【Go】並行ゴルーチンと並列ゴルーチンを理解する
はじめに
Goで開発する上で非常に重要なゴルーチンですが、初学者である自分はまず、「並行処理」「並列処理」の違いの理解に悩みました。
そして、なんとなくの理解できたような気がしたところで、ずっと以下のように思っていました。
「じゃぁGoでは並行処理しか出てこなくて、並列処理は登場しないのだな....」
実際、ゴルーチンは「並行処理」を可能にするものです。
しかし、上の思い込みは間違いでした。ゴルーチンを用いて「並列処理」を実装することも可能です。
混同しがちな「並列処理」「並行処理」を整理するとともに、ゴルーチンはいつ「並行」or「並列」なのかがとても気になったので、調べつつ、記事としてまとめてみたいと思います。
TL;DR
- IO/Boundな処理はゴルーチンがブロッキングしコンテキストスイッチが発生するため、「並行処理」
- CPU Boundな処理は、ゴルーチンのコンテキストスイッチが発生しにくいため、「並列処理」の可能性が高い
並列処理と並行処理を整理する
まずは、2つの言葉の違い、その関係性について例を交えながら述べていきます。
並列処理
"Programming as the simultaneous execution of (possibly related) computations."
訳:(関連している可能性のある)計算を同時に実行するプログラミング。
https://go.dev/talks/2012/waza.slide#7
並列処理とは、多くのことを同時に実行することとされています。
レストランの例:3つのテーブルに対して店員が3人
レストランの店員を例として、考えてみます。
店員の行う業務フローとして「注文を取る→料理を作る→料理を提供する→片付ける」の4つがあるとしましょう。
A・B・Cのテーブルがあり、3人の店員がいます。
店員はそれぞれのテーブル専用につけるので、見かけ上は3つのテーブルで同時に「注文〜料理〜提供〜片付け」までの一連のフローを行います。これにより、各テーブルが完全に独立して処理が動くので、時間短縮につながりそうですね(後述しますが、よく考えてみるとこの例では並列の利点をうまく受けられていません)。
つまり、「多くのことを同時に実行」していると言えます。これが並列処理です。

並行処理
"Programming as the composition of independently executing processes."
訳:独立して実行されるプロセスの構成としてのプログラミング
https://go.dev/talks/2012/waza.slide#6
並行処理とは、多くのことを同時に扱うこととされています。
レストランの例:3つのテーブルに対して店員が1人
こちらも同じ例で考えます。
A・B・Cのテーブルに対して、1人の店員がいます。
この場合、1人の店員は、それぞれのテーブルに対して、業務を切り替えながら仕事をします。
「Aの注文を取る」▶️「Bの注文を取る」▶️「Aの料理を作る」▶️「Cの注文を取る」▶️「Aに料理を提供する」といった感じです。
つまり、「多くのことを同時に扱っている」と言えます。これが並行処理です。

これが「並行処理」ではなく「逐次処理」だった場合を考えると、この店員の有能さがわかります。
それぞれのテーブルへ逐次的に接客を行う場合、以下のようにになります。
- 「Aの注文を取る」▶️「Aの料理を作る」▶️「Aに料理を提供する」▶️「Aのテーブルを片付ける」
- 「Bの注文を取る」▶️「Bの料理を作る」▶️「Bに料理を提供する」▶️「Bのテーブルを片付ける」
- 「Cの注文を取る」▶️「Cの料理を作る」▶️「Cに料理を提供する」▶️「Cのテーブルを片付ける」

BやCのテーブルはかなり待たされることになります。これでは客が怒って帰ってしまいそうです。
仮に、Bの方が先に注文可能な状態だったり、客の食事時間の長短もあるとすれば、このやり方は非効率です。
なんとなくイメージできたでしょうか。
並行処理=構成、並列処理=実行
「並行処理」と「並列処理」が異なるものだということは、例を持って理解できたかと思います。
が、二つは完全に交わらないわけではありません。
In programming, concurrency is the composition of independently executing processes,while parallelism is the simultaneous execution of (possibly related) computations.
訳:プログラミングにおいて、並列処理は(関連する可能性のある)処理を同時に実行することであるのに対し、並行処理はプロセスをそれぞれ独立に実行できるような構成のことを指します。
- 並列処理は、処理を同時に行う「実行」を指す
- 並行処理は、処理を独立して実行できるような「構成」を指す
再考:レストランの例
先のレストランの例で考えてみます。
並列処理は、「実行」を指すと言いました。
3人の店員を使うことで、一連の業務フローを、各テーブル(A・B・C)に対して一度に「実行」しています。
説明そのままですが、並列処理は複数を同時に「実行」することなのです。
一方、並行処理は「構成」を指すと言いました。
これは、一連の業務フローを分解し、独立して取り組める「ステップ」を導入することにより、各テーブルに対する逐次処理ではなく、並行して各ステップ単位で仕事を行えるようにしているということです。
これは、店員という1リソースを効率的に活用できていると言えます(響きがブラック企業ですね。ワンオペお疲れ様...)。
このように、並行処理は実行の単位を細分化し、並行に処理できるようにしたという「構成」なのです。
並列処理という構成が並列処理を可能にする
ここで重要なことは、並行処理が並列処理を可能にするという点です。
並行処理によって独立した「ステップ」に細分化したことで、特定の「ステップ」に対して並列処理を行えるようになるのです。これにより、リソースを効率的に使い、実行時間を短縮することが可能です。
また、例を用いて考えてみましょう。
再考:レストランの例
1つ目の例では、各テーブルに対し3人の店員を使って同時に業務を行う「並列処理」を行なっていました。
しかし、1人1人が各テーブルについて一連の業務を逐次的に行なったとしても、実行時間が超短縮されて、効率的なのかと言えば、答えはNOです。
現実の細かすぎる設定はさておきとしますが、各テーブルについた店員は以下のケースで「待機」します。
- 客が注文を考えている時間
- 客が食べている時間(片付け待ち)
これでは、リソース(店員)を余している状態が発生してしまいます。効率的とは言えなさそうですね。

では、同じ3人を使う場合でも、3人の使い所を変えてみましょう。
1人は、「注文を取る」「料理を提供する」「片付ける」仕事(以下、ホール業務)をA・B・Cのテーブルに対して並行的に行なってもらいます。
2人は、「料理を作る」という工程に投入します。

この構成に変えると、何が良くなりそうでしょうか。
1人の店員で並行してホール業務を行えるので、テーブルAが注文考え中の間に、テーブルCの注文を取ったり、テーブルBが食事中の間にテーブルAの片付けを行えます。
そして、「料理を作る工程」に2人のリソースを割くことにしました。
これは、料理を作る工程を 「並列処理」していると言えそうです。
料理は、(細かいことは置いといて)人数が多い方が出来上がるスピードが上がりますよね(多分)。
リソースは投入しがいのあるところに投入すべきでしょう。
これで、効率的かつ素早くお客さんをおもてなしできるようになったのではないでしょうか。
このように、「並行処理」の構成をとることで、その中でしかるべきところを「並列処理」で実行でき、全体的な実行時間を短縮し、効率化を図ることができるのです。
ゴルーチンとは
並行処理と並列処理についてイメージしやすくなったところで、この記事の主役である「ゴルーチン」とは何かをこの節で取り上げます。
goroutineは「ファイルI/Oやネットワーク通信でブロックしている間にもランタイムが選んだCPUコアで別の処理を並行して行うことで単純な並列処理よりも効率的に処理を行う」を主題にしているランタイムの機能です。
mattn. Go言語プログラミングエッセンス エンジニア選書 (p. 273)
非常に端的でわかりやすい一文でしたので、そのまま引用させていただきました。
また、ゴルーチンは、OSレベルではない、アプリケーションレイヤーにおけるGo独自のスレッド実行を行なっています。それにより、とても軽量なスレッドを実現しています。
軽量なスレッド?
軽量なスレッドって何?そもそもスレッドって何?という話を述べます。
スレッドとは、「処理の実行単位」を指します。
Goにおいてこのスレッドを考える際、2種類に分けることができると考えています。
- カーネルスレッド(OSによって管理される実行単位)
- ゴルーチン(Goランタイムによって管理される実行単位 ≒ 軽量スレッド)
この二つの違いを理解するには、「コンテキストスイッチ」という概念を知る必要があります。
OSレベルで並行処理を行う際、カーネルスレッドをコンテキストスイッチしながら処理を進めることになります。OSレベルという低レイヤな部分まで介するこの動作は非常にコストが高そうということは想像できます。消費するメモリサイズはOSに依存しますが、Linux/x86-32では約2MBだそうです(Go言語 100Tips ありがちなミスを把握し、実装を最適化するより)。
それに対して、ゴルーチンはGoランタイムによって管理される、アプリケーションレベルのスレッドです。同じくゴルーチンもコンテキストスイッチのオン・オフにより処理されます。注目すべきは、カーネルスレッドにおけるコンテキストスイッチが高コストなのに対し、ゴルーチンにおけるコンテキストスイッチは約2KBと軽量なことです。
これが、ゴルーチンが軽量なスレッドと言われている所以です。
Goランタイムの仕組み(ざっくり)
Goランタイムの仕組みを知ることで、ゴルーチンによる並行処理をさらに理解できます。
スケジューラなど細かい話は、他の方の記事・書籍をご参照ください。
まず、3つの用語を整理します。
- P : 論理CPUコア(processor)
- M : カーネルスレッド(machine)
- G : ゴルーチン(goroutine)
基本的に、1つのPに対して、1つのMが割り当てられています(Mは必要に応じて増減するようです)。
そして、Mの上でGが実行されます。(MとGは多:多)
以下のようなイメージです。
ゴルーチンがいくつか作成されていて、特定のPに紐づくローカルキュー、そしてグローバルキューにゴルーチンが並んでいます。以下は論理CPUコア数の上限(GOMAXPROCS)を2としている場合です。

GOランタイムのスケジューラによって、効率的に複数のGを処理しています。
Mが一度に実行できるのは1つのGですが、うまくコンテキストスイッチが行われることによって、キューとMの間をGが行き来しているイメージです。複数のGを「並行に」処理しているのですね。
コンテキストスイッチが発生するのは、「ブロッキング」または「プリエンプション」の二つが要因としてあります。
ブロッキング
あるGがネットワークI/O処理(APIのリクエスト等)に直面したとしましょう。
その際Gはブロッキングするので、Mから外れます(コンテキストスイッチ・オフ)。
そして、他の実行可能なGをMに新たに割り当て、実行するのです(コンテキストスイッチ・オン)。
I/O待ちのGは、実行可能になればまたMの上で実行されます。

Gがブロッキングした時も、ゴルーチンのコンテキストスイッチによってGoランタイムは高い並行性を持ち、リソースを効率的に使っていることがわかります。
プリエンプション
プリエンプションとは、長時間 CPU を占有している(=長時間M上で実行されている)Gを一時中断し、他の実行可能なGに取り替えることです。強制的にコンテキストスイッチを実行する仕組みとも言えます。
これにより、複数のゴルーチンが公平に実行されシステム全体の実行時間を短縮させることができます。

これは、ローカルキューとMでGを取っ替え引っ替えしているイメージで良いと思います。
Goランタイムをレストランの例と関連付ける
またまた先の例を振り返ってみましょう。
Pは店員であり、Mは、店員が行う仕事とします。
業務フローの4つの「ステップ」はGに置き換えられそうですね。
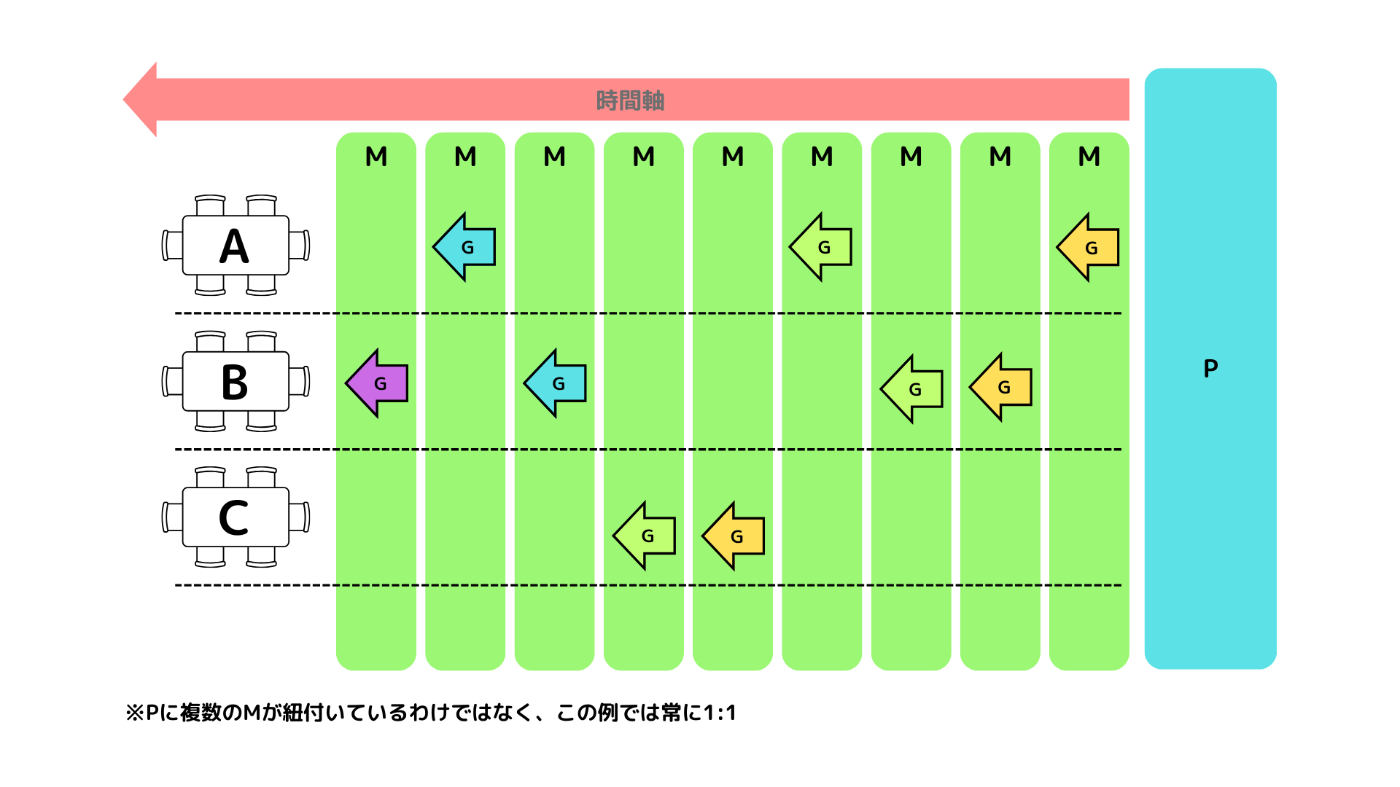
また、「ネットワーク通信I/O等でブロックしている間」というのは、レストランの例においては「客からの注文を待っている時間」や「片付け待ち(食事中)の時間」と置き換えられます。
ゴルーチンの実行はいつ並行でいつ並列なのか
並行・並列処理について整理し、ゴルーチンについても理解できたところで、本記事の本題とも言える話に入っていきましょう。
ゴルーチンは、これまでに述べたとおり、低コストで並行に扱える処理の単位(≒ 軽量なスレッド)です。
あくまで「並行に扱える」処理単位なのであって、必ずしも実装したコードが並行に動いているとは限りません。意図せず、並列処理となっている可能性があります。
では、ゴルーチンはいつ並行なのか、並列なのか。
結論から述べると、ゴルーチンのコンテキストスイッチが発生するかしないかを意識すればいいと考えています。
2種類の処理
ゴルーチンが行う処理は、以下の2種類があります。
- I/O Bound
- CPU Bound
I/O Bound
I/O の遅延がボトルネックになる処理のことを指します。
以下のような処理を指します。
- ネットワーク通信
- ファイル読み書き
- DB読み書き
I/Oの場合に遅延が起こるのは、OSカーネルがその処理を行うからです。
CPU Bound
CPUの計算能力がボトルネックになる処理のことを指します。
以下のような処理を指します。
- 計算処理
- 暗号化・ハッシュ計算
I/O Boundの時は並行ゴルーチン
I/O Boundな処理をゴルーチンに行わせる場合、そのゴルーチンは並行処理されます。
Goランタイムのスケジューラ(ゴルーチンを「いい感じ」に管理してくれる役目を持つ)は、I/O待ちでゴルーチンがブロッキングしたことを認識し、ゴルーチンのコンテキストスイッチのオン・オフを行います。
このゴルーチンのコンテキストスイッチオン・オフ(つまりゴルーチンの切り替え)こそ、「並行処理」です。
ソースコードから、その挙動を確認してみてみましょう。
ゴルーチンをブロックし、コンテキストスイッチを行う実装は、以下のgopark()関数であると考えられます。
// 現在の Goroutine を待機状態にし、システムスタック上で unlockf を呼び出す。
//
// unlockf が false を返した場合、Goroutine は再開される。
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceReason traceBlockReason, traceskip int) {
// 省略
// ここでゴルーチンのコンテキストスイッチが発生する
mcall(park_m)
}
park_m()にはその流れが見て取れます。(一部抜粋)
func park_m(gp *g) {
// 実行中のGに紐づくMを取得
mp := getg().m
// Gの状態を実行中から待機に更新
casgstatus(gp, _Grunning, _Gwaiting)
// MからブロックされたGを切り離す
dropg()
// スケジューリングを行う:実行可能なgoroutineを見つけて実行する
schedule()
}
このgopark()は、以下のように呼び出されています。
チャネル送受信
受信
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// 省略
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceBlockChanRecv, 2)
}
送信
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 省略
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceBlockChanSend, 2)
}
ネットワーク通信
func netpollblock(pd *pollDesc, mode int32, waitio bool) bool {
// 省略
if waitio || netpollcheckerr(pd, mode) == pollNoError {
gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceBlockNet, 5)
}
}
スリープ
time.Sleep()ですね。
func timeSleep(ns int64) {
// 省略
gopark(resetForSleep, nil, waitReasonSleep, traceBlockSleep, 1)
}
ゴルーチンのコンテキストスイッチが行われている実装をソースコードから確認することができました。
従って、「I/O Boundな処理の時は並行ゴルーチン」であると言えます。
CPU Boundの時は並列ゴルーチン(の可能性が高い)
CPU Boundな処理をゴルーチンに行わせる場合、そのゴルーチンは並列処理される可能性が高いです。
なぜなら、スケジューラによってゴルーチンのコンテキストスイッチが行われる可能性が低いからです。
そもそも、計算処理などにおいてはゴルーチンをコンテキストスイッチさせる利点が薄いと言えます。コンテキストスイッチはブロッキング等による「待機時間」の発生の際、他のゴルーチンを実行することによって効率的にリソースを使おうというものでした。
計算処理は、その処理負荷の大小はあるにせよ、「待ち」がありません。つまり、ゴルーチンを切り替える必要がないということです。
そのため、CPU Boundな処理をゴルーチンに任せている場合は、そのゴルーチンは並列ゴルーチンである可能性が高いと言えるでしょう。
しかし、「可能性が高い」と少し濁して述べている理由は、プリエンプション・GOMAXPROCSの影響によってはゴルーチンが並列に扱われないからです。
プリエンプションの影響
プリエンプションとは、約10msほど処理に時間がかかっているゴルーチンを強制的に中断して、他のゴルーチンに席を譲る(つまりGを中断し、Mから外す)仕組みのことでした。
つまり、計算処理等でも、長時間かかってしまう処理を任されたゴルーチンはプリエンプトされ、他のゴルーチンに実行権を譲ります。
この場合、ゴルーチンは並行に扱われていることになります。
GOMAXPROCS()の影響
また、GOMAXPROCSの設定によってはゴルーチンが「並列」に動作しません。
GOMAXPROCSとは、Pの数の上限を設定するものでした。
これが1に設定、つまりPが1つまでとなった場合、Mは基本1つになります。この時、ゴルーチンは逐次処理となるでしょう。また、そこでプリエンプトが起きた場合は、ゴルーチンが並行に処理されるでしょう。
GOMAXPROCS()とベンチマークから考える
例を交えて、考えてみます。
2つの関数を用意しました。この2つの関数を、ゴルーチンとしてそれぞれ5つずつ起動するプログラムを実行するとします。
2つ(SleepG()、FibG())は並行になるか、並列になるのかを予想してみてください。
// スリープ処理
func SleepG(id int, duration time.Duration, wg *sync.WaitGroup) {
defer wg.Done()
time.Sleep(duration)
}
// 重い計算(フィボナッチ計算)
func FibG(id int, n int, wg *sync.WaitGroup) int {
defer wg.Done()
// フィボナッチ数を計算
return fib(n)
}
func fib(n int) int {
// 再帰的にフィボナッチ数を計算 (計算負荷を増加)
if n <= 1 {
return n
}
return fib(n-1) + fib(n-2)
}
GOMAXPROCS()を変え、スレッド数(厳密にはPの数)を増やしながらベンチマークをとってみましょう。
ベンチマークのコード
// SleepG のベンチマーク
func BenchmarkSleepG(b *testing.B) {
for _, procs := range []int{1, 2, 4, 6, 8} {
b.Run(fmt.Sprintf("GOMAXPROCS(%d)", procs), func(b *testing.B) {
runtime.GOMAXPROCS(procs)
var wg sync.WaitGroup
for i := 0; i < b.N; i++ {
wg.Add(1)
go SleepG(i, 1*time.Second, &wg)
}
wg.Wait()
})
}
}
// HeavyCalcG のベンチマーク
func BenchmarkFibG(b *testing.B) {
for _, procs := range []int{1, 2, 4, 6, 8} {
b.Run(fmt.Sprintf("GOMAXPROCS(%d)", procs), func(b *testing.B) {
defer runtime.GOMAXPROCS(runtime.GOMAXPROCS(0)) // 終了時に元の値に戻す
runtime.GOMAXPROCS(procs)
var wg sync.WaitGroup
for i := 0; i < b.N; i++ {
wg.Add(1)
go FibG(i, 35, &wg)
}
wg.Wait()
})
}
}
これを実行すると、以下のような結果になりました。
BenchmarkSleepG/GOMAXPROCS(1)-8 1 1001162000 ns/op
BenchmarkSleepG/GOMAXPROCS(2)-8 1 1001220334 ns/op
BenchmarkSleepG/GOMAXPROCS(4)-8 1 1001172667 ns/op
BenchmarkSleepG/GOMAXPROCS(6)-8 1 1001114667 ns/op
BenchmarkSleepG/GOMAXPROCS(8)-8 1 1001073292 ns/op
BenchmarkFibG/GOMAXPROCS(1)-8 38 31013143 ns/op
BenchmarkFibG/GOMAXPROCS(2)-8 75 15807017 ns/op
BenchmarkFibG/GOMAXPROCS(4)-8 138 8314421 ns/op
BenchmarkFibG/GOMAXPROCS(6)-8 151 6793217 ns/op
BenchmarkFibG/GOMAXPROCS(8)-8 178 6278915 ns/op
SleepG()に関して、GOMAXPROCSの影響をほぼ全く受けていないことが見受けられます。
これは、SleepG()のゴルーチン5つが「並行ゴルーチン」だったからです。
SleepG()は、スリープ処理が行われている、擬似的なI/O Bound処理です。それぞれ5つのゴルーチンは、time.Sleep()のタイミングでブロッキング(▶︎ Mから外れる)するため、いくらCPUが増えても(≒ P、そしてそれに紐づくMが増えても)、処理が早く終了するわけではありません。コンテキストスイッチが行われ、1つのMでも効率的にGを実行できます。
一方、FibG()を見ると、GOMAXPROCSが増えれば増えるほどパフォーマンスが向上していることがわかります。
これは、FibG()のゴルーチン5つが「並列ゴルーチン」だったからです。
FibG()は、フィナボッチ計算を行っています。これは、CPUを消費するCPU Bound処理です。
並列化すればするほど(限度があることに注意が必要です)、CPU Boundな処理はパフォーマンス向上が見込めそうです。
おわりに
今回は、並列処理と並行処理という、混同しがちな二つを整理した後、Goにおけるゴルーチンについて取り上げてみました。
学んでいると、「並行処理」というワードばかりが耳に残ってしまいますが、ゴルーチンは「並列」にも「並行」にもなり得ます。
そして、いつゴルーチンが並行になり、また、並列になるのかを意識しておくと、チャネルとミューテックスの使い分け等、正しい実装の仕方にも繋がります[1]。
間違いなどありましたらご指摘いただけると助かります。
Goランタイム難しい。
参考
Discussion