React の useEffect の実行タイミングについて、このように思っていませんか?
- 依存配列(第2引数として渡す配列)を省略したら、マウント時に、そのあと再レンダーごとに実行される
- 依存配列に空配列を入れたら、マウント時に実行される
- 依存配列に値を入れると、マウント時と、値が変わるごとに実行される
しかもクリーンアップ関数も絡んで来て、もっと複雑で覚えられない…
…そのように考える必要はありません。
実は、useEffect の規則は至ってシンプルで、しかも UI ロジックの頻出の課題を洗練されたパターンに落とし込んで解決してくれます。
エフェクトとクリーンアップの実行タイミングは、以下のように論理的にシンプルな形で捉えることができます。
- マウント時 に初回のエフェクトが発火され、アンマウント時 に最後のクリーンアップが実行される。
- 再レンダリング時 に、前回のエフェクトをクリーンアップしたあと、エフェクトが再び発火される
- (ただし、依存配列を指定することによって、この「クリーンアップ→再発火」が不要なときに省略できる)
既にこちらの short 動画で発信した内容ですが、文字としても残したほうが良いと思うので残しておきます。
旧バージョン
取り扱わないこと
- useEffect と useLayoutEffect etc. の発火が同期/非同期で云々…
- 親・子のコンポーネントでの発火・クリーンアップの順番
1. マウント時にエフェクト発火→アンマウント時にクリーンアップする
「useEffect と、そのクリーンアップ関数はいつ実行されるの?」という疑問に答える前に、ミニマルな例から出発しましょう。
useEffect の基本は「🔥発火→🚮クリーンアップ」のライフサイクルです。
useEffect(() => {
console.log("1. Effect fired!");
return () => {
console.log("2. Effect cleaned-up!");
}
});
再レンダリングを一度無視してみましょう。すると、このような順番で実行されます。
- 🔥コンポーネントがマウント(初めてのレンダリング)されたあとで、エフェクトが発火する
- 「1. Effect fired!」とコンソールに表示される
- 🚮コンポーネントがアンマウントされた(レンダー対象から外れる)あとで、クリーンアップ関数が実行される
- 「2. Effect cleaned-up!」とコンソールに表示される
2. 再レンダリング時に、クリーンアップ→再びエフェクト発火
const [count, setCount] = useState(0);
useEffect(() => {
console.log(`count: ${count}, Effect fired!`);
return () => {
console.log(`count: ${count}, Effect cleaned-up!`);
}
});
return (
<div>
<div>{count}</div>
<button onClick={() => setCount(count + 1)}>Increment</button>
</div>
);
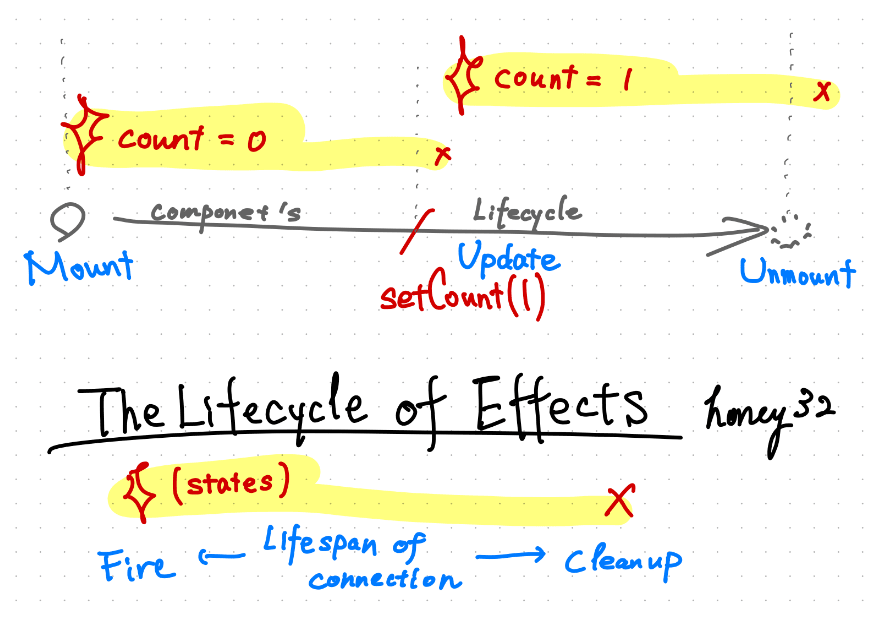
次に、そのコンポーネントに count ステートが存在して、それが更新される場合を考えて見ましょう。
- 🔥コンポーネントがマウント(
countの値は0)されたあとで、エフェクト(count = 0)が発火する- 「count: 0, Effect fired!」
-
count が 1 に更新されたとき、
count = 1で再レンダリングされる。 - 🚮
count = 0のときのエフェクトがクリーンアップされる- 「count: 0, Effect cleaned-up!」
- 🔥そのあとで、
count = 1でエフェクトが発火する- 「count: 1, Effect fired!」
- 🚮コンポーネントがアンマウントされたあとで、クリーンアップ関数が実行される
- 「count: 1, Effect cleaned-up!」
このような挙動になる理由は、useEffect とクリーンアップ関数がクロージャとしてステートの変数を捕捉していることから明らかですが、
count が 0 → 1 に変わった直後に実行されているクリーンアップ関数の中では、 count の値が 0 のままになります。そのお陰で、エフェクト発火と、それに対応するクリーンアップの関数内の値が 常に一致しています。
なので、(極々まれな)オブザーバーの開始 / クリーンアップの両方に count の値が必要な場合でも、 count の値がズレることが原因でバグが起きる余地がありません。
オブジェクトはエフェクト発火時に生まれて、クリーンアップ時に破棄される
実は、エフェクト発火→クリーンアップがこのように実行されるサイクルは、そのまんまオブジェクトの生存期間に合致します。
const ref = useRef<HTMLDivElement>(null);
useEffect(() => {
const elem = ref.current;
if (!elem) return;
const observer = new ResizeObserver((entries) => {
entries.forEach((entry) => {
const size = entry.borderBoxSize[0];
console.log(`(${size.inlineSize}, ${size.blockSize})`);
});
});
// オブザーバをDOM要素に接続する
observer.observe(elem);
return () => {
// クリーンアップ関数で、オブザーバによる監視をすべて終了する
observer.disconnect();
};
});
- 🔥エフェクト発火時に ResizeObserver というクラスのインスタンスが生成される
- 🚮クリーンアップ時に、その ResizeObserver を破棄する
というふうにコードに書かれている順番そのまんまで、オブジェクトが生まれて破棄されます。
実は、このように「クリーンアップしたらもう使われないオブジェクト」については、useState や useRef にそれを保存するコードを書いてしまいがちですが、実は必要ありません。
「ライフタイム」の観点
上記の「ライフタイム」の視点ではイレギュラーです。
オブジェクトの生存期間に着目すると 2. レンダー より長く、2回のレンダー間で生存していますが、
関数のスコープに着目すると、エフェクトの関数の外側から参照・操作することが出来ないので、コードがかなり堅牢になったと言えると思います。
WHY これが複雑に見えるクリーンアップ関数
実は、複雑に見えた「エフェクト関数・クリーンアップ関数の実行タイミング」ですが、このように「オブザーバーを生成して破棄する」サイクルを、極めてシンプルなコードに落とし込める仕組みになっているのです。
しかも、エフェクト発火時と、それに 対応するクリーンアップの時 とでステートが常に一致しているので、いくら特殊なケースであっても正確にクリーンアップできる訳です。
(別のフレームワークの名前)には onMount / onUpdate / onUnmount みたいな機能があるのに、React の useEffect はこれらがゴチャ混ぜになっていて分かりにくい
という批判が(学習難易度を度外視すれば)的外れであることが分かると思います。
HOW どのような方法で実現してるの?
関数のスコープとその中にあるローカル変数は、自然とこのような挙動を取るので、不思議ではないと思います。
React の関数コンポーネントでは、useEffect だけでなく至る所で関数と変数のこのような性質が利用されていて、State as a Shapshot と呼ばれています。
旧来のクラスコンポーネントでは、オブジェクトのプロパティとして ステートと Props を扱っていたのですが、リアルタイムな値を取得してしまうため、「更新される前の値を取ってくる」ことが難しかったのですが、
関数コンポーネントになることで、ただコードの見た目が短くなっただけでなく、概念としても遥かにシンプルで洗練されたものになっているんですね。
3. やっと登場する依存配列、ESLint に列挙してもらおう
ここまでは依存配列(第2引数として渡す配列)無しの useEffect の挙動を解説してきましたが、依存配列を使用しないと、一つの問題が生じます。
なぜなら、エフェクトが再レンダリングのたびに実行されるので、「目当ての変数(コード例では count) が変わっていない」場合にも実行されてしまうからです。
この「エフェクトを再実行する必要がないのに実行されてしまう」問題を解決するために依存配列が必要なのです。
ただし、一点注意すべきところがあります。
[]のときは、マウント時にエフェクト発火、アンマウント時にクリーンアップ、そして、依存配列に入れた変数が変わったときにエフェクトが発火し、(そのまえにクリーンアップ)
と考えられがちですが、そうではありません。
と考えるべきです。
なので、「A, B, C が変わったときに発火してほしいから依存配列に追加する」とか、「マウント時にしか実行してほしくないから(ESLint のエラーを無視して)依存配列を空にする」のではなく、
ESLint (react-hooks/exhaustive-deps ルール)の auto-fix を使って、必要な変数が全て自動的に補完してもらう
のが「ただ動くだけでなく、バグの多くを回避できて、意図を明確にできる」コードを書くために必要、あえて強い言葉を使えば必須である、と言えます。
むしろ、機械的に決めることが可能で、人力だとケアレスミスが起きがちなところを、機械に任せるということなので、むしろ慣れてしまえば楽になってきます。
useEffect(() => {}, []) は「❌依存配列に空配列を入れたから"マウント直後に"発火される」というよりも「🙆♀一つも変数を使用しなかったので、最適化の結果としてマウント直後にしか発火されなかっただけ」と考えるほうが良いと思います。
関数の中身に修正が入って使用する変数が増えてしまった場合は、(ESLint がそれらを自動的に依存配列に記載してくれるので、)再レンダリング時にクリーンアップ・再発火するようになります。 再実行するべくして再実行します。
useEffect(() => {
- const observer = someObserver();
+ const observer = someObserver({ userId });
return () => { observer.disconnect() }
- }, []);
+ }, [userId]); // やっぱり userId が必要だった!
そう考えれば、「依存配列なし」と「依存配列に空配列を入れる」の違いに悩む必要もなくなりますし、「空配列と空じゃない配列」も、ただエフェクト内で使用している変数の多寡の違いでしかないことが理解できると思います。
あとがき: 公式ドキュメントを読み、設計の意図を知ろう
いかがだったでしょうか?
React は、理解せずに使おうとすると難解ですが、「どのように UI のロジックを書くのが最善か」という目線で設計されているので、その設計意図を理解すると、むしろ UI のロジックを書くのが簡単で楽しいと感じられてくると思います。
React の新公式ドキュメントには、その設計意図が丹念に込められているので、目を通すことをおすすめします。
実は、この記事とたまたま似た内容の記事も React の新ドキュメントにも掲載されています。
正確には、useEffect の設計意図を知るために参考にした記事が、おそらく上記のドキュメント記事の著者と同じ Dan Abramov 氏によるものなので必然といえば必然ですが…
約1年前にも useEffect の解説記事を書いたことがありますが、今回はそれのブラッシュアップ版でもあります。

Discussion