10月5日に起きたFacebook障害のポストモーテムを勝手に考えてみる
もちろん私はFacebookのエンジニアでもなければ知り合いがいるというわけでもないのですが,日本時間10月5日未明に起きたFacebookの大規模障害について勝手にポストモーテムを書いてみました.
ポストモーテム(postmortem)とは”検死”という意味であり,『SRE サイトリライアビリティエンジニアリング』15章「ポストモーテムの文化:失敗からの学び」でも有名となっているインシデントの事後記録のようなものです.
インシデントから学びを得るための定式化されたプロセスがなければ,そういったインシデントは無限に繰り返されることになるでしょう.(中略)ポストモーテムを書くことの主な目的は,インシデントがドキュメント化されること,影響を及ぼしたすべての根本原因(群)が十分に理解されること,そしてとりわけ,最初の可能性や影響を削減するための効果的な予防策が確実に導入されるようにすることです.
発生した事象についてはメディアやブログの内容を基にしています.
Postmortem of Facebook outage
Date
- 2021-10-05(時刻は以後全て日本時刻)
Authors
- yutafujii
Status
- 現在は復旧
- 設計の見直しを行なっている
Summary
バックボーンネットワークのメンテナンス時に利用するconfigurationを変更したところ,内部ネットワークが切断され,さらにBGPも自動的に切断されたため同社の保有するサービス全体がインターネットから遮断される事態を招いた.データセンターへの入館が必要になり復旧に6時間を要した.
Impact
- 期間:2021-10-05 1:00AM頃〜7:00AM頃
- 影響:
- Facebook社のアプリ(Facebook, Instagram, WhatsApp, Messenger, Oculus)全てが利用不可能に
- 35億人程度のユーザーに影響
- 特にミャンマーやインドなど情報統制が敷かれる国々においてはFacebookがインターネットと同等に扱われるためその深刻度は大きかった
- Omniauthのプロバイダとしても機能しなくなったため,ユーザーはFacebook認証で利用していたサービスにもログインができなくなった
- Facebookの社内システムについてもスケジューリングツール,メモなどが利用不可能に
- Facebook社員のオフィス入館証カードも機能しなくなり,ゲート通過などが行えなくなった
Root Causes
- メンテナンス時に利用されるconfigurationの値を変更したところ(キャッシュと永続ストアのうち永続ストアのコピーで変更を行なった)値がinvalidであったこと
- configurationを自動で検証するシステムが稼働していたのだが,エラーハンドリングが不幸にもフィードバックループを生じさせる作りになってしまっていたこと
- FacebookのDNSサーバーはデータセンターとの接続不能を検知すると自身をインターネットから切断する作りになっていたこと
Trigger
- バックボーンネットワークの定期メンテナンスジョブ
- グローバルバックボーン全体のキャパシティを評価するために実行されたコマンド
Resolution
- データセンターへ入りconfiguration値を正しいものに戻した
Detection
- 社内外ユーザーからの不具合報告
- システムダッシュボードアラート(ただし通知されなかった可能性もある)
Supplemental Explanation
バックボーンのデータセンター通信が遮断された経緯
バックボーンの定期メンテナンスでconfigurationの検証を行う際に,キャッシュされているconfigの値を検証し,invalidな場合は永続ストア(persistent store)からアップデートをかける監査コマンドが稼働していた.
しかし,今回は変更した永続ストアコピーの方がinvalidだった.このためクライアントがサービスを利用するたびにアップデート処理が走った.
アップデート処理にはデータベースへクエリ発行が含まれており,この結果DBクラスタに秒間数十万回のリクエストが送られてしまった.
さらに,DBへのクエリでエラーが生じるとさらに自身に対するリクエストを生み出すフィードバックループが発生する仕組みになってしまっていた.
その結果グローバルで全てのデータセンターがdisconnectされる事態となってしまった.
Facebook全体がインターネットから切断されたとはどういうことか
前提として,バックボーンやISP,BGPなどはインターネットの構成要素.
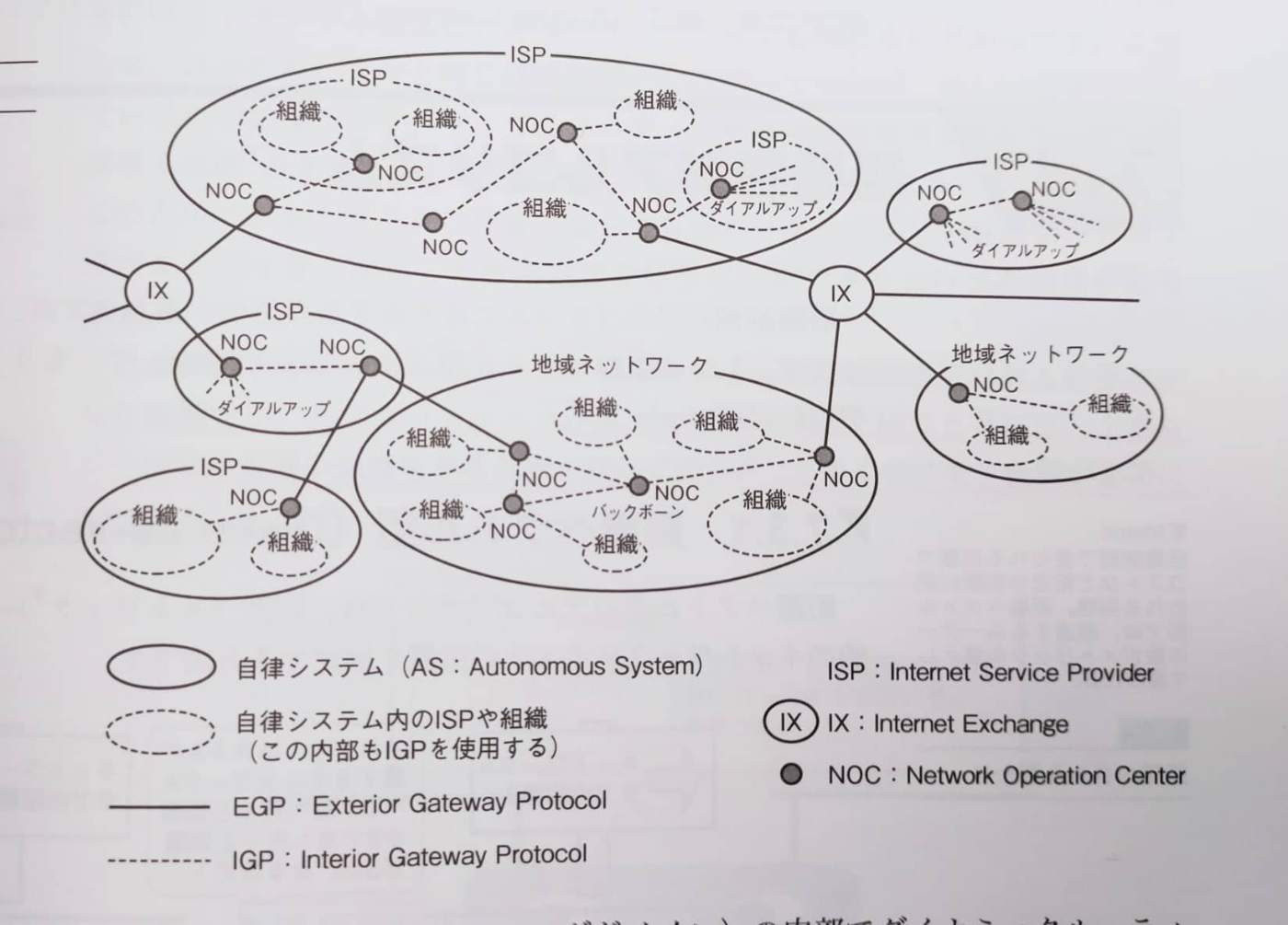
出所)マスタリングTCP/IP
図のEGPの一種がBGP(Border Gateway Protocol)
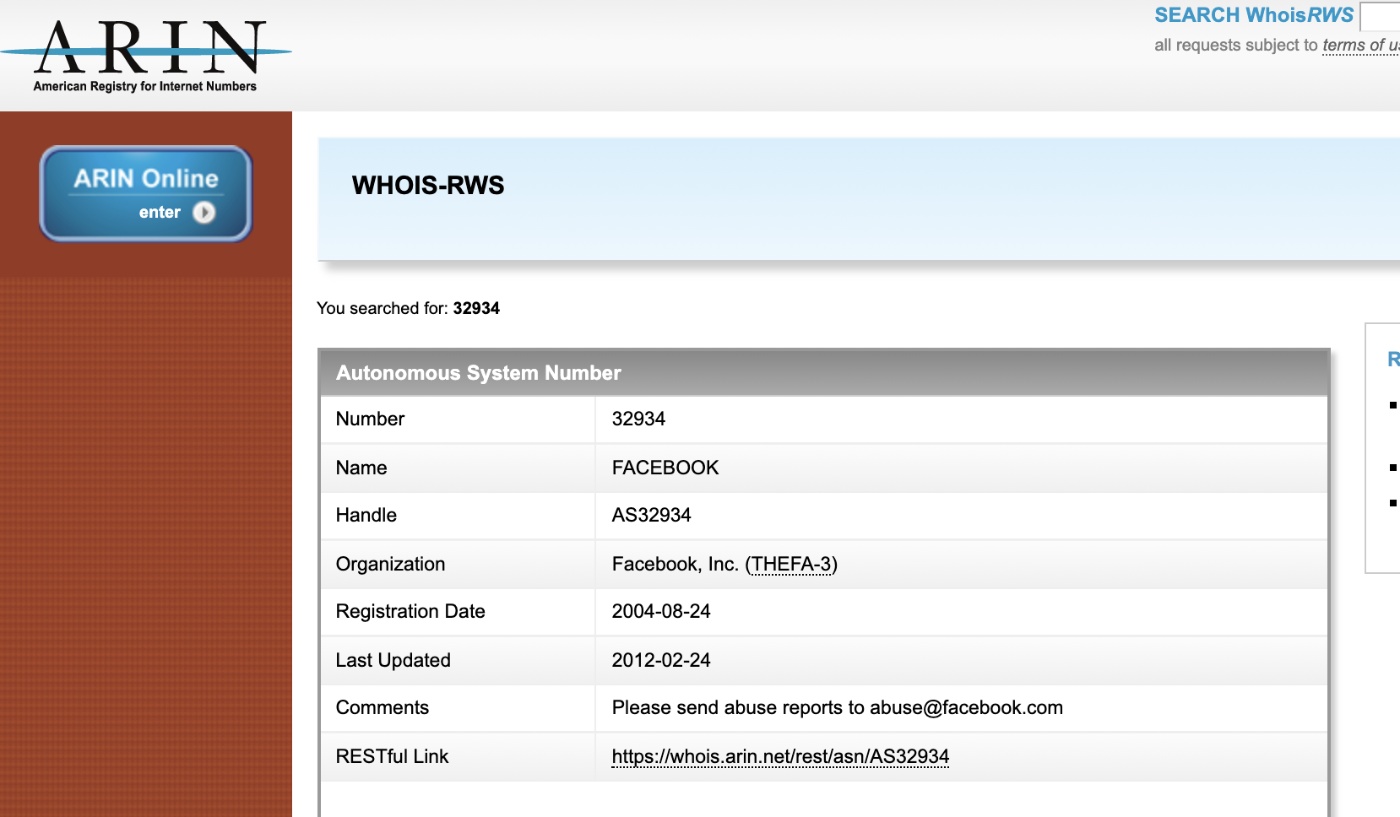
参考)Facebookの自社ネットワーク(Autonomous System)はID32934が振られている.
Facebookの自社ネットワークとISPの関係は以下の通り:

出所)Youtube
Facebookネットワーク内部にDNSサーバーが4台稼働している(ルートネームサーバーに対してdigコマンドでwww.facebook.comを照会することで確認できる)

障害発生時,FacebookのDNSサーバーはデータセンターとの接続不能によりBGPアドバタイズメントを自動でDisabledにした
実際に,障害発生時と障害回復後で,ISP(AT&T)サーバーからルーティング可能だったIPアドレスを比較した結果,上記のネームサーバーIPが確かに欠損していることからも,Facebookが事実上インターネットから切断してしまっていたことが伺える.

出所)Youtube
*確認コマンドはshow route aspath-regex ".* 32934" active-pathだが,私はISPサーバーへアクセスできないのでこのコマンドは未検証
Lessons Learned
- データセンターを含むバックボーン障害時に自社DNSサーバーがインターネットから切り離されてしまうとわかった.よりgracefulにシステムを閉じる処理を検討した方が良い(fail-safeな設計の検討)
- BGPを切断すると社内システムにもアクセス不能になってしまうとわかった.今後は,社内システムへのアクセスを障害発生時にも担保できるネットワーク設計を検討したい
- 認証されていないアクセスを防ぐための物理的・システム的なセキュリティレベルの向上が,障害発生時の復旧時間(Time To Recovery)を増加させてしまうトレードオフを認識した
What went well
- 大規模システム障害に対する復旧の予行演習や,インフラに対するストレステストを日頃から実施していたおかげで,復旧時に一気にシステムリソースが稼働し電力利用スパイクを起こすことなく復旧することができた
What went wrong
- 実行されるコマンドの監視ツールを入れていたが,そのツールにバグがあり今回のシャットダウンを通過させてしまった
- 初期障害によりDNSサーバー自体がインターネットから接続できなくなったため障害の状況を把握するための社内システムにもアクセスができなくなった
- 物理的にもシステム的にも厳重なセキュリティ対策が講じられていたため,データセンター到着後に実際に建物に入りハードウェア・ソフトウェアの変更を行うまで時間がかかった
Where we got lucky
- 特になし
Timeline
10/05 01:00頃? -- バックボーンネットワークのルーティンメンテナンスが開始される
10/05 01:05頃? -- グローバル全体のバックボーンキャパシティ測定コマンドが発行される
10/05 01:05頃? -- 当該コマンドが意図せずバックボーンのネットワークを削除してしまいデータセンターをグローバルに遮断してしまう(初期障害発生)
10/05 01:05頃? -- データセンターとの接続がunhealthyになったことを感知したFacebookの4台のDNSサーバーは,それぞれBGPアドバタイズメントをDisabledにした.これによりDNSサーバーがインターネットから接続不能になった(二次障害発生)
<FacebookのDNSネームサーバー>
a.ns.facebook.com
b.ns.facebook.com
c.ns.facebook.com
d.ns.facebook.com
10/05 01:07 -- Communication execのAndy StoneがTwitterで不具合を認識している旨報告
10/05 01:22 -- 公式Twitterアカウントで障害認識を報告
10/05 ??:??頃 -- カリフォルニア州Santa Claraにあるデータセンターへエンジニアが到着
10/05 ??:??頃 -- 事態の確認とバックボーンの復旧作業を実施.バックボーンはonlineに戻る
10/05 ??:??頃 -- 同社のグローバルセキュリティオペレーションセンターが本件を「a HIGH risk to the People, MODERATE risk to Assets and a HIGH risk to the Reputation of Facebook」として社内にレポート
10/05 04:52 -- 同社CTOのMike Schroepferがネットワーク問題であるとTwitterで状況を報告
10/05 06:30頃 -- 一部のISPの運営するDNSサーバーがfacebook.comを解決できるようになっているとの報告があがる
10/05 -- 障害の情報アップデートをFacebook Engineeringブログで公表
10/06 -- 障害のさらに詳細な情報をFacebook Engineeringブログで公表
以上です.今回の障害はそれ自体も勉強になる知識や気をつけるポイントがあるので,ぜひ以下の参考記事も読んでみてください.
参考
- https://m.facebook.com/nt/screen/?params={"note_id"%3A10158791436142200}&path=%2Fnotes%2Fnote%2F
- https://engineering.fb.com/2021/10/04/networking-traffic/outage/
- https://engineering.fb.com/2021/10/05/networking-traffic/outage-details/
- https://www.youtube.com/watch?v=-wMU8vmfaYo
- https://www.nytimes.com/2021/10/04/technology/facebook-down.html
- 『マスタリングTCP/IP』
- 『SRE サイトリライアビリティエンジニアリング』
Discussion