【LangChain】AVを好みに合わせて採点する(一応18+)
ニュース記事をユーザー好みに合わせてAIが点数をつけるアプリケーションを開発しており、そのための実証用です。
題材はほのぼのニュースでも音楽でも良かったのですが、特徴を抽出して「ユーザーの好み」に合わせて採点するには多少使いづらかったです。
いろいろ考えてみた結果、嗜好性が多種なAVを使うことにしました。
コードはこちらに保存しています
課題(LLMの使いどころ)
好きなセクシー女優が出演している作品でも、舞台とかシチュエーションが好みでないことがあります。
なので、自分の好みの作品だけを抽出してくれたらいいのにと思うことがよくあります。
例えば人気不動の1位である「松本いちか」の作品で見てみましょう。
- スレンダー美女が愛人を奪い合って逆3P!中出しでザーメンを搾り取る
- 義母の裸を見た連れ子がフル勃起!貧乳でスレンダーな若妻が生ハメして中出しセックス
- 痴女JKがイジメっ子を主観JOIでお仕置き!淫語を囁きながら手コキして中出しセックス
背徳感が好きな人は2番目の作品にビビッと来るでしょう。
逆に乱行モノが嫌いな人は1番目の作品は表示しないでくれと思うかもしれません
タグで採点する
タグに含まれる単語とユーザーの好みを機械的に掛け合わせて、ユーザー関心度を算出します。
この方法だとLLMを使うまでもありませんので、簡単に実装できます。
注意点としてはタグに使われるワードの揺らぎを抑える必要があります
(例えば、JKと女子高生は同義というように)
また、同じ単語でも文脈によって意味が異なる場合があり、例えば「乳」という単語が娯楽的な記事で用いられている場合もあれば、乳がんのような医学的な記事で使われている場合もあるでしょうから、単語が含まれているからといってユーザーの好みだと判断するのはいささか危険です。
文章で採点する
この方法はLLMを使います。
意味的な尺度も測定できるので、前述のタグ採点と比べてより実態に即した採点が期待できます。
どういうことかと言いますと、前述のタグ採点では「人妻」と「NTR」のようなAV的に意味的に近いが別の単語の場合、それらを別タグにしていると二重で加算され高得点を獲得してしまう可能性があります
(人妻モノが好きな人はたいてい寝取られものも好きそうなので、実用上は問題ないかもしれませんが)
また、単語は上位概念と下位概念がありますので、タグ採点の場合は単語が違えば違う概念として扱われてしまいます。
例えば乱行モノが嫌いなユーザーに合わせて採点する場合、上記1つ目の例では「3P」というタグがつけられても「乱行」というタグがついていない場合は減点することができません。
一方でLLMでは「3P」は「乱行」の下位概念として処理できますので、おそらく乱行を減点するようにLLMに命じた場合は「3P」も減点してくれるはずです。
背徳感についても同様で、NTR(寝取られ)は背徳感の下位概念だと思います。
といっても、じゃあ痴女は背徳なのか、近親相姦は背徳なのかの判断については、openAIやclaudeがどのように学習しているかにもよりますがね。
データ元
FANZAやXvideosを参考にしても良いのですが、こちらの方がよくまとまっています。
(私の経験上、安心して使えるサイトです。あと言うまでもなく成人向けなのでご了承ください)
今回のような実験検証のためでしたら、特徴的なサンプルを10個くらい手作業で取り出してもさほど手間ではないと思います。
上記の例で示した松本いちかのように、ある作品では女子高生役をしていて別の作品では人妻役をしているというように、多彩な作品に出ているほうが特徴が出やすく分析しやすいです。
念のため繰り返しますが、今回はあくまで実験検証用です。
あなたの好みではないので、普段は興味なくスルーするような作品でもサンプルとして入れましょう。
(かといって60代熟女とかスカトロみたいな気持ち悪いのを入れるとモチベーションが下がるので、常識の範囲内にしておきましょう)
無計画に着手してしまうと自分の好みばかりを集めてしまいがちなので、ペルソナを定めておくとやりやすいです。
例えば以下のようにユーザーと好きそうなジャンルを決めました。
- ロリコンサド趣味な人
{女子高生:2, 素人:2, 中出し:1, 熟女:-2} - 熟女好きドMな人
{人妻:2,三十路:1,NTR:1, 手コキ:1, 巨乳:2, S:-2} - 性癖拗らせた人
{レズ:2,アナル:1,フェチ:1}
今回抽出した作品
セクシー女優については、出演作品のジャンルの広さで選ぶと良いでしょう。
迷うようなら以下の女優さんがおすすめです。
- 松本いちか
- 三上悠亜
- 七沢みあ
※ この前七沢みあちゃんをフォローしました!
検証
アプリケーションの作成
私の以前の記事でlangserveを使った作成方法を紹介していますので、こちらを参考にしてください
サンプルコード
動作確認レベルなので、最低限の実装だけです
from fastapi import FastAPI
from fastapi.responses import RedirectResponse
from langserve import add_routes
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
app = FastAPI()
@app.get("/")
async def redirect_root_to_docs():
return RedirectResponse("/docs")
# Edit this to add the chain you want to add
template = """
ユーザーの嗜好に合わせて、次に渡す作品に採点してください。
# 採点方法
作品の内容を説明する文章を渡しますので、ユーザーの嗜好に合わせて、その作品を評価してください。
ユーザーの嗜好については以下のようなオブジェクト形式で渡します。
例:'素人:2,人妻:1,乱行:-2'
-2,-1,0,1,2の5段階で、プラスは好き、マイナスは嫌いを示しています。
単純に単語の有無で判断するのではなく、意味的な距離や上位・下位概念も加味してください
# データ
紹介文章:{description}
ユーザーの嗜好:{preference}
# 出力
-2から2の5段階評価です。
-2は嫌い、0は普通、2は好きです。
数値だけを出力してください
"""
prompt = ChatPromptTemplate.from_template(template=template)
model =ChatOpenAI(model="gpt-4o-mini",openai_api_key="*******")
add_routes(
app,
prompt | model,
path = '/question'
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
http://127.0.0.1:8000/docs#/で開けてみると、以下のようなswagger画面が表示されるはずです。
実証
/question/invokeを以下のようにデータを入れて検証してみましょう。
{
"input": {
"description": "スレンダー美女が愛人を奪い合って逆3P!中出しでザーメンを搾り取る",
"preference": "{素人:2,美女:1,乱行:-2}"
},
"config": {},
"kwargs": {}
}
以下のような結果が返ってくるはずです。
(output.contentの"-1"がAIの答えです)
{
"output": {
"content": "-1",
"additional_kwargs": {},
"response_metadata": {
"token_usage": {
"completion_tokens": 2,
"prompt_tokens": 260,
"total_tokens": 262
},
"model_name": "gpt-4o-mini",
"system_fingerprint": "fp_48196bc67a",
"finish_reason": "stop",
"logprobs": null
},
-1という評価結果は、乱行:-2を反映させられたものと考えることができます。
試しに{乱行:-2}をなくしてみると、評価は"2"になりました
冒頭で述べたように、"愛人を奪い合って逆3P"という文には"乱行"という単語は入っていませんが、gpt-4o-miniがこのタイトルは乱行モノだと判断したのでしょう。
DBからデータを引っ張ってくる
実際のアプリケーションでは、文章をクエリパラメーターとして投げるわけではなく、DBに保存した記事一覧から対象のデータを引っ張ってきて、AIがユーザーの嗜好に応じて採点するといったことを考えています。
とりあえずsqlite3を使って、データを読み取るようにします。
サンプルコード
import sqlite3
from fastapi import FastAPI
from fastapi.responses import RedirectResponse
from langserve import add_routes
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
app = FastAPI()
@app.get("/")
async def redirect_root_to_docs():
return RedirectResponse("/docs")
# chainを定義
template = """
ユーザーの嗜好に合わせて、次に渡す作品に採点してください。
# 採点方法
作品の内容を説明する文章を渡しますので、ユーザーの嗜好に合わせて、その作品を評価してください。
ユーザーの嗜好については以下のようなオブジェクト形式で渡します。
例:'素人:2,人妻:1,乱行:-2'
-2,-1,0,1,2の5段階で、プラスは好き、マイナスは嫌いを示しています。
単純に単語の有無で判断するのではなく、意味的な距離や上位・下位概念も加味してください
# データ
紹介文章:{description}
ユーザーの嗜好:{preference}
# 出力
-2から2の5段階評価です。
-2は嫌い、0は普通、2は好きです。
数値だけを出力してください
"""
prompt = ChatPromptTemplate.from_template(template=template)
model =ChatOpenAI(model="gpt-4o-mini",openai_api_key="***********")
chain = prompt | model
# ユーザーの嗜好を定義
preference = {'素人':2,'美女':1,'乱行':-2}
# databaseを作成
@app.get("/setup_database")
async def setup_database():
with sqlite3.connect('sample.db') as conn:
c = conn.cursor()
c.execute(f'''
CREATE TABLE IF NOT EXISTS movies (id INTEGER PRIMARY KEY AUTOINCREMENT,title STRING, description TEXT, ai_score TEXT)
''')
# 指定したidのデータを取得し、AIが評価をつける
@app.post("/set_score")
async def set_score(id:str):
with sqlite3.connect('sample.db') as conn:
c = conn.cursor()
c.execute('SELECT * FROM movies WHERE id = ?',(id,))
result = c.fetchone()
id, title, description,ai_score = result
res = chain.invoke(input={'preference':preference ,'description':title})
ai_score = res.content
c.execute('UPDATE movies SET ai_score = ? WHERE id = ?', (ai_score, id))
# add_routes(
# app,
# prompt | model,
# path = '/question'
# )
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
解説
DBを作成
以下の部分はsqlite3のDBを作成するコードです。
# databaseを作成
@app.get("/setup_database")
async def setup_database():
with sqlite3.connect('sample.db') as conn:
c = conn.cursor()
c.execute(f'''
CREATE TABLE IF NOT EXISTS movies (id INTEGER PRIMARY KEY AUTOINCREMENT,title STRING, description TEXT, ai_score TEXT)
''')
swaggerでExecuteボタンを押せば、この関数が実行されてDBが作成されます

データの編集
ちなみにDBはDB Browser for SQLiteというツールを使うと、デスクトップ上でデータの閲覧や編集ができて便利です。
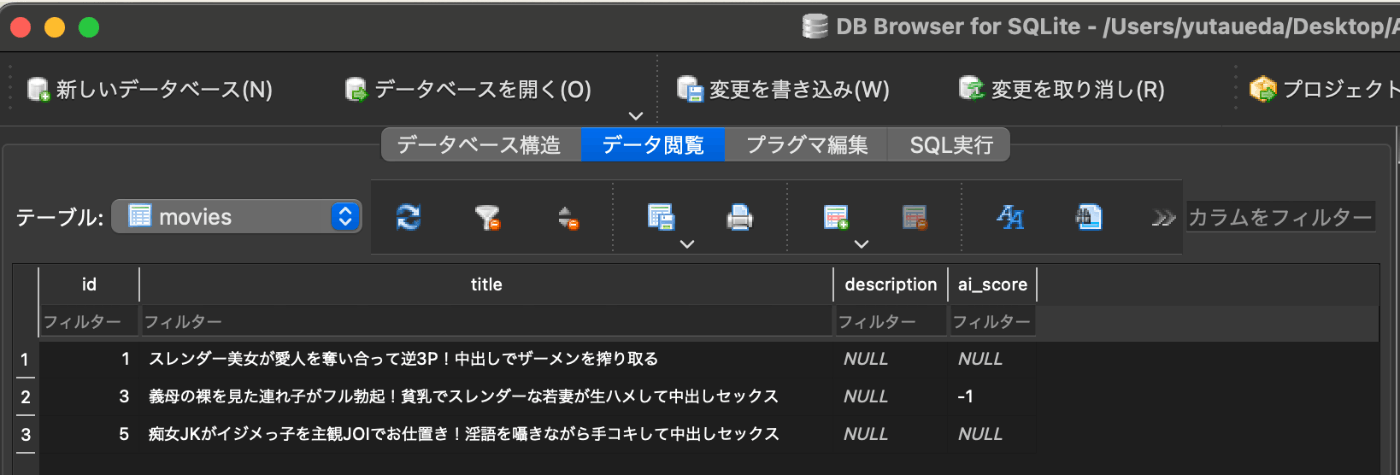
上記のように手作業でデータを入れてやりました。
chainの作成
これまでlangchainを触ったことのある人なら特に解説は不要かと思います
# chainを定義
template = """
ユーザーの嗜好に合わせて、次に渡す作品に採点してください。
# 採点方法
作品の内容を説明する文章を渡しますので、ユーザーの嗜好に合わせて、その作品を評価してください。
ユーザーの嗜好については以下のようなオブジェクト形式で渡します。
例:'素人:2,人妻:1,乱行:-2'
-2,-1,0,1,2の5段階で、プラスは好き、マイナスは嫌いを示しています。
単純に単語の有無で判断するのではなく、意味的な距離や上位・下位概念も加味してください
# データ
紹介文章:{description}
ユーザーの嗜好:{preference}
# 出力
-2から2の5段階評価です。
-2は嫌い、0は普通、2は好きです。
数値だけを出力してください
"""
prompt = ChatPromptTemplate.from_template(template=template)
model =ChatOpenAI(model="gpt-4o-mini",openai_api_key="****")
chain = prompt | model
AIが採点
postリクエストでidを送ると、DBから該当するレコードを取り出します
レコードのtitleあるいはdescriptionをもとに、先ほどのchainを利用してAIが評価をつけます
点数はDBのai_scoreというフィールドに保存されます。
@app.post("/score_movie")
async def set_score_movie(id:str):
with sqlite3.connect('sample.db') as conn:
c = conn.cursor()
c.execute('SELECT * FROM movies WHERE id = ?',(id,))
result = c.fetchone()
id, title, description,ai_score = result
res = chain.invoke(input={'preference':preference ,'description':title})
ai_score = res.content
c.execute('UPDATE movies SET ai_score = ? WHERE id = ?', (ai_score, id))
余談
chatGPTに性的な言葉を投げると、利用規約違反の警告が出ます。

今回の検証では、openAIのAPIに直接投げたのですが、目立った警告は出ませんでした。
性的な言葉で何か分析が必要な場合は、今回のような方法が使えるのかもしれません
Discussion