邪道だけど安くて簡単 - GCPで重いバッチ処理

はじめに
Google Cloud Platform Advent Calendar 2019: 19日目の記事です
この記事では比較的新しい分析組織という中で実装した,GCPサービスでコストを抑えながら重いバッチ処理をスケジュールで回す仕組みについて記します。
インフラ環境が整っていなかったり,予算の都合などから金額を気にしている方には今の所オススメの方法です。
これよりオススメの方法があったら教えてくださると幸いです。
対象ではない人
以下の人にはこの記事をオススメしません。
- インフラ・サーバーエンジニアがインフラ運用してくれるチーム
- デプロイまでの綺麗なインフラ環境を目指している人
- Cloudの料金を気にしなくて良い人
- Cloud Functionsで事足りる人
- そもそもGCPやアーキテクチャ周り詳しい人
構築した設計
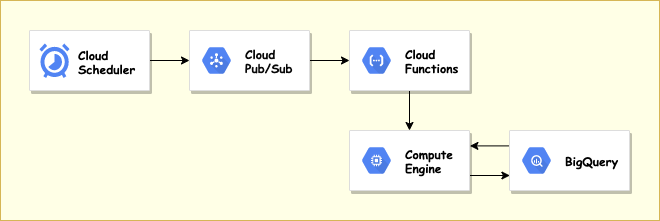
今回は一番簡単に実装できそうだったGCPのチュートリアルを参考に上記の設計でバッチを組みました。
| サービス | 役割 |
|---|---|
| Cloud Scheduler | cron形式でスケジュールの発火 |
| Cloud Pub/Sub | メッセージ送信に用いる。httpを使わない理由は先ほど貼ったチュートリアルのリンクを参照 |
| Cloud Functions | ComputeEngineのインスタンス起動スクリプトを実行 |
| Compute Engine | バッチ処理 |
| BigQuery | データ連携 |
他に考えた構成
とりあえず以下の構成を考えました。
-
CloudFunctions
- メモリ上限が2GでGCSをうまく利用しても綺麗に作るのは難しそうだった。
無理やり分解すれば可能だったがそのやり方はGCFとGCSの往復を何回もすることになるので可能なら避けたかった。
Scheduler → GCF → BigQuery → GCS → GCF → GCS → GCF → BigQueryのようにそれぞれ一次集計・二次集計とわかりにくくなりそうだった。
他のタスクで分かりやす買ったらCloudFunctionsをモノレポで管理していたりします。
- メモリ上限が2GでGCSをうまく利用しても綺麗に作るのは難しそうだった。
-
CloudRun・KubeFlow
- 0インスタンスからオートスケール設定をすれば安い料金で構築できるが、分析組織でGKEを使うにはまだ早いフェーズだったので後回しにした。
今後組織的に余裕ができるか、バッチが乱雑するようなら本格的に取り組む予定。
とりあえず一人でお試しコンテナ運用で様子見を行いフェーズに合ってきたら布教。
- 0インスタンスからオートスケール設定をすれば安い料金で構築できるが、分析組織でGKEを使うにはまだ早いフェーズだったので後回しにした。
-
DataFlow
- 正直今回のアーキテクチャでバッチの内容が単純ならDataFlowも合っている気がしている。
しかしApacheBeamの学習コスト的にそれをチームに強いるのは考えものというのと、DataFlowではシステム領域で必要になる外部ライブラリやレコードのストリーム内での外部連携に適していないため今回の実装では見送り。
(機械学習での前処理など単純なものにはピカイチ。個人的にはscalaかつApacheBeamの存在を匂わせないので scio が好き。)
- 正直今回のアーキテクチャでバッチの内容が単純ならDataFlowも合っている気がしている。
上記のような理由から費用的・学習的コストを考え今のフェーズに適していると考えた構成を取り入れました。
構築
CloudScheduler
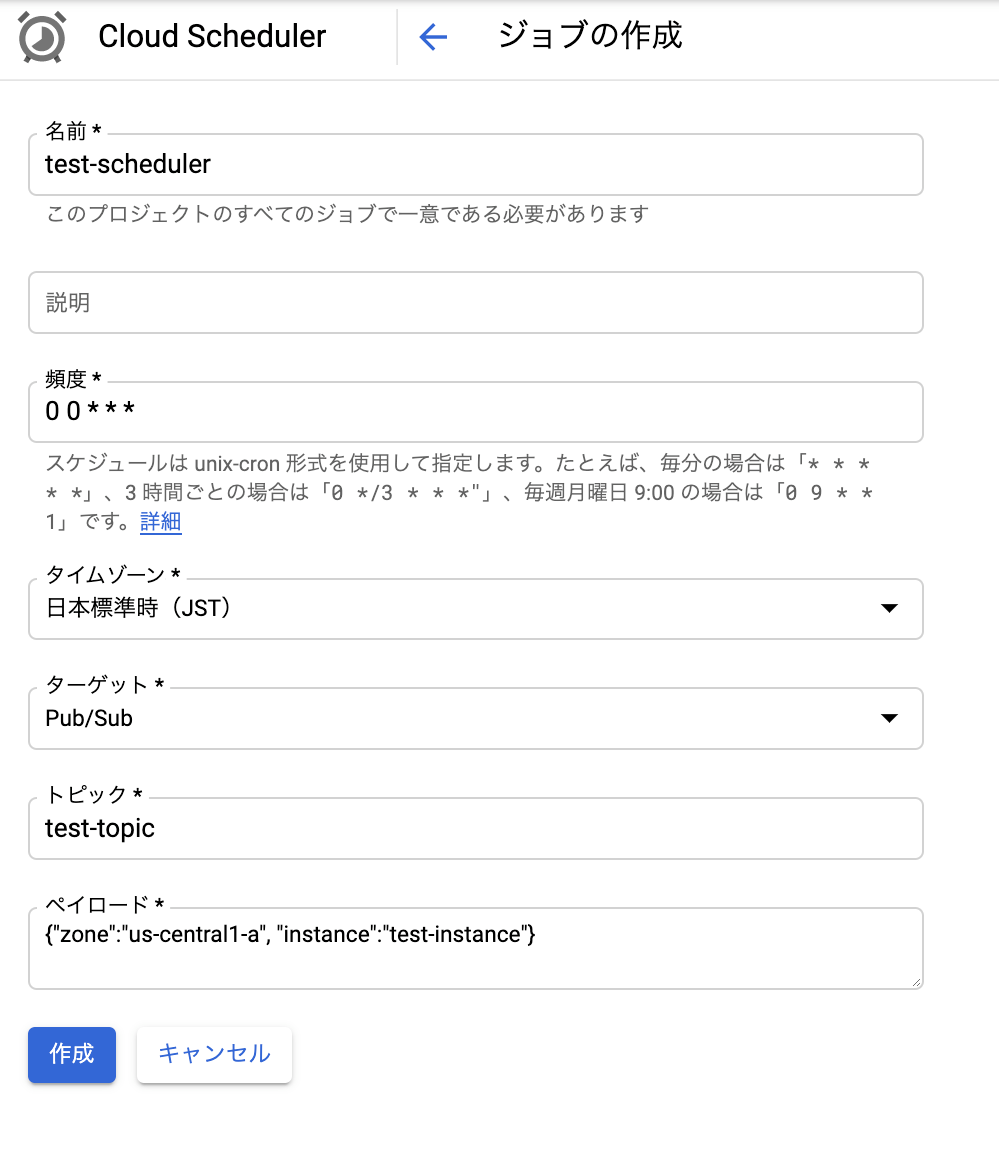
ジョブの作成から適当な名前をつけ、頻度はcron形式で発火タイミングを指定します。
CloudSchedulerからCloudFunctionsへPub/Subで呼ぶのでターゲットをPub/Subに指定し、トピックは適当に名前をつけます。
本構成にあたり、いくつか別タスクのインスタンスを起動できるようにするためにペイロードの値によってCloudFunctions側で起動するインスタンスを分けられるようにします。
そのためzoneとinstanceを指定し、2種類のインスタンスを建てたい場合は複数のSchedulerでペイロードの値を変えて切り分けました。
CloudFunctions
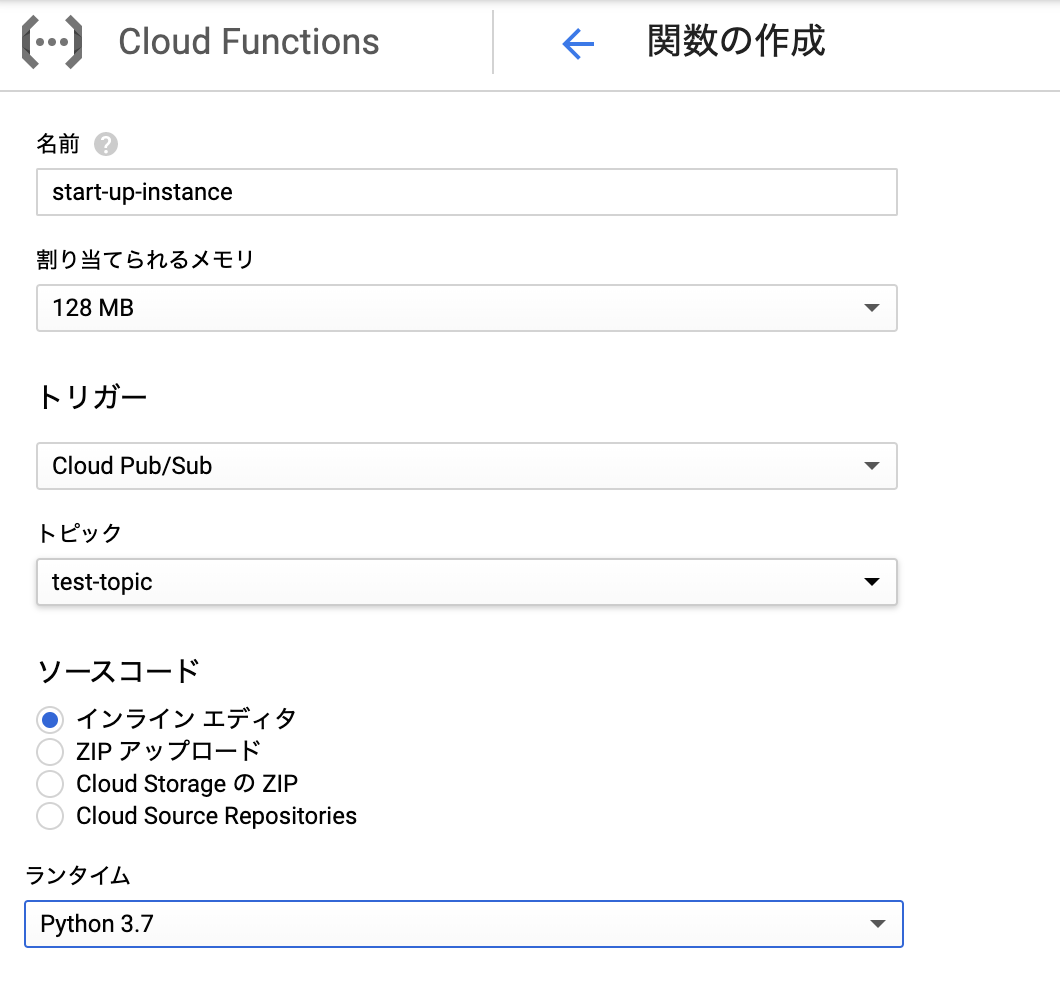
インスタンス起動用のスクリプトを動くようにします。
名前を適当につけ、割り当てメモリは最小の128Mで十分かと思います。
トリガーをPub/Subに設定し、トピックは先ほど指定したtest-topicを新しいtopicを作成から作ります。
今回はテスト的に行うのでソースコードはインラインエディタでデプロイします。
そして実行する関数を以下のソースコードだったらstart_up_instanceに設定し、詳細の環境変数でprojectを設定しました。
projectをまたいでインスタンスを起動することはないと思うので環境変数に設定しましたが、payloadで渡してあげても良いです。
import base64
import json
import os
import logging
from oauth2client.client import GoogleCredentials
from googleapiclient.discovery import build
def start_up_instance(event, context):
"""Triggered from a message on a Cloud Pub/Sub topic.
Args:
event (dict): Event payload.
context (google.cloud.functions.Context): Metadata for the event.
"""
message = base64.b64decode(event['data']).decode('utf-8')
payload = json.loads(message)
project = os.environ['project']
instance = payload['instance']
zone = payload['zone']
credentials = GoogleCredentials.get_application_default()
compute = build('compute', 'v1', credentials=credentials, cache_discovery=False)
instance = compute.instances().get(project=project, zone=zone, instance=instance).execute()
if instance['status'] == 'TERMINATED':
compute.instances().start(project=project, zone=zone, instance=instance['name']).execute()
google-api-python-client==1.7.11
oauth2client==4.1.3
GCE
ここからが邪道です。
インスタンスの起動時にインスタンス内のcrontabか、GCEのstart_up_scriptにバッチ実行シェルを仕込むという方法です。
今回は前者で行いました。
実際に動かしているバッチ処理の重さは使いたい人の一日のデータ量の設定や、ログの量によって可変で短ければ数分・長ければ1時間以上と可変になってしまっています。
そのためcronの処理終了時に少し余裕を持たせてからシャットダウンを行うようにしています。
シャットダウンのコマンドはsudo権限が必要なのでsudo権限がついているユーザーでcronを作成する必要があります。
$ crontab -e # sudo権限があるユーザーで
# ↓↓↓ 記入するのはこれだけ ↓↓↓
@reboot sh /{パス}/run.sh > /{パス}/$(date '+%Y%m%d').log
#!/bin/sh
/usr/local/bin/python3 1.py; # 動かしたいバッチ
/usr/local/bin/python3 2.py; # シェルなら1,2,3と分けることも可能
/usr/local/bin/python3 3.py;
sleep 5m; # もしもバッチで処理したいデータが無かった場合,すぐにシャットダウンしてしまうので5分余裕を持たせている.
/sbin/shutdown -h now;
exit 0;
バッチの中でBigQueryやGCSを呼んでいますが今回の話とはやや逸れるので省きます。
何が良いのか
CPUやメモリ、GPUなども自由に選択できるので開発のスピードを求められる時などは有用かと思います。
しかしこれらが乱雑してしまうと管理コストが大きくなると思うのでコンテナ管理する方をお勧めします。
初期のテスト段階として検証用に使う分には問題はないかなと思っています。
終わりに
分析チームにもインフラを管理してくれるエンジニアが一人でもいると非常に助かるなと思いました。
Discussion