FluentdとAWS Athenaでログ集約してみた
背景
私が2社目で働いていた会社ではRailsを使ったWebアプリケーションサービスを展開しており、複数のEC2インスタンスに対してRailsを導入しております。
複数のEC2インスタンス上で動かしているRailsのログは個々のサーバー上に生成される仕組みになっており、ログを参照する場合は該当のサーバーへログインして直接ログを見るという方法をとっていました。

しかし、段々とサービスの規模が大きくなり、一々踏み台サーバー経由でSSHログインして直接参照するのが大変な点、複数のサーバー上で生成されるログの比較も困難な点であることから、ログ検索の改善を目的としたログ集約のインフラを構築することにしました。
やったこと
- 各種EC2にFluentdを導入し、ログをS3に転送する
- S3に格納されたログをGlueを使ってテーブル定義づけする
- Athenaでクエリを発行して、複数ログを検索して一覧化できるようにする
- CloudWatch LogsのログはKinesisを用いてS3へ転送
S3に格納されたログはそのままではテーブル定義がされてないので、AWS GlueでS3にあるログをクロールしてテーブル定義をデータカタログに作成しました。
最終的には、AWS Athenaを使ってAthenaのコンソール画面からログを検索できるようにすることが目標です。
対象ログ
- Apacheログ
- Railsログ
- Postfixログ
- SlowQueryログ
- (CloudTrailログ)
今回集約対象となるログは以上の通りです。ApacheとRailsとPostfixのログはEC2インスタンス上に生成されているので、これらのログをFluentdを使って、S3へ転送いたします。
SlowQueryログは前述の通り、CloudWatch Logsに収集されていますのでKinesisを使って、S3へ配信できるようにします。またAWSの監査ログであるCloudTrailもログ集約の対象ですが、CloudTrailはコンソールの設定からAthenaテーブルを作成でき、特に説明する事もないので割愛しています。
ログ集約基盤イメージ図
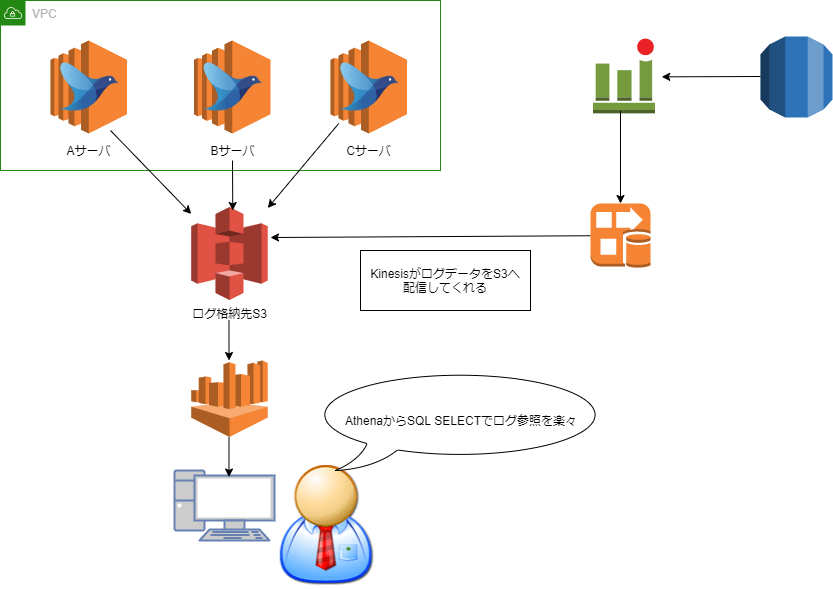
ログ集約の基盤構成イメージは上記の通りとなっております。各種サーバーにFluentdを導入してS3へ格納後、S3からAthenaでログ検索ができるようにGlueを使ってテーブル定義します。
SlowQueryログに関しましてはすでにCloudWatch Logsに収集されており、SlowQueryログがCloudWatch Logsに格納されたタイミングでKinesisで設定したLambdaが動き、S3へ配信するように設定しています。
それでは、具体的な実装手順について記載いたします。
基盤構築手順
Fluentdの導入
各種サーバーにFluentdを入れます。Fluetndのインストール手順などは公式リファレンス参照で割愛しますが、インストール後の初期設定手順は公式リファレンスにはない情報なので記しておきます。
インストールが完了しましたら、ログをS3に送るようにするのですが実行ユーザーであるtd-agentでは権限エラーでログが送れないので、実行ユーザーをrootユーザーに変更します。(Fluentdのバージョンによって設定先が異なります)
実行ユーザー権限
Ver3
-- TD_AGENT_USER=td-agent #削除
-- TD_AGENT_GROUP=td-agent #削除
++ TD_AGENT_USER=root #追加
++ TD_AGENT_GROUP=root #追加
Ver4
-- User=td-agent #削除
-- Group=td-agent #削除
++ User=root #追加
++ Group=root #追加
次にプラグインfluent-plugin-multi-format-parserを導入します。
こちらのプラグインですが、1つのログファイルの中に複数のフォーマットが混在しているとき、便利なプラグインです。formatでmulti_formatと指定して配下にpatternでフォーマットごとにパターンを記載すればログをきれいに整形してくれます。
プラグイン導入
/opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-multi-format-parser
$ /opt/td-agent/embedded/bin/fluent-gem list
*** LOCAL GEMS ***
中略
fluent-plugin-multi-format-parser (1.0.0)
中略
ログ集約設定
設定ファイル/etc/td-agent/td-agent.conf内に対象のログを集約し、S3へ送るように設定します。
Webサーバー
#Rails Log
<source>
@type tail
@id input_rails_tail
<parse>
@type multi_format
# fluent-plugin-multi-format-parserで複数のフォーマットを拾えるようにしている
<pattern>
format multiline
format_firstline /^.,/
format1 /^(?<log_initial>.*), \[(?<date>\d{1,4}-\d{1,2}-\d{1,2}T\d{1,2}:\d{1,2}:\d{1,2}.\d{1,6}) (?<process_id>[^ ]*)\] *(?<log_level>[^ ]*) -- : (?<message>[^\']*[^\]]*)/
keep_time_key true
</pattern>
<pattern>
format multiline
format_firstline /^.,/
format1 /^(?<log_initial>.*), \[(?<date>\d{1,4}-\d{1,2}-\d{1,2}T\d{1,2}:\d{1,2}:\d{1,2}.\d{1,6}) (?<process_id>[^ ]*)\] *(?<log_level>[^ ]*) -- : (?<message>.*)/
keep_time_key true
</pattern>
<pattern>
format none
</pattern>
</parse>
path Railsのログが配置しているパスを指定する
tag td.rails.production.log
pos_file /var/log/td-agent/rails_log.pos
</source>
# Apache access_logs
<source>
@type tail
@id input_tail
<parse>
@type multi_format
<pattern>
format regexp
expression /^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^ ]*) +\S*)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$/
time_format %d/%b/%Y:%H:%M:%S %z
keep_time_key true
</pattern>
<pattern>
format none
</pattern>
</parse>
path /var/log/httpd/access_log
tag td.apache.access
pos_file /var/log/td-agent/apache_access_log.pos
</source>
#Apache error_logs
<source>
@type tail
@id input_error_tail
<parse>
@type multi_format
<pattern>
format regexp
expression /^\[[^ ]* (?<time>[^\]]*)\] \[(?<level>[^\]]*)\] (?<message>.*)$/
keep_time_key true
</pattern>
<pattern>
format regexp
expression /^\[ (?<log_initial>.*) (?<date>\d{1,4}-\d{1,2}-\d{1,2} \d{1,2}:\d{1,2}:\d{1,2}.\d{1,4}) (?<status>\d{1,3}/T[a-z,A-Z,0-9]) (?<path>[^ ]*) ]: (?<message>.*)/
keep_time_key true
</pattern>
<pattern>
format none
</pattern>
</parse>
path /var/log/httpd/error_log
tag td.apache.error
pos_file /var/log/td-agent/apache_error_log.pos
</source>
#Get hostname record and add raw data
<filter td.apache.access**>
@type record_transformer
#ログ整形されていない生データのログも追記する
<record>
raw_data ${record["host"]} ${record["user"]} ${record["time"]} ${record["method"]} ${record["path"]} ${record["code"]} ${record["size"]} ${record["referer"]} ${record["agent"]}
hostname "#{Socket.gethostname}"
sourcelog ${tag_parts[2]}
</record>
</filter>
<filter td.apache.error**>
@type record_transformer
#ログ整形されていない生データのログも追記する
<record>
raw_data ${record["time"]} ${record["level"]} ${record["message"]}
hostname "#{Socket.gethostname}"
sourcelog ${tag_parts[2]}
</record>
</filter>
<filter td.rails.**>
@type record_transformer
#ログ整形されていない生データのログも追記する
<record>
raw_data ${record["log_initial"]} ${record["date"]} ${record["process_id"]} ${record["log_level"]} ${record["message"]}
hostname "#{Socket.gethostname}"
</record>
</filter>
#Output to S3
<match td.**>
@type s3
s3_bucket 集約先のS3バケット名
s3_region S3のあるリージョン名
s3_object_key_format "%{path}year=%Y/month=%m/day=%d/#{Socket.gethostname}_%{hms_slice}.%{file_extension}"
time_slice_format %Y%m%d
path logaggregator/${tag[1]}/tag=${tag[2]}/
check_object false
<format>
@type json
</format>
<inject>
time_key fluentd_time
time_type unixtime
</inject>
<buffer tag,time>
@type file
path /tmp/fluent/s3/error
time_slice_wait 10m
timekey 10m
timekey_wait 0
chunk_limit_size 512m
</buffer>
</match>
Webサーバーで上記のようにRailsログとApacheログを集約し、S3へ送信するように設定しています。(弊社のサイトはSSL通信対応なので実際にはssl_access_logも設定していますが、大体同じような設定のため省略しています)
ここでのポイントはFluentdにはApacheのログを集約してくれる専用のプラグイン、apache2とapache_errorをあえて使わず、regexpで自分の手で正規表現を設定して集約しているところです。
これには理由がありまして、途中のfilterディレクティブで集約したログに追加でサーバーホストネームとログ整形されていない生の状態のログも一緒に参照できるようにしたいという要望をかなえるためにログの並び方をカスタマイズする必要があり、自由に調整できるregexpを使いました。
(詳細は後述)
メールサーバーも同じように設定します。
メールサーバー
#postfix_log
<source>
@type tail
@id input_postfix_tail
<parse>
@type multi_format
<pattern>
format regexp
expression /^(?<time>[^ ]* [^ ]* [^ ]*) (?<host>[^ ]+) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[0-9]+)\])?[^\:]*\: (?<key>[^:]+): ?((to|from)=(<(?<address>[^>]+)>)?)?,( ?(orig_to=<(?<orig_to>[^>]+)>),)? ?(relay=(?<relay>[^ ]+)), ?(delay=(?<delay>[^ ]+)), ?(delays=(?<delays>[^ ]+)), ?(dsn=(?<dsn>[^ ]+)), ?(status=(?<status>[^,]+))/
time_format %b %d %H:%M:%S
keep_time_key true
</pattern>
<pattern>
format regexp
expression /^(?<time>[^ ]* [^ ]* [^ ]*) (?<host>[^ ]+) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[0-9]+)\])?[^\:]*\: (?<key>[^:]+): ?((to|from)=(<(?<address>[^>]+)>)?)?,( ?(orig_to=<(?<orig_to>[^>]+)>),)? ?(relay=(?<relay>[^ ]+)), ?(delay=(?<delay>[^ ]+)), ?(delays=(?<delays>[^ ]+)), ?(dsn=(?<dsn>[^ ]+)), ?(status=(?<status>[^,]+))/
time_format %b %d %H:%M:%S
keep_time_key true
</pattern>
<pattern>
format regexp
expression /^(?<time>[^ ]* [^ ]* [^ ]*) (?<host>[^ ]*) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[0-9]+)\])?[^\:]*\: *(?<message>.*)$/
time_format %b %d %H:%M:%S
keep_time_key true
</pattern>
<pattern>
format regexp
expression /^(?<time>[^ ]* [^ ]* [^ ]*) (?<host>[^ ]*) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[0-9]+)\])?[^\:]*\: *(?<message>.*)$/
time_format %b %d %H:%M:%S
keep_time_key true
</pattern>
<pattern>
format none
</pattern>
</parse>
path /var/log/maillog
tag td.postfix
pos_file /var/log/td-agent/postfix.pos
</source>
#Get hostname record and add raw data
<filter td.postfix>
@type record_transformer
<record>
raw_data ${record["time"]} ${record["host"]} ${record["ident"]} ${record["pid"]} ${record["key"]} ${record["address"]} ${record["relay"]} ${record["delay"]} ${record["delays"]} ${record["dsn"]} ${record["status"]} ${record["message"]}
hostname "#{Socket.gethostname}"
</record>
</filter>
# Output to S3
<match td.**>
@type s3
s3_bucket 集約先のS3バケット名
s3_region S3のあるリージョン名
s3_object_key_format "%{path}year=%Y/month=%m/day=%d/#{Socket.gethostname}_%{hms_slice}.%{file_extension}"
time_slice_format %Y%m%d
path logaggregator/${tag[1]}/
check_object false
<format>
@type json
</format>
<inject>
time_key fluentd_time
time_type unixtime
</inject>
<buffer tag,time>
@type file
path /tmp/fluent/s3/error
time_slice_wait 10m
timekey 10m
timekey_wait 0
chunk_limit_size 256m
</buffer>
</match>
postfix.logのログもファイル内でいくつかのログフォーマットが混在しているためfluent-plugin-multi-format-parserを使って複数の分岐で拾えるようにしています。
またメールサーバーも同様に生データのログがほしいという要望がありましたので、filterディレクティブに生データのログを追加するように設定しています。
これでFluentdを再起動すれば、ログがS3へ送られます。
AWS Glueによるクローリング
S3に格納されたログをAWS Athenaで分析するようにするためにS3内のデータをテーブルとして定義する必要があります。Glueはクローラ機能を使ってデータのテーブル定義ができ、Athenaでのログ分析を可能にしてくれるETLサービス(抽出、変換、ロード)です。
Glueのコンソール画面から新規にクローラの追加を選択します。
AWS Glueのクロールの課金体系は、1DPU(Data Processing Unit)あたり0.44$/時となっていますが、1回のクロールで2DPU動くので実質0.88$/時となっています。さらに10分未満の時間は10分間の使用とみなされるので、最低利用料金は約0.15$となります。
クローラの追加が完了し、手動実行すればS3に格納されているログデータを分析しAthenaにテーブルが作成されます。

いくつかのカラムにパーティション化と書かれていますが、S3のバケット名を以下のようにカラム名=/とすれば、パーティション化されたカラムを定義することが可能となります。(HIVE形式といわれているそうです)

パーティション化することのメリットですが、検索範囲を絞ることができ、検索時間と検索量が抑えられるというメリットがあります。
パーティション有

パーティション無

スキャンデータも10倍違うことがわかります。これでFluentdでのログ集約は完成です。
SlowQueryログの転送
次にSlowQueryログの集約構築です。
まずはCloudWatch LogsからS3へ配信されるストリームを作成します。
基本的に転送するS3を指定し、ほかはデフォルトの設定で問題ありませんが、途中Lambdaでデータ変換の有無が聞かれるので、ここでAthenaで読み込みしやすいようにCloudWatch Logsのデータ形式をjson形式に変換します。
import base64
import gzip
import io
import json
def lambda_handler(event, context):
records = [process_record(r) for r in event['records']]
return {'records': records }
def process_record(record):
record_id = record['recordId']
data = base64.b64decode(record['data'])
iodata = io.BytesIO(data)
with gzip.GzipFile(fileobj=iodata, mode='r') as f:
data = json.loads(f.read())
processed_data = process_data(data) + '\n'
return {
'data': base64.b64encode(processed_data.encode('utf-8')).decode('utf-8'),
'result': 'Ok',
'recordId': record_id
}
def process_data(data):
return '\n'.join([format_log_event(json) for json in data['logEvents']])
def format_log_event(j):
return json.dumps({'timestamp': j['timestamp'], 'message': j['message']})
この後Kinesis側の設定はあらかた完了します。CloudWatch Logsにログが来たら、Kinesisで設定したLambda関数が動き、S3へログが配信されるようになります。
運用開始後のフィードバック
基盤構築が完了しましたので、まずは開発環境に導入して実際にログ検索を利用するユーザーに使用したフィードバックを募集しました。
そして以下のような改善要望がありました。
- ApacheログとRailsの日付ログフォーマットが異なるため、比較できるようにしてほしい
- Fluentdはログデータを加工された状態で転送するので生データのログも参照できるようにしたい
- SlowQueryログのクエリタイムでソートできるようにしてほしい
日付ログフォーマットの違い
ApacheとRailsのログ内の日付表記は異なっています。
08/Dec/2020:19:13:01 +0900 #Apacheログ
2020-12-08T23:41:30.980713 #Railsログ
この通り日付のフォーマットが異なるためこの状態では、timeによるソートができず同一時間帯でのログの比較ができない状態です。この問題を解決するためにUNIXTIMEをレコードに追加しました。
Fluentdでは、ログの転送時にログを加工するプラグインが用意されており、その中にはUNIXTIMEを追加するプラグインもあります。
<inject>
time_key fluentd_time
time_type unixtime
</inject>
レコードにUNIXTTIMEを追加することで、ApacheログとRailsログで時間による比較や時刻ソートによる検索が可能となりました。
ログの生データも検索できるようにしたい
前述したとおり、Fluentdはログをパースすることで加工して転送しますが、場合によってはログの生データが必要になるケースがあります。その要望に応えるため、レコードの末尾にraw_dataという値を追加し、中身はregexpで正規表現で集約したログの中身をつなぎあわせて、生データとして表示できるようにしました。
<filter td.apache.access**>
@type record_transformer
<record>
raw_data ${record["host"]} ${record["user"]} ${record["time"]} ${record["method"]} ${record["path"]} ${record["code"]} ${record["size"]} ${record["referer"]} ${record["agent"]}
</record>
</filter>
クエリタイムでソートできるようにしたい
CloudWatch LogsからKinesis経由でS3へSlowQueryログを格納していますが、S3に格納されたログはFluentdのようにパースされているわけではなく、ログメッセージ全文がメッセージテーブルの中に格納されています。なのでSELECT messages FROM slowquery;でスロークエリログ全文が検索されてしまいます。

これですと例えば○○秒以上のクエリタイムだけを抽出したりソートすることが困難で、クエリタイムだけ別で分けてログ加工できないかという内容です。
残念ながらこちらの解決方法がわからず、最終的にはKinesisでS3へ転送して、Athenaでクエリ検索する方法を諦めて、CloudWatch Logsをローカルのターミナルから検索できるawslogsというOSSを使ってクエリタイムでの検索ソートを行ないました。
$ awslogs get <SlowQueryログ> --start='MM/DD/YYYY' --end=’MM/DD/YYYY’
#実行結果
<SlowQueryログ> <リージョン> # Time: 180606 15:00:02
# User@Host: rdsadmin[rdsadmin] @ localhost [] Id: 18
# Query_time: 0.507831 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 0
SET timestamp=1528297202;
FLUSH SLOW LOGS ;
これでQuery_timeか所をgrepしたりawkでいい感じに抜き出したりすることが可能となります。
なので最終的な構築図はこのようになりました。

所感
FluentdとAthena、その他もろもろを使ってログ集約の基盤を構築しました。
やはり、SlowQueryログ部分だけが上手くいかず利用者サイドにお願いしてもらうような形になりましたので、できればAthenaで検索できればいいのですが、現状私の手では解決方法がわかりませんでした。
もし、この課題に対する解決策についてご存じの方がいましたらコメントにてこっそりと教えてくれると私が喜ぶますので、アドバイスお待ちいたしております。
LT資料
この記事をもとにしたLTを行ないましたので資料を置いておきます。
Discussion