effective for long-trailed tasks.
2. Architecture
・Architecture

BBN has two branches as itself's name. Both branches have the same residual structure from this paper and share weights without the last residual block.
There are two benefits for sharing weights:
- the well-learned representation by the conventional
learning branch can benefit the learning of the re-balancing
branch. - sharing weights will largely reduce computational complexity in the inference phase.
I think the benefit 2 is very important in a real environment.
・Conventional Branch
This branch is designed to learn the general features of the dataset. It is trained on the entire dataset, including both head and tail classes, focusing more on the overall distribution.
・Re-balancing Branch
This branch is specifically designed to improve performance in the tail classes. It applies techniques such as re-sampling or re-weighting to give more importance to the tail classes during training.
Both re-sampling(over or under-sampling) and re-weighting(class-wise weighting or sample-wise weighting that wights minor or hard-to-predict samples with higher weights) focus on making a model that can attention to minor classes.
Finally, integrate both outputs.
・
And calculate probability with softmax.
・
・
3. Reversed sampler
Reversed sampler provides data for Re-balancing Branch.
・
Randomly sample a class according to Pi, and uniformly pick up a sample from class i with replacement. This is how to make a reversed sample dataset.
4. Cumulative learning strategy
Cumulative learning proposes the shift learning strategy. It is designed to first learn the universal patterns and then pay attention to the tail data gradually.
・
This will gradually decrease as the training epochs increase to adopt for tail classes.
5. Inference
During inference, the test samples are fed into both branches, and two features
Then, the equally weighted features are fed to their corresponding classifiers (i.e.,
Reference
[1]Boyan Zhou, Quan Cui, Xiu-Shen Wei, Zhao-Min Chen, BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition, 2019
[2]Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Deep residual learning for image recognition. In CVPR, pages
770–778, 2016
Discussion