Linuxの各種仮想ネットワークデバイスにおけるSegmentation Offloadの振る舞い
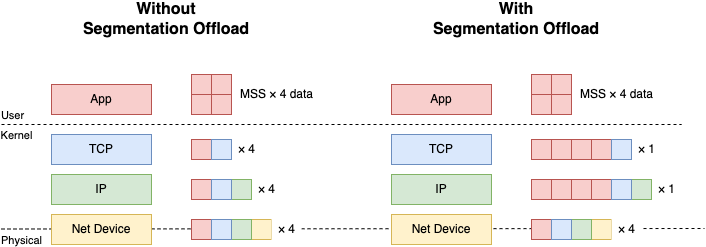
LinuxにおけるSegmentation OffloadとはTCPなどのトランスポートレイヤのプロトコルが送信するデータをMTUに収まるように分割する処理(Segmentation)をNICのレイヤにオフロードすることによってスループットを向上させる技術です. Segmentation Offloadを使った場合, トランスポートレイヤのプロトコルはIPレイヤで許容される最大のサイズ(64KB程度)までのデータを1つのIPパケットで送信することができます. 受信側は逆にネットワークから入ってきたSegmentation済みのパケットをNICのレイヤで1つの大きなIPパケットに集約した上でプロトコルスタックの処理にかけます. これによってプロトコルスタックで処理されるパケットの個数を減らすことができるため, スループットが上がるという仕組みです.
Linuxには仮想ネットワークデバイスという概念があります. LinuxにおけるNetwork Deviceは必ずしも物理的なNICに対応しているとは限りません. あたかも物理的なNICのように振る舞いながら中ではGREやVXLANなどのencap/decapをするtunneling deviceや, veth, virtio-net, bridge, vrfなどもLinuxにおいてはNetwork Deviceとして抽象化されており, プロトコルスタックは物理的なNICと仮想デバイスを区別しません.
昨今のWebアプリケーションはVMやコンテナのオーケストレータ (例えばKubernetes) の上で動かすケースがほとんどだと思われます. こういったオーケストレータの実装では仮想デバイスが多用されています. アプリケーションのコンテナやVMからvethやvirtio-netを通って, VXLANデバイスでencap/decapを行い, その後物理デバイスからパケットを送信といった構成はよくあります. こういったインフラを組むにあたってSegmentation Offloadがどう振る舞うのかを知ることは, アプリケーションのスループットを最大化すること, あるいは予想外のボトルネックを作らないことに役立ちます.
このポストでは主にVMやコンテナのオーケストレータでのユースケースを念頭にVirtual Network DeviceのSegmentation Offloadのハイレベルな振る舞いに関して解説します.
LinuxにおけるSegmentation Offloadの仕組み
LinuxにはSegmentation Offloadは大まかにはソフトウェア実装とハードウェア実装があり, ソフトウェア実装の送信側をGeneric Segmentation Offload (GSO), 受信側をGeneric Receive Offload (GRO)と呼びます. ハードウェア実装の呼び方はベンダによってまちまちですが, ベンダ非依存な呼び方としては送信側はTransmission Segmentation Offload (TSO), 受信側はLarge Receive Offload (LRO) と呼ぶことが多いです. ハードウェア実装はソフトウェア実装に比べてホストのCPUを消費しないというメリットがあります (スループットに大きな違いは無いようです).
デバイスによるSegmentation Offloadのサポートの有無は ethtool を使って確認することができます. これは自分のLinuxラップトップについているWifiモジュールの例です.
$ ethtool -k wlp0s20f3 | grep -e "receive-offload" -e "segmentation"
tcp-segmentation-offload: on
tx-tcp-segmentation: on
tx-tcp-ecn-segmentation: off [fixed]
tx-tcp-mangleid-segmentation: off
tx-tcp6-segmentation: on
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]
tx-fcoe-segmentation: off [fixed]
tx-gre-segmentation: off [fixed]
tx-gre-csum-segmentation: off [fixed]
tx-ipxip4-segmentation: off [fixed]
tx-ipxip6-segmentation: off [fixed]
tx-udp_tnl-segmentation: off [fixed]
tx-udp_tnl-csum-segmentation: off [fixed]
tx-tunnel-remcsum-segmentation: off [fixed]
tx-sctp-segmentation: off [fixed]
tx-esp-segmentation: off [fixed]
tx-udp-segmentation: off [fixed]
各プロトコルごとにSegmentation Offloadingのサポートの有無が出力されています. [fixed] は変更不可能なパラメータを指しています. つまり off [fixed] は「サポートされていない」と同義です. カーネルはこのデバイスごとのサポート状況を見て送信されるパケットをデバイスがSegmentationできるかどうかを確認します. もしできなければGSOを使ってSegmentationを行い, できるのであればSegmentationをせずにパケットをデバイスドライバに渡します. 受信側は逆にデバイスドライバ側から来たパケットが集約済みならそのままプロトコルスタックにパケットを渡し, そうでなければGROで集約処理を行います. デバイスドライバ内部でのSegmentationの処理はデバイス依存です.
仮想デバイスにおけるSegmentation Offloadの原則
原則としてLinuxは物理NICにパケットが到達するまで可能な限りSegmentationを遅延するように動きます. 多くの場合仮想デバイスに入ったパケットはその後もソフトウェアで処理されるため, Segmentationをしないほうが効率的だからです. 仮想デバイスにおけるSegmentation Offloadの振る舞いはデバイスごとに違いますが, この原則は共通しています.
具体例としてvethの実装を取り上げます. vethのSegmentation Offloadはパケットを一切Segmentationすることなくペアのvethにパススルーします. こうすることによって例えばコンテナからホストの物理NICまでSegmentationをすることなく効率的にパケットを処理できます.
これをどうやって実現するのかというと, vethはカーネルから見るとあらゆるプロトコルのSegmentation Offloadingをサポートしたデバイスに見えるようになっています.
$ ethtool -k veth0 | grep -e "receive-offload" -e "segmentation"
tcp-segmentation-offload: on
tx-tcp-segmentation: on
tx-tcp-ecn-segmentation: on
tx-tcp-mangleid-segmentation: on
tx-tcp6-segmentation: on
generic-segmentation-offload: on
generic-receive-offload: off
large-receive-offload: off [fixed]
tx-fcoe-segmentation: off [fixed]
tx-gre-segmentation: on
tx-gre-csum-segmentation: on
tx-ipxip4-segmentation: on
tx-ipxip6-segmentation: on
tx-udp_tnl-segmentation: on
tx-udp_tnl-csum-segmentation: on
tx-tunnel-remcsum-segmentation: off [fixed]
tx-sctp-segmentation: on
tx-esp-segmentation: off [fixed]
tx-udp-segmentation: on
つまりカーネルはほとんどの場合, GSOにフォールバックすることなくvethのデバイスドライバにSegmentationの処理を任せます. しかしvethのドライバは内部的には一切Segmentationをせずにパケットをペアのvethにパススルーしているというわけです. 他のデバイスでも基本的にこのやり方は同じです. 後に説明するようにデバイスごとに固有の処理はあるものの, 結局はドライバの中でSegmentationを行わずにパケットを通過させるという点は共通しています.
ここからは各デバイスごとの固有処理について解説していきます.
トンネルデバイス
トンネルデバイスはIPIP, GRE, VXLAN, GeneveなどのトンネリングプロトコルのLinuxにおける実装です. ルーティングによってトンネルデバイスに入ったパケットはトンネルプロトコルのヘッダでencapされた後, プロトコルスタックで再処理されます. Segmentationされたパケットに関しても同様です. トンネルデバイスのドライバはパケットをencapした後にSegmentationをせずにプロトコルスタックに渡します.
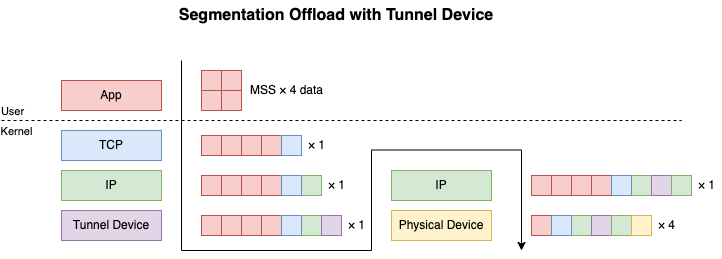
ここまでは簡単なのですが, 問題はencapされたパケットが物理NICに到達した時の処理です. EncapされたパケットをSegmentationする場合には内側のパケットをSegmentationした上で外側のトンネリングプロトコルのヘッダでそれぞれのパケットをencapする必要があります. つまり物理NICでSegmentationをさせるためにはNIC側がこの処理をサポートしている必要があります. ethtool の出力で言えば以下のような機能がOnになっている必要があります. もし物理NICがこれらの機能をサポートしていない場合はGSOで処理されます.
tx-gre-segmentation: on <= GRE
tx-ipxip4-segmentation: on <= IPv4 in IPv4 (IPIP)
tx-ipxip6-segmentation: on <= IPv4 in IPv6 もしくは IPv6 in IPv4
tx-udp_tnl-segmentation: on <= VXLAN, GeneveなどのUDP encap
二段トンネル
二段以上のトンネルでのSegmentation Offloadはサポートされていません. 2回目のencapをするためにパケットをトンネルデバイスに転送した時点でGSOによってSegmentationをされてしまいます.
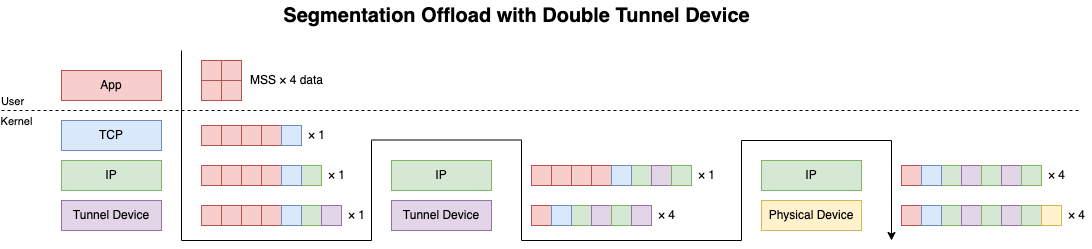
仕組みとしてはトンネルデバイスが tx-gre-segmentation などのencap系のSegmentationをサポートしておらず, カーネルがGSOにフォールバックするようになっています. 以下はIPIPデバイスの例です.
$ ethtool -k tunl0 | grep -e "receive-offload" -e "segmentation"
tcp-segmentation-offload: on
tx-tcp-segmentation: on
tx-tcp-ecn-segmentation: on
tx-tcp-mangleid-segmentation: on
tx-tcp6-segmentation: on
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]
tx-fcoe-segmentation: off [fixed]
tx-gre-segmentation: off [fixed]
tx-gre-csum-segmentation: off [fixed]
tx-ipxip4-segmentation: off [fixed]
tx-ipxip6-segmentation: off [fixed]
tx-udp_tnl-segmentation: off [fixed]
tx-udp_tnl-csum-segmentation: off [fixed]
tx-tunnel-remcsum-segmentation: off [fixed]
tx-sctp-segmentation: on
tx-esp-segmentation: off [fixed]
tx-udp-segmentation: on
つまり, 2回目のencap以降はencap処理自体も, その後のプロトコルスタックの処理もSegmentationされたパケットごとに行われます. これにはかなりのパフォーマンスペナルティがあります. 以下はローカルのマシンで2つのNetnsをvethで直接接続した上でトンネルの段数を増やしながらiperfをした結果です. ローカルでの計測なので実機での結果とは全く違いますが, パフォーマンスに対する影響を確認するには十分でしょう.
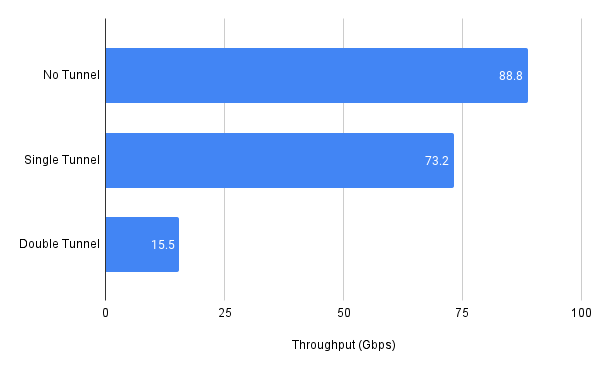
2段目から急激にスループットが下がることが確認できます. これはNo TunnelのケースとSingle TunnelのケースではEnd-to-EndでSegmentationが行われずにパケットが処理されるのに対してDouble Tunnelの場合は二段目以降のEncapではSegmentationが行われるためです. 二段トンネルはネットワークの要件的にやらなくてはならないケースもありますが, 可能な限り避けたほうがいいでしょう.
Bridge, VRF
BridgeデバイスやVRFデバイスは入ってきたパケットを内部的に保持しているL2 Forwarding DBあるいはL3 FIBにかけてスイッチングやルーティングを行うデバイスです. パケットが入ってくる経路がBridgeやVRFにアタッチされているデバイスから入ってくるケースとBridgeやVRFにパケットがルーティングなどによって転送されるケースの二つあり, それぞれで挙動が違います.
アタッチされているデバイスからパケットが入った場合は転送処理のみが行われ, Segmentationは行われません. 一方でルーティングによってパケットが入ってきた場合には他のデバイスと同様に処理されます. Bridgeではほとんど全てのプロトコルのSegmentationがサポートされている一方でVRFはencap系のSegmentationがサポートされていません. なぜこの違いがあるかの経緯に関しては今回調べきれませんでした.
$ ethtool -k bridge | grep -e "receive-offload" -e "segmentation"
tcp-segmentation-offload: on
tx-tcp-segmentation: on
tx-tcp-ecn-segmentation: on
tx-tcp-mangleid-segmentation: on
tx-tcp6-segmentation: on
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]
tx-fcoe-segmentation: on
tx-gre-segmentation: on
tx-gre-csum-segmentation: on
tx-ipxip4-segmentation: on
tx-ipxip6-segmentation: on
tx-udp_tnl-segmentation: on
tx-udp_tnl-csum-segmentation: on
tx-tunnel-remcsum-segmentation: on
tx-sctp-segmentation: on
tx-esp-segmentation: on
tx-udp-segmentation: on
$ ethtool -k vrf0 | grep -e "receive-offload" -e "segmentation"
tcp-segmentation-offload: on
tx-tcp-segmentation: on
tx-tcp-ecn-segmentation: on
tx-tcp-mangleid-segmentation: on
tx-tcp6-segmentation: on
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]
tx-fcoe-segmentation: off [fixed]
tx-gre-segmentation: off [fixed]
tx-gre-csum-segmentation: off [fixed]
tx-ipxip4-segmentation: off [fixed]
tx-ipxip6-segmentation: off [fixed]
tx-udp_tnl-segmentation: off [fixed]
tx-udp_tnl-csum-segmentation: off [fixed]
tx-tunnel-remcsum-segmentation: off [fixed]
tx-sctp-segmentation: on
tx-esp-segmentation: off [fixed]
tx-udp-segmentation: on
virtio-net
virtio-netの規格には実はSegmentation Offloadの仕様が盛り込まれており, それを実装したvirtio-netはゲストとホストを跨いでSegmentationをせずにパケットをパススルーすることができます. ゲスト側のLinuxではvirtio-netはこのように見えます.
$ ethtool -k ens2 | grep -e "segmentation" -e "receive-offload"
tcp-segmentation-offload: on
tx-tcp-segmentation: on
tx-tcp-ecn-segmentation: on
tx-tcp-mangleid-segmentation: off
tx-tcp6-segmentation: on
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]
tx-fcoe-segmentation: off [fixed]
tx-gre-segmentation: off [fixed]
tx-gre-csum-segmentation: off [fixed]
tx-ipxip4-segmentation: off [fixed]
tx-ipxip6-segmentation: off [fixed]
tx-udp_tnl-segmentation: off [fixed]
tx-udp_tnl-csum-segmentation: off [fixed]
tx-tunnel-remcsum-segmentation: off [fixed]
tx-sctp-segmentation: off [fixed]
tx-esp-segmentation: off [fixed]
tx-udp-segmentation: off [fixed]
TCPのSegmentation Offloadがサポートされているため, ゲストのカーネルはvirtio-netのゲスト側のドライバにSegmentationされていないパケットを渡します. virtio-netのゲスト側ドライバはゲストとホストの共有メモリ (virt-queue) にSegmentation Offloadに関するメタデータとパケットを書き込んでホスト側にパケットを送信します.
Linuxがホストの場合, virtio-netのバックエンドには多くの場合tun/tapデバイスが使われています. tun/tapデバイスにはvirtio-netの規格で定められている特別なヘッダをパケットに付加することでSegmentation Offloadに必要なメタデータをパケットと一緒に送受信することができる機能があります. QEMUのvirtio-netのドライバやvhost-netはこの機能を使ってホストのLinuxカーネルとSegmentation Offloadの情報をやり取りしています. この辺りの仕組みの詳細に関してはこのブログによくまとまっていました.
まとめ
Linuxの各種仮想デバイスにおけるSegmentation Offloadのハイレベルな振る舞いについて解説しました. Segmentation Offloadingは 「とりあえず切るのがベストプラクティス」 のような言説も (少なくとも自分の周りでは) 一時期よく耳にしたのですが, サーバの高帯域化が進む中で切ることの不利益が大きい機能になっていると思います. 自分は数年間OpenStackやKubernetesなどのネットワークレイヤの開発をする中で幾度となくSegmentation Offloadingでハマった実績があり, 他にもネタがたくさんあるので, 気が乗ったときにどこかで書きたいと思います.
Discussion