【Kaggle】BirdCLEF 2024 6th Solution explained


Hi, this time, I'll introduce 6th solution of kaggle competiton BirdCLEF2024.
0. Competiton explanation
This competition's purpose is classification to the 182 type bird calls.
The validation method is AUC-ROC, so we had to predict all of birds classes.
Competition host provide the random length audio calling data over 240000 samples as training data, and data not labeled for utilize to augmentation or otehrs.
As the problem must be addressed were:
unbalanced data, probably noisy and mixed test data, data while bird not calling, etc..
Additionaly point to be noted is the limitation of submittion. This competition only allow CPU and under 120 minutes for inference. We have to both infer and process the data in time.
If you wanna know details, reccoemnd you check the competition overview and dataset.
Solution is after here.
2. CV strategy
Unfortunately, CV is not helpful for author. So author rely to LB socre and to prevent to overfitting, reduce the submission and truncate to adjust minor hyper parameters.
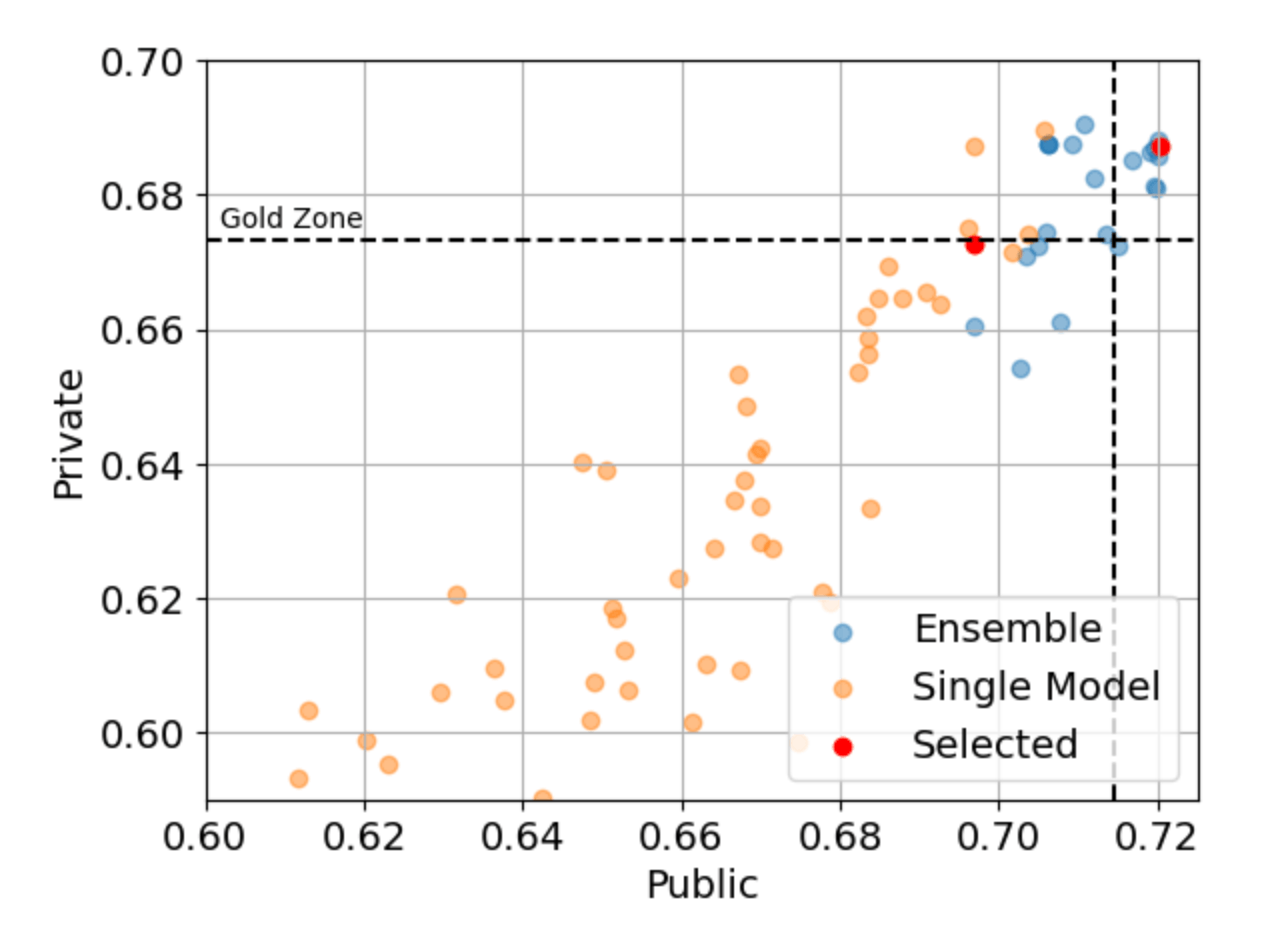
One of the final submission is best LB in public socore. But author get the result that socore get to wrose 0.02 by adding traindata, this is counter-intuitive, so author choiced another one because the result is inversing at the private score.
Actual result is this:
3. Pseudo labeling
Author used pseudo labeling and adopt multi 5sec data as input. Additionaly, change the loss calculation by whether using pseudo labeling or not.
- Not pseudo labeling
Calculate the loss after applying max func to logits and y(correct value). - Using pseudo labeling
Calculate the loss using logits and y as is.
This improve by 0.02~0.03 in publc, 0.015~0.04 in private before ensemble.
""" model.forward() """
total_loss = 0
for i in range(bs):
start = i * self.factor
end = (i + 1) * self.factor
if is_pseudo[i] == 0:
this_logits = torch.max(logits[start:end], dim=0, keepdim=True).values
this_y = torch.max(y[i], dim=0, keepdim=True).values
this_weight = torch.max(weight[i], dim=0, keepdim=True).values
loss = self.loss_function(this_logits, this_y)
if self.loss == "ce": # loss: (n_sample, )
loss = (loss * this_weight) / weight.sum()
elif self.loss == "bce": # loss: (n_sample, n_class)
loss = (loss.sum(dim=1) * this_weight) / weight.sum()
else:
raise NotImplementedError
loss = loss.sum() * self.factor
total_loss += loss
else:
this_logits = logits[start:end]
this_y = y[i]
this_weight = weight[i]
loss = self.loss_function(this_logits, this_y)
if self.loss == "ce": # loss: (n_sample, )
loss = (loss * this_weight) / weight.sum()
elif self.loss == "bce": # loss: (n_sample, n_class)
loss = (loss.sum(dim=1) * this_weight) / weight.sum()
else:
raise NotImplementedError
loss = loss.sum() / self.factor
total_loss += loss
4. Post processing
Calculate a moving average with weights of [0.1, 0.2, 0.4, 0.2, 0.1] and add the value that [global average * 0.2] for each species at last.
This boosted public and private LB by 0.014~0.016 consistently, in both final submissions.
def smooth_array_general(array, w=[0.1, 0.2, 0.4, 0.2, 0.1]):
smoothed_array = np.zeros_like(array)
timesteps = array.shape[0]
radius = len(w) // 2
for t in range(timesteps):
for i, weight in enumerate(w):
index = t - radius + i
if index < 0:
smoothed_array[t] += array[0] * weight
elif index >= timesteps:
smoothed_array[t] += array[-1] * weight
else:
smoothed_array[t] += array[index] * weight
for c in range(array.shape[1]):
smoothed_array[:, c] = smoothed_array[:, c] * 0.8 + smoothed_array[:, c].mean(keepdims=True) * 0.2
return smoothed_array
5. Other Setting
- resampling became a bottleneck, so preprocess sampled to 32 kHz and storing them on disk helps speed up the training phase.
- sampling by RMS (+0.010)
RMS sampling > using first 5sec > random sampling - backbone
resnet18d, resnet34d and efficientnetv2s
Thank you for reading
It is helpful, but I don't know what is RMS sampling... Please tell me if you know.
6. Summary
This is a simple and strong solution. In my opinion, the pseudo labelng and smoothing post process is critical element.
This time is over, please see the original solution on kaggle.
Discussion