BigQueryUDFの返り値をテーブルみたく扱う

TL;DR
CREATE TEMP FUNCTION github_repos() AS ((
SELECT ARRAY (
SELECT AS STRUCT
*
FROM
`bigquery-public-data.github_repos.languages`
)
));
SELECT
*
FROM
UNNEST(github_repos())
経緯
自分は現在関係者1000人ほどのプロダクトのデータ分析組織に所属しています。
そのプロダクトでは日々新規機能開発やビジネス的な施策も行われており、それに伴うABテストの効果検証や施策に対するKPIのモニタリング環境の作成などが業務の一環となっています。
ここでそれぞれのメンバーが指標を策定し評価軸などを考えている訳ですが、プロダクトが大きければその分ログの数や種類も多くなり,中々ログの抽出条件や使うテーブルの統一ができず、抽出結果の再現性が失われかけているというのが現状です。
以前からこれを解決するためにviewテーブルを用いて統一しようとする動きはあるのですが、施策によって抽出条件が変わる場合も多く、viewではなくテーブルを直接参照して条件を変更するということが多く発生していました。
そこで少なくとも抽出条件を合わせれば再現性が担保されるようにパラメータつきテーブルのように扱えるUDFを作ってみることにしました。
UDFとは
UDFとはuser-defined functionの略で、そのままの意味で自分たちが定義出来る関数です。
例として以下のように一時的にUDFを作ってみました。
-- 引数に1足して返すUDF
CREATE TEMP FUNCTION addOne(x INT64) AS (x + 1);
SELECT
addOne(number) AS result
FROM
(SELECT 1 AS number);
/* 結果
+--------+
| result |
+--------+
| 2 |
+--------+
*/
一般的なプログラミング言語の関数のように引数とその処理を定義することで使うことができます。
しかしこのUDFを使ってテーブルデータを返そうとすると少し工夫することが必要だったため、今回記事として残すことにしました。
例として使用するデータセット

今回は例として一般公開されているGitHubのデータセットを使っていきます。
データセットIDはbigquery-public-data:github_reposで、今回はリポジトリとそのリポジトリの言語のデータが含まれているlanguagesというテーブルを対象にします。
languagesテーブルのスキーマは以下のようになっています。
| フィールド名 | タイプ |
|---|---|
| repo_name | repo_name |
| language | RECORD |
| language.name | STRING |
| language.bytes | INTEGER |
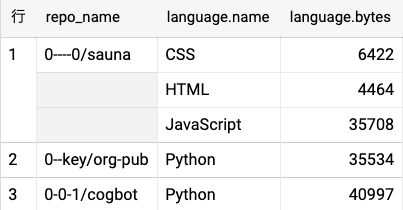
実際に中身を見てみます.。
SELECT
*
FROM
`bigquery-public-data.github_repos.languages`
WHERE -- 表示の都合で短い結果に絞る
CHAR_LENGTH(repo_name) < 20
AND ARRAY_LENGTH(language) < 5
ORDER BY
repo_name
LIMIT
3
結果は以下のようになっており、languageがSTRUCTの配列ということが分かります。
それぞれのカラムはrepo_nameがそのままリポジトリ名、languageのnameとbytesがそのリポジトリで使われている言語とその容量です。
失敗談
まず初めにUDFでレコードをそのまま返すことを考えましたが失敗。
CREATE TEMP FUNCTION sample_repos() AS ((
SELECT * FROM `bigquery-public-data.github_repos.languages`
));
SELECT * FROM sample_repos()
/* 結果:エラー
Scalar subquery cannot have more than one column
unless using SELECT AS STRUCT to build STRUCT values;
failed to parse CREATE [TEMP] FUNCTION statement at [3:44]
*/
これが失敗する理由として、BigQueryにはレコードを保持することが出来る型がないからだと考えられます。
調べてみるとSQLServerにはTABLE型が存在するため同様のことを行っても失敗しなさそうでした。
次にエラーで言われている通りSTRUCTにして返せばどうだろうということで試してみましたがこれも失敗。
CREATE TEMP FUNCTION sample_repos() AS ((
SELECT AS STRUCT * FROM `bigquery-public-data.github_repos.languages`
));
SELECT
*
FROM
(SELECT sample_repos())
/* 結果:エラー
Scalar subquery produced more than one element
*/
理由としてはエラー文の通りUDFで複数の値を返さないで!ということですね。
型推論でSTRUCTと判断したんだとと思いますが、その型に対して複数レコード返そうとしたためエラーとなりました。
成功...
レコードで返すのがダメなら配列にしてUDFの呼び出し側でUNNESTしてあげれば使えそうだなと思い実行してみたらこれは成功しました。
CREATE TEMP FUNCTION github_repos() AS ((
SELECT ARRAY (
SELECT AS STRUCT
*
FROM
`bigquery-public-data.github_repos.languages`
)
));
SELECT
*
FROM
UNNEST(github_repos())
呼び出し側でUNNESTしているのが分かりにくいのですがギリギリ許容範囲...
BigQueryがTABLE型を追加してくれればもう少し簡単にできそうなので期待して待ってます。
使い所
ここまでUDFでテーブルを返すことを考えていたのですが、ちゃんと使いどころは抑えないといけません。
ただただ1テーブルのWHERE句の条件を引数に取るものでも多少は良いかもしれませんが、真に良いなと思ったところは複雑な条件式・join・集約などを統一することが可能な点でした。
例えば今まで例で使っていたテーブルでPythonかGoを使っているリポジトリに絞りたいという場合、この条件をクエリで書くとすると自分はパッと2パターン思いつきました。
パターン1
愚直に書くとこうなりました。
ただし違う言語も抽出したい時はORの条件式を増やすことになります。
SELECT
repo_name,
language
FROM
`bigquery-public-data.github_repos.languages`
WHERE
'Python' IN (SELECT name FROM UNNEST(language))
OR 'Go' IN (SELECT name FROM UNNEST(language))
パターン2
CROSS JOINを使う絞り方。
languageの配列をCROSS JOINして増えた行から言語をPythonとGoに絞ります。
このままではPythonとGoの両方が含まれるリポジトリだと2レコード存在することになるため、ROW_NUMBERをリポジトリごとで算出して最初に番号を振られたレコードを取ってくることでリポジトリを一意にしました。
これなら変数が増えるだけで条件式はどんどん多くなったりはしないですね。
ただし少しトリッキーなのである程度SQLを触ったことがないと理解は難しいかもしれません。
SELECT
repo_name,
language
FROM (
SELECT
repo_name,
language,
ROW_NUMBER() OVER (PARTITION BY repo_name) AS number
FROM
`bigquery-public-data.github_repos.languages`
CROSS JOIN
UNNEST(language) AS search_language
WHERE
search_language.name IN ('Python', 'Go')
)
WHERE
number = 1
どちらが良いのか
正直1回のみ抽出する分にはどちらのやり方でも良いと思います。
しかし後で同じように抽出を行いたい人が出てきた時にパターン1やパターン2のクエリがあった時に混乱します。
このような少し複雑な条件が必要な時にUDFを使うことで便利に使い回すことが可能なのではないかと考えました。
UDFを使ったら
ここでUDFを使った時にどうなるのか考えてみました。
抽出する言語の数は可変にしたいためパターン2の方が適切です。
UDFの引数をSTRINGの配列にすればいくつの言語でも対応できるからです。
CREATE TEMP FUNCTION repos_or_filter(filter_languages ARRAY<STRING>) AS ((
SELECT ARRAY (
SELECT AS STRUCT
repo_name,
language
FROM (
SELECT
repo_name,
language,
ROW_NUMBER() OVER (PARTITION BY repo_name) AS number
FROM
`bigquery-public-data.github_repos.languages`
CROSS JOIN
UNNEST(language) AS search_language
WHERE
search_language.name IN UNNEST(filter_languages)
)
WHERE
number = 1
)
));
SELECT
*
FROM
UNNEST(repos_or_filter(['Python', 'Go']))
この時点でこのUDFを永続化しておけば次から同じことをしたい人は以下のように抽出することができます。
SELECT
*
FROM
UNNEST(`project.dataset.repos_or_filter`(['Python', 'Go']))
これで複数の書き方があり悩むことは減りますし、もしもさらに良いパフォーマンスや簡潔なクエリの書き方が見つかった時にはこのUDFを変更すれば良いだけなので、分散したクエリのメンテナンスコストも大幅に削減することができます。
終わりに
毎回毎回クエリを考えて書くことも勉強にはなるのですが、本質はクエリを書くことではなく如何に早く適切なデータを抽出し分析に時間を使うかだと思うので、ミスや時間がかかるクエリは減らしていきたいですね。
Discussion