LLMによるナレッジグラフの作成とハイブリッド検索 + RAG
はじめに
langChainはNeo4j(グラフDB)をサポートしています。
今回はそちらの機能(langChain × Neo4j)を使い、ナレッジグラフの作成、検索など以下の実装を試してみます。
- llmを使いテキストからグラフを生成
- グラフのノード情報からハイブリッド検索(全文検索とベクトル検索)を実行
- グラフのリレーションシップ情報からベクトル検索を実行
- テキストからハイブリッド検索(全文検索とベクトル検索)を実行
- 3つの検索(ノード、リレーションシップ、テキスト)を用いたRAG
- Cypherクエリをllmで生成 → 結果から回答
- 検索したノードの周辺情報(関係するノードとリレーションシップ)を用いたRAG
ナレッジグラフとは
ナレッジグラフは情報をグラフ構造によって表したものです
(Neo4jにおける)ナレッジグラフはノード(人、場所、物などのオブジェクト)とそれらを繋ぐリレーションシップ(関係)で構成されています。
ノードにはラベル、リレーションシップにはタイプが付けられ、それぞれプロパティを持つことができます。具体的には以下のような構造です。
-
ノード (Node)
人、場所、物などのオブジェクトです。-
ラベル (Label)
ノードのグループや分類を表します(人物の場合は「Peason」など)。 -
プロパティ (Property)
idやtextなどの属性情報です(人物の場合は「text: 人物像の説明」など)。
-
ラベル (Label)
-
リレーションシップ (Relationship)
ノード間の関係を表します。「教師 -> 生徒」などの方向性を持っています(教師と生徒の場合は「(Teacher)-[:TEACHES]->(Student)」など)。-
タイプ (Type)
リレーションシップの種類や性質を表します(教師と生徒の場合は「TEACHES」など)。 -
プロパティ (Property)
idやtextなどの属性情報です(人物の場合は「text: 関係性の説明」など)。
-
タイプ (Type)
準備
グラフデータベース(Neo4j)の準備
今回、ナレッジグラフの作成にはNeo4jを使用します。Neo4jはグラフデータベースの管理ツールです。
グラフデータの操作には「Cypher(サイファー)」という独自のクエリ言語を使用します(MySQLやPostgreSQLにおけるSQLのようなものです)。
Cypherクエリに関しては、以下の記事が参考になります。
neo4jの環境はローカルでも構築することはできますが、今回はクラウド上で無料 & 手軽に構築できるNeo4j AuraDB Freeを使ってみます。
Neo4j AuraDB Freeは制限(インスタンス数1、ノード数が200k、リレーションシップ数400kなど)はありますが個人で試すのであれば十分かと思います。
以下の「Start Free」からアカウントの作成、ログインが行えます。

ログイン後、利用規約などを確認して進めていくと以下の画面になります。(無料版を利用する場合は)「Create Free instance」を選択してください。
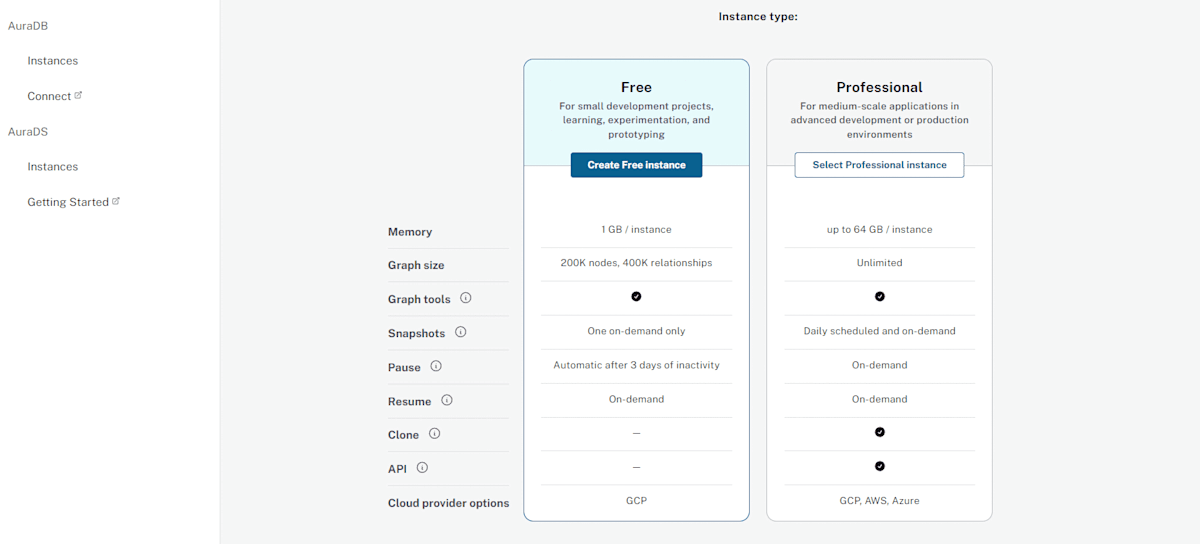
インスタンスが作成され、パスワードが表示されます(インスタンスへ接続するのに必要となるため控えておきましょう)。

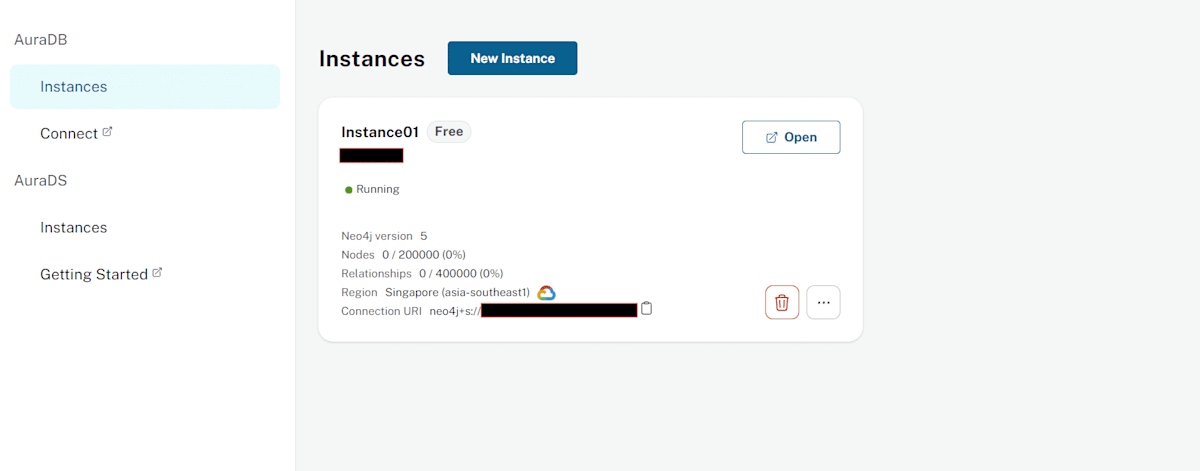
作成したインスタンスが表示されます。「Open」をクリックしましょう。(表示されている「URI」はインスタンスへ接続するのに必要となるため控えておきましょう)。
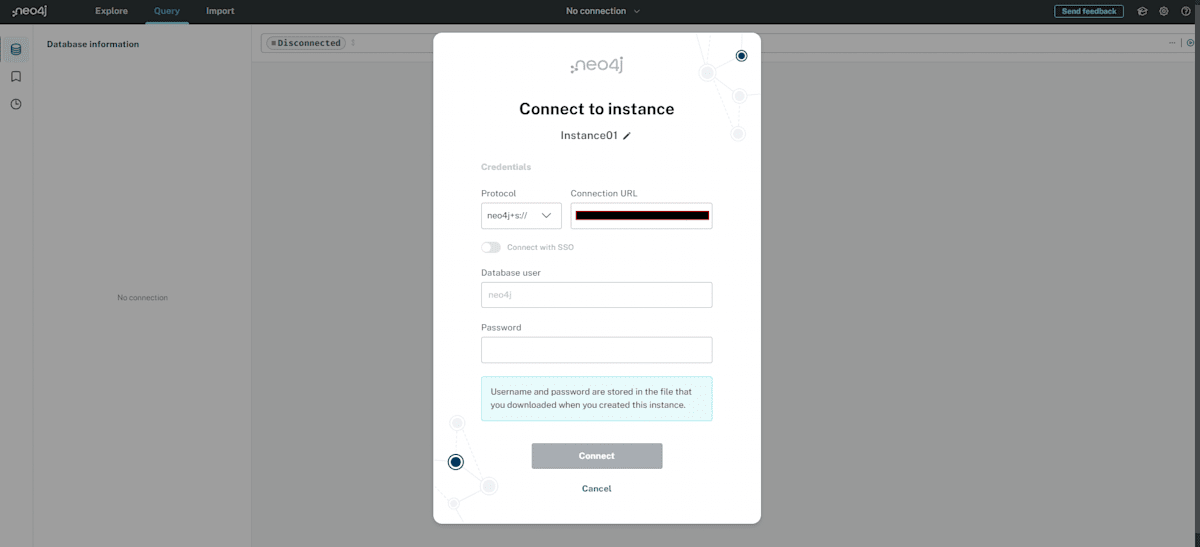
先ほど表示されたパスワードを入力してインスタンスに接続します。デフォルトで「neo4j」というユーザー名が設定されています。
インスタンスに接続できた場合、以下の画面になります。デフォルトで「neo4j」という名前のDBが作成されています。今回はこのDB上にグラフの作成を行います。
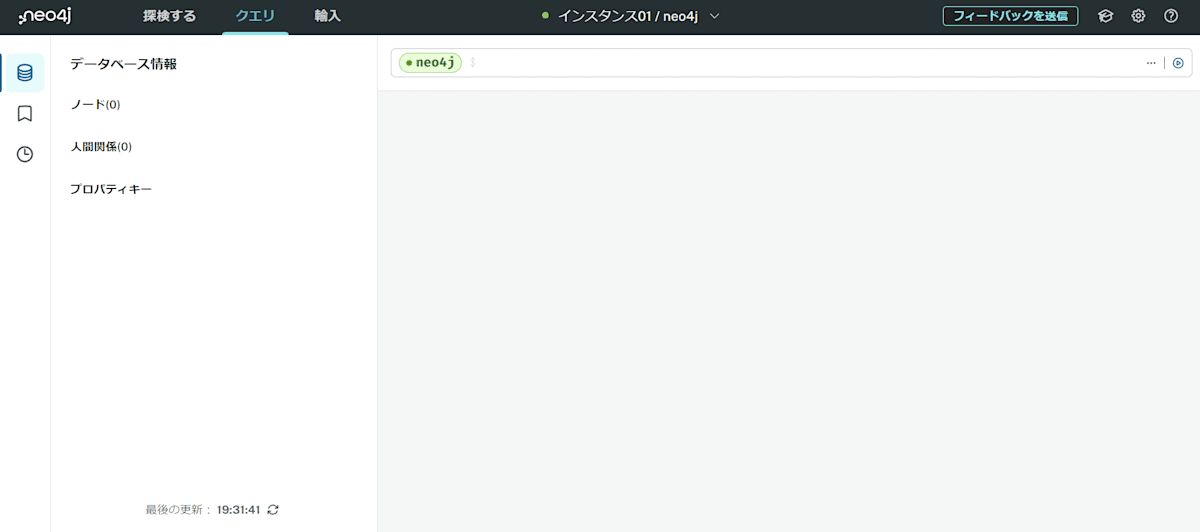
まずは簡単なグラフを作成してみます(この後、Pythonコードから新しくグラフを作成するため行わなくても問題ありません)。
「neo4j」と記載された部分にCyperクエリを入れて実行(Ctrl + Enter)することで作成や検索ができます。
以下を実行してグラフを作成してみましょう。
// グラフの作成
CREATE
// Companyラベルがついた各ノードを作成(それぞれのオブジェクトを定義)
(companyA:Company {name: 'CompanyA'}),
(companyB:Company {name: 'CompanyB'}),
// Departmentラベルがついた各ノードを作成(それぞれのオブジェクトを定義)
(deptA:Department {name: 'DeptA'}),
(deptB:Department {name: 'DeptB'}),
(deptC:Department {name: 'DeptC'}),
// Personラベルがついた各ノードを作成(それぞれのオブジェクトを定義)
(alice:Person {name: 'Alice', age: 30}),
(bob:Person {name: 'Bob', age: 25}),
(carol:Person {name: 'Carol', age: 27}),
(dave:Person {name: 'Dave', age: 35}),
// PersonからPersonへのFRIENDタイプのリレーションシップを作成(定義したオブジェクト同士を連結)
(alice)-[:FRIEND]->(bob),
(alice)-[:FRIEND]->(carol),
(bob)-[:FRIEND]->(dave),
(carol)-[:FRIEND]->(dave),
// PersonからPersonへのKNOWSタイプのリレーションシップを作成(定義したオブジェクト同士を連結)
(alice)-[:KNOWS]->(dave),
(bob)-[:KNOWS]->(carol),
// DepartmentからCompanyへのPART_OFタイプのリレーションシップを作成(定義したオブジェクト同士を連結)
(deptA)-[:PART_OF]->(companyA),
(deptB)-[:PART_OF]->(companyA),
(deptC)-[:PART_OF]->(companyB),
// PersonからDepartmentへのWORKS_INタイプのリレーションシップを作成(定義したオブジェクト同士を連結)
(alice)-[:WORKS_IN]->(deptA),
(bob)-[:WORKS_IN]->(deptA),
(carol)-[:WORKS_IN]->(deptB),
(dave)-[:WORKS_IN]->(deptC);
上記は以下のような構造となっています。
- 2つの会社(companyA、companyB)がある
- それぞれnameプロパティを持っている
- 3つの部署(deptA、deptB、deptC)がある
- それぞれnameプロパティを持っている
- deptAとdeptBはcompanyA、deptCはcompanyBの会社の部署である
- 4人従業員(alice、bob、carol、dave)がいる
- それぞれname、ageプロパティを持っている
- 従業員同士でFRIEND(友達)またはKNOWS(知っている)の関係性を持っている
- aliceとbobはdeptA、carolはdeptB、daveはdeptCに所属している
グラフを作成後、以下のクエリを実行することでグラフ(すべてのノードとリレーションシップ)を表示できます。
// すべてのノードとリレーションシップを表示
MATCH (n)-[r]->(m)
RETURN n, r, m
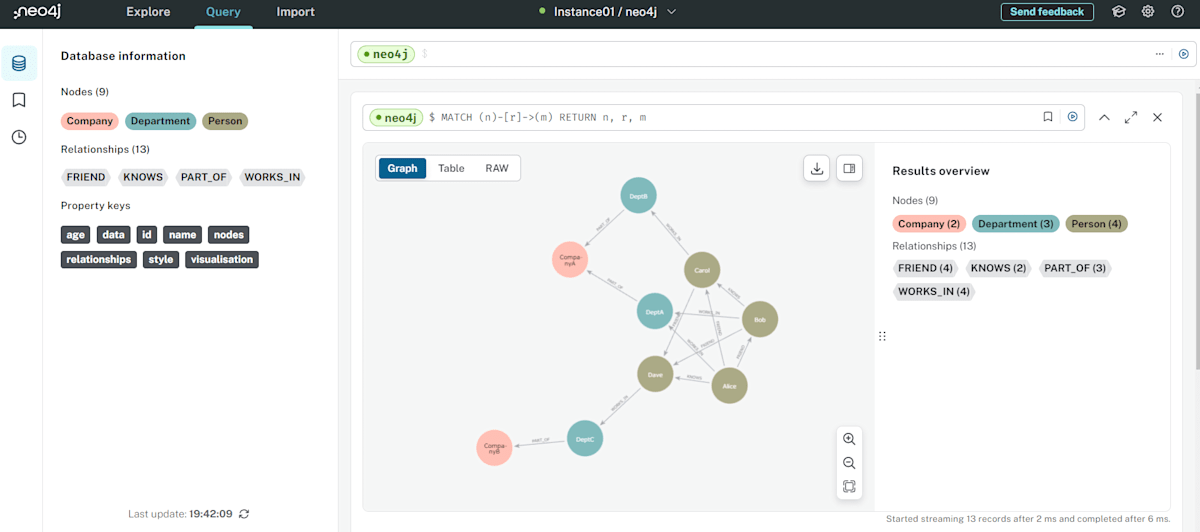
上記のようにグラフが表示されます。ノードやリレーションシップを選択するとそれぞれのプロパティを確認することもできます。
グラフを確認したら(この後、新しく作成するため)削除を行います。
// すべてのノードとリレーションシップの削除
MATCH (n)
DETACH DELETE n
neo4jの準備と確認は以上です。
ライブラリの準備
使用するライブラリをインストールします。
$ pip install langchain
$ pip install langchain-community
$ pip install langchain_anthropic
$ pip install langchain-huggingface
$ pip install sentence-transformers
$ pip install langchain-experimental
$ pip install neo4j
モデルの準備
今回、llmモデルはAnthropicの「Claude 3.5 Sonnet」、埋め込みモデルは「intfloat/multilingual-e5-large」を使用しました。他のllm(Azure OpenAIやOpenAIなど)を使用している方は、コード内のモデルの読み込みとAPIキーの設定箇所を変更して試してください。
使用するテキスト
今回使用するテキストは以下(「葬送のフリーレン」のWikipedia)の「あらすじ」部分(2024/06/28現在)に「フェルンはフリーレンの弟子」の文言を最後に付け足したものです(フェルンとフリーレンが師弟関係であることをllmに読み取らせるために付け足しています)。
(「あらすじ」部分)
フェルンはフリーレンの弟子
上記を任意のテキストファイルに保存します。
以上で準備は完了です。
1. llmを使いテキストからグラフを生成
コード(全体)
import os
from langchain_community.document_loaders import TextLoader
from langchain_anthropic import ChatAnthropic
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_community.graphs import Neo4jGraph
# AnthropicのAPIキー
os.environ["ANTHROPIC_API_KEY"] = ""
# Neo4jへの接続情報
NEO4J_URL = ""
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = ""
NEO4J_DATABASE = "neo4j"
# Neo4jへの接続情報を設定してgraphインスタンスを作成
graph = Neo4jGraph(
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE
)
# DB内のグラフを削除するクエリ(複数回実行用)
cypher = """
MATCH (n)
DETACH DELETE n;
"""
# コメントアウトを外すとcypherクエリが実行(グラフが削除)されます
# graph.query(cypher)
# テキストパス
text_path = "./葬送のフリーレン.txt"
# テキストファイルを読み込む
loader = TextLoader(text_path)
documents = loader.load()
# Claude 3.5 Sonnetモデルのインスタンスを作成
llm_sonnet = ChatAnthropic(model_name="claude-3-5-sonnet-20240620")
# llmを使いドキュメントをグラフに変換するtransformerを作成
transformer = LLMGraphTransformer(
llm=llm_sonnet,
allowed_nodes=["Person"], # 生成するノードのラベルに「Person」を設定
node_properties=["text"], # 生成するノードのプロパティに「text」を設定
relationship_properties=True # リレーションシップのプロパティ生成を「True」に設定
)
# ドキュメントをグラフに変換
graph_documents = transformer.convert_to_graph_documents(documents)
# 変換したグラフをデータベースに保存
graph.add_graph_documents(graph_documents)
上記の内、ポイントとなる箇所を確認します。
コード(ポイントとなる箇所)
Neo4jへの接続情報を設定してgraphインスタンスを作成
graph = Neo4jGraph(
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE
)
上記で作成したgraphインスタンスは、クエリの実行とグラフをデーターベースに保存するために使用しています。
DB内のグラフを削除するクエリ(複数回実行用)
cypher = """
MATCH (n)
DETACH DELETE n;
"""
# コメントアウトを外すとcypherクエリが実行(グラフが削除)されます
# graph.query(cypher)
上記は、再度実行する際にDB内をクリーンにするための削除クエリです。
「# graph.query(cypher)」のコメントアウトを外すとクエリの実行が行われます。
以下のようなcypherクエリを(グラフの保存後に)実行することでグラフの中身を確認することもできます。
# Personノードのidプロパティを確認
cypher = """
MATCH (n:Person)
RETURN n.id AS person_id
"""
result_person_id = graph.query(cypher)
print(result_person_id)
# Personノードの個数を確認
cypher = """
MATCH (n:Person)
RETURN count(n) AS person_count
"""
result_person_count = graph.query(cypher)
print(result_person_count)
# リレーションシップのタイプを確認
cypher = """
MATCH ()-[r]->()
RETURN type(r) AS relationship_type
"""
result_relationships = graph.query(cypher)
print(result_relationships)
llmを使いドキュメントをグラフに変換するtransformerを作成
transformer = LLMGraphTransformer(
llm=llm_sonnet,
allowed_nodes=["Person"], # 生成するノードのラベルに「Person」を設定
node_properties=["text"], # 生成するノードのプロパティに「text」を設定
relationship_properties=True # リレーションシップのプロパティ生成を「True」に設定
)
「LLMGraphTransformer」に各種パラメータを設定することでどのような構成でグラフを作成するかある程度操作することができます。上記の場合、"text"プロパティを持ったPersonノードとそれらを繋ぐ任意のプロパティを持ったリレーションシップが作られるようにパラメータを設定しています。
参考:
ドキュメントをグラフに変換
graph_documents = transformer.convert_to_graph_documents(documents)
読み込んだドキュメントをグラフに変換します。
※ llmを使い作成するため、実行結果は狙ったものが出せるとは限りません。今回の場合、リレーションシップのプロパティ生成が行われませんでした。
変換したグラフをデータベースに保存
graph.add_graph_documents(graph_documents)
最後に作成したグラフをデータベースに保存しています。
実行結果
グラフを作成後、neo4jの画面上で生成したグラフを確認してみます。
// すべてのノードとリレーションシップを表示
MATCH (n)-[r]->(m)
RETURN n, r, m
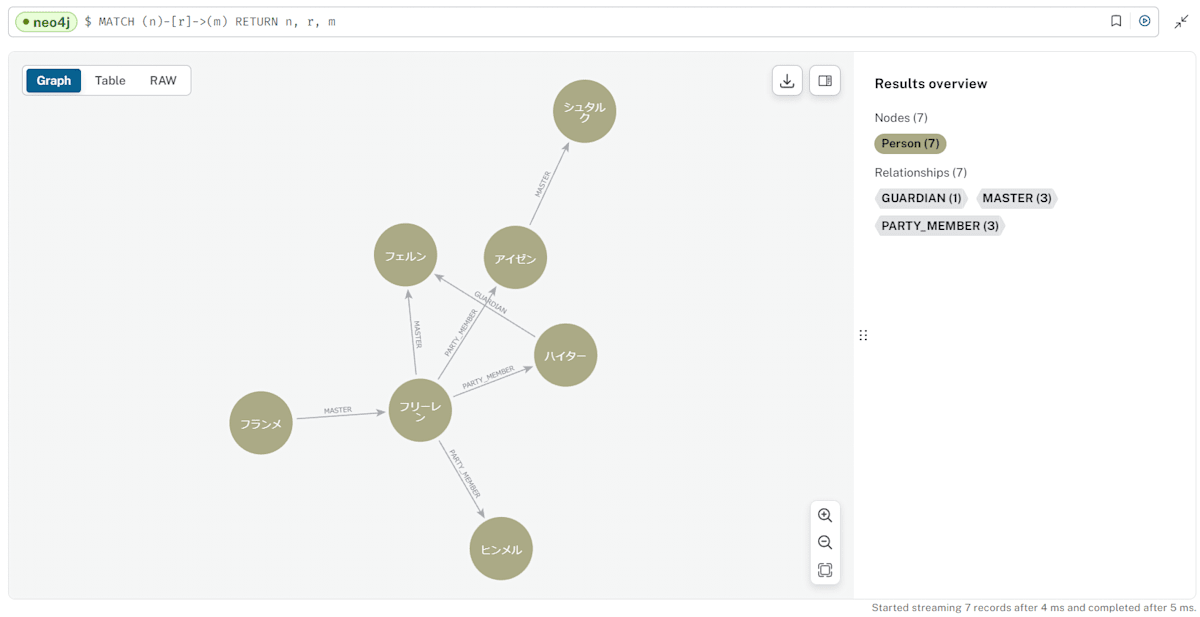
上記のようなグラフが表示されるかと思います(llmで生成しているため、生成するたびに同じグラフになるとは限りません)。
上記で生成したグラフに対して、これから検索などを試していきます。
※ グラフ生成の際にリレーションシップが作成されなかった場合、再度グラフを生成するとリレーションシップが作成されることがあります。
2. グラフのノード情報からハイブリッド検索(全文検索とベクトル検索)を実行
グラフが生成できたので、今度はそのノードに対しての検索を行ってみます。
コード(全体)
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import Neo4jVector
# Neo4jへの接続情報
NEO4J_URL = ""
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = ""
NEO4J_DATABASE = "neo4j"
# 埋め込みモデルのインスタンスを作成
emb = HuggingFaceEmbeddings(
model_name="intfloat/multilingual-e5-large"
)
# グラフからノード検索用インデックスを取得
index = Neo4jVector.from_existing_graph(
embedding=emb,
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE,
node_label="Person", # 検索対象ノード
text_node_properties=["id", "text"], # 検索対象プロパティ
embedding_node_property="embedding", # ベクトルデータの保存先プロパティ
index_name="vector_index", # ベクトル検索用のインデックス名
keyword_index_name="person_index", # 全文検索用のインデックス名
search_type="hybrid" # 検索タイプに「ハイブリッド」を設定(デフォルトは「ベクター」)
)
# クエリを設定して検索を実行
query = "フリーレン"
docs_with_score = index.similarity_search_with_score(query, k=3)
# 検索結果の表示
for doc, score in docs_with_score:
print(doc.page_content)
print(f"スコア: {score}\n")
上記の内、ポイントとなる箇所を確認します。
コード(ポイントとなる箇所)
グラフからノード検索用インデックスを取得
index = Neo4jVector.from_existing_graph(
embedding=emb,
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE,
node_label="Person", # 検索対象ノード
text_node_properties=["id", "text"], # 検索対象プロパティ
embedding_node_property="embedding", # ベクトルデータの保存先プロパティ
index_name="vector_index", # ベクトル検索用のインデックス名
keyword_index_name="person_index", # 全文検索用のインデックス名
search_type="hybrid" # 検索タイプに「ハイブリッド」を設定(デフォルトは「ベクター」)
)
「Neo4jVector.from_existing_graph」に埋め込みモデル、接続情報とインデックス用のパラメータを渡すことで検索用のインデックスが取得できます。
上記では、Personノードの"id"と"text"プロパティの中身に対して全文検索とベクトル検索用のインデックスを取得しています。インデックスが存在しない場合は作成されます(作成されたインデックスはDBに保存されます)。「search_type」を設定しない場合、ベクター検索のみが行われます。
ベクトル検索に使うベクトルデータは(Personノードの)"embedding"プロパティに保存するように設定しています。
参考:
コードを実行後、以下のCypherクエリを実行することで保存されたインデックスを確かめることができます。
// インデックスを表示
SHOW INDEXES
インデックスを削除したい場合は以下で削除できます。
// インデックスを削除(以下は「vector_index」を削除する場合)
DROP INDEX vector_index
クエリを設定して検索を実行
query = "フリーレン"
docs_with_score = index.similarity_search_with_score(query, k=3)
検索クエリに「フリーレン」を設定して、検索結果(ドキュメントとスコア)を上位3つ取得しています。
実行結果
- query: フリーレン
id: フリーレン
text: エルフ、魔法使い、勇者パーティーのメンバー
スコア: 1.0
id: フランメ
text: 伝説の大魔法使い、フリーレンの師匠
スコア: 1.0
id: フェルン
text: 戦災孤児、ハイターの依頼でフリーレンの弟子になる
スコア: 0.9857455606037178
「フリーレン」に関連した"id"と"text"プロパティが検索出来ています。
ハイブリッド検索が行われているかに関しては結果から見定めることは難しいですが、(処理を追っていくと)neo4j_vector.pyの「_get_search_index_query」が呼び出されていることが確認できます。
def _get_search_index_query(
search_type: SearchType, index_type: IndexType = DEFAULT_INDEX_TYPE
) -> str:
if index_type == IndexType.NODE:
type_to_query_map = {
SearchType.VECTOR: (
"CALL db.index.vector.queryNodes($index, $k, $embedding) "
"YIELD node, score "
),
SearchType.HYBRID: (
"CALL { "
"CALL db.index.vector.queryNodes($index, $k, $embedding) "
"YIELD node, score "
"WITH collect({node:node, score:score}) AS nodes, max(score) AS max "
"UNWIND nodes AS n "
# We use 0 as min
"RETURN n.node AS node, (n.score / max) AS score UNION "
"CALL db.index.fulltext.queryNodes($keyword_index, $query, "
"{limit: $k}) YIELD node, score "
"WITH collect({node:node, score:score}) AS nodes, max(score) AS max "
"UNWIND nodes AS n "
# We use 0 as min
"RETURN n.node AS node, (n.score / max) AS score "
"} "
# dedup
"WITH node, max(score) AS score ORDER BY score DESC LIMIT $k "
),
}
return type_to_query_map[search_type]
else:
return (
"CALL db.index.vector.queryRelationships($index, $k, $embedding) "
"YIELD relationship, score "
)
search_typeが"hybrid"の場合に「ベクトル検索と全文検索を実行して結果を結合 → 上位のスコアを持つノードとそのスコアを返す」というようなCypherクエリを作成しています。
上記を見る限り、ハイブリッド検索は行われているようです。
3. グラフのリレーションシップ情報からベクトル検索を実行
リレーションシップをベクトル検索する前に以下の処理を行います。
準備(プロパティ追加とインデックス作成)
- リレーションシップに"text"プロパティ(関係の説明文)を追加
- リレーションシップに"embedding"プロパティを追加
- リレーションシップのベクトルインデックスを作成
1に関しては、グラフを作成する際にベクトル化に使用するプロパティが追加されなかったため、手動で"text"プロパティを追加することにしました(すでに説明文の入ったプロパティが存在する場合は不要です。その場合は2、3の"text"を実際のプロパティ名に読み替えてください)。
2で追加する"embedding"プロパティは、"text"をベクトル化したデータです。3で作成するベクトルインデックスに使用します。
3で作成するベクトルインデックスは、「Neo4jVector.from_existing_relationship_index」(リレーションシップの検索メソッド)内で自動的に作成されないため、手動で作成します(先ほどのノード検索では、自動で作成されています)。
上記の1、2、3は以下のコードで実行できます。
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.graphs import Neo4jGraph
# Neo4jへの接続情報
NEO4J_URL = ""
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = ""
NEO4J_DATABASE = "neo4j"
# Neo4jへの接続情報を設定してgraphインスタンスを作成
graph = Neo4jGraph(
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE
)
# 埋め込みモデルのインスタンスを作成
emb = HuggingFaceEmbeddings(
model_name="intfloat/multilingual-e5-large"
)
# フランメとフリーレンの関係をtextプロパティとして追加
cypher = """
MATCH (a)-[r:MASTER]->(b)
WHERE a.id = 'フランメ' AND b.id = 'フリーレン'
SET r.text = "フランメは師匠、フリーレンは弟子の関係"
"""
graph.query(cypher)
# フリーレンとフェルンの関係をtextプロパティとして追加
cypher = """
MATCH (a)-[r:MASTER]->(b)
WHERE a.id = 'フリーレン' AND b.id = 'フェルン'
SET r.text = "フリーレンは師匠、フェルンは弟子の関係"
"""
graph.query(cypher)
# アイゼンとシュタルクの関係をtextプロパティとして追加
cypher = """
MATCH (a)-[r:MASTER]->(b)
WHERE a.id = 'アイゼン' AND b.id = 'シュタルク'
SET r.text = "アイゼンは師匠、シュタルクは弟子の関係"
"""
graph.query(cypher)
# すべての「MASTER」リレーションシップを取得
cypher = """
MATCH ()-[r:MASTER]->()
WHERE r.text IS NOT NULL AND r.embedding IS NULL
RETURN elementId(r) AS id, r.text AS text
"""
master_relations = graph.query(cypher)
# 各「MASTER」リレーションシップに対してembeddingプロパティを作成して追加
for rel in master_relations:
rel_id = rel["id"]
text = rel["text"]
embedding = emb.embed_query(text)
cypher = """
MATCH ()-[r:MASTER]->()
WHERE elementId(r) = $rel_id
SET r.embedding = $embedding
"""
graph.query(cypher, {"rel_id": rel_id, "embedding": embedding})
# 生成したベクトルからインデックスを作成
cypher = """
CREATE VECTOR INDEX relationship_vector_index
IF NOT EXISTS
FOR ()-[r:MASTER]-()
ON (r.embedding)
OPTIONS {
indexConfig: {
`vector.dimensions`: 1024,
`vector.similarity_function`: 'cosine'
}
}
"""
graph.query(cypher)
処理を簡単に説明すると以下のことを行っています。
- 「MASTER」リレーションシップに対して、それぞれの関係の説明文を"text"プロパティとして追加
- 「MASTER」リレーションシップに"embedding"プロパティ("text"プロパティの中身をベクトル化したもの)を追加
- "embedding"プロパティを用いてベクトルインデックス(relationship_vector_index)を作成(作成されたインデックスはDBに保存されています)
※ インデックス作成部分の「vector.dimensions`: 1024」に関しては使用する埋め込みモデルに合わせて次元数を設定してください。
※ リレーションシップのタイプ「MASTER」に関してはグラフ作成の際に「TEACHER」や「MENTOR」になることがあります。その場合は「MASTER」を実際の名称に合わせて書き換えてください。
以上で準備は完了です。リレーションシップの検索に移ります。
コード(全体)
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import Neo4jVector
# Neo4jへの接続情報
NEO4J_URL = ""
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = ""
NEO4J_DATABASE = "neo4j"
# 埋め込みモデルのインスタンスを作成
emb = HuggingFaceEmbeddings(
model_name="intfloat/multilingual-e5-large"
)
# グラフからリレーションシップ検索用インデックスを取得
index = Neo4jVector.from_existing_relationship_index(
emb,
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE,
index_name="relationship_vector_index" # ベクトル検索用のインデックス名
)
# クエリを設定して検索を実行
query = "フランメとフリーレン"
docs_with_score = index.similarity_search_with_score(query, k=3)
# 検索結果の表示
for doc, score in docs_with_score:
print(doc.page_content)
print(f"スコア: {score}\n")
上記の内、ポイントとなる箇所を確認します。
コード(ポイントとなる箇所)
グラフからリレーションシップ検索用インデックスを取得
index = Neo4jVector.from_existing_relationship_index(
emb,
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE,
index_name="relationship_vector_index" # ベクトル検索用のインデックス名
)
先ほどの準備で作成したリレーションシップのインデックス名"relationship_vector_index"を設定してインデックスを取得しています。
参考:
※ 現在「Neo4jVector.from_existing_relationship_index」はハイブリッド検索がサポートされていないため、search_type="hybrid"を設定すると以下のエラーになります。
ValueError: Hybrid search is not supported in combination with relationship vector index
実行結果
- query: フランメとフリーレン
フランメは師匠、フリーレンは弟子の関係
スコア: 0.9605802893638611
フリーレンは師匠、フェルンは弟子の関係
スコア: 0.9435718059539795
アイゼンは師匠、シュタルクは弟子の関係
スコア: 0.9082300662994385
フランメとフリーレンの関係性が一番上に来ており問題なさそうです。
4. テキストからハイブリッド検索(全文検索とベクトル検索)を実行
「Neo4jVector.from_documents」を使うことでグラフではなく、テキストからのハイブリット検索ができます。
コード(全体)
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import Neo4jVector
# Neo4jへの接続情報
NEO4J_URL = ""
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = ""
NEO4J_DATABASE = "neo4j"
# 埋め込みモデルのインスタンスを作成
emb = HuggingFaceEmbeddings(
model_name="intfloat/multilingual-e5-large"
)
# テキストパス
text_path = "./葬送のフリーレン.txt"
# テキストファイルを読み込む
loader = TextLoader(text_path)
documents = loader.load()
# RecursiveCharacterTextSplitterのインスタンスを作成
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=40,
chunk_overlap=10,
)
# ドキュメントを分割
split_documents = text_splitter.split_documents(documents)
# ドキュメントからインデックスを作成して取得
index = Neo4jVector.from_documents(
split_documents,
emb,
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE,
index_name="text_vector_index", # ベクトル検索用のインデックス名
keyword_index_name="text_index", # 全文検索用のインデックス名
search_type='hybrid' # 検索タイプに「ハイブリッド」を設定(デフォルトは「ベクター」)
)
# クエリを設定して検索を実行
query = "フェルン"
docs_with_score = index.similarity_search_with_score(query, k=3)
# 検索結果の表示
for doc, score in docs_with_score:
print(doc.page_content)
print(f"スコア: {score}\n")
上記の内、ポイントとなる箇所を確認します。
コード(ポイントとなる箇所)
# ドキュメントからインデックスを作成して取得
index = Neo4jVector.from_documents(
split_documents,
emb,
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE,
index_name="text_vector_index", # ベクトル検索用のインデックス名
keyword_index_name="text_index", # 全文検索用のインデックス名
search_type='hybrid' # 検索タイプに「ハイブリッド」を設定(デフォルトは「ベクター」)
)
「Neo4jVector.from_documents」はインデックスだけでなく、ドキュメントもノードとしてDBへ保存されます。
参考:
実行結果
query: フェルン
フェルンはフリーレンの弟子
スコア: 1.0
その4年後に魔導書の解読を終えたフリーレンと、一人前の魔法使いに成長したフェルン
スコア: 0.9656757678675649
いに成長したフェルンは、ハイターの最期を看取ったあとに諸国をめぐる旅に出る。
スコア: 0.9642280504540417
「フェルン」に関連したドキュメントが取得できています。
次にドキュメントがどのようにDBに保存されているかを確認してみます。
以下のクエリをneo4jの画面上で実行してみましょう。
// すべてのChunkノードを表示
MATCH (n:Chunk)
RETURN n
ドキュメントはChunkノードとしてDBに保存されています。
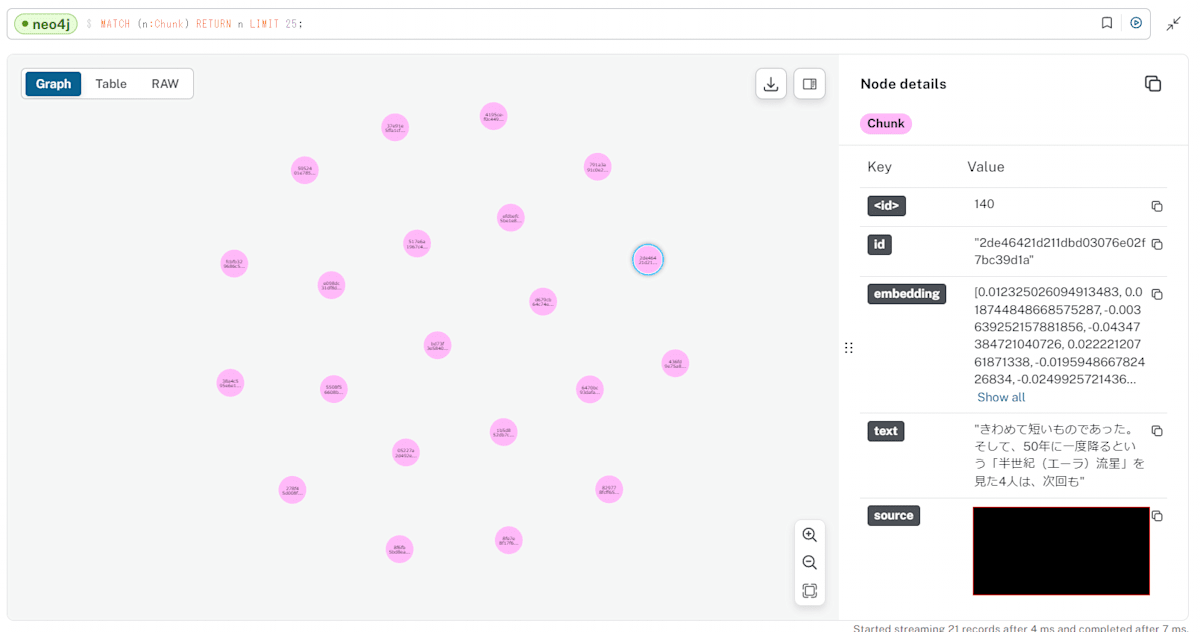
Chunkノードの"text"プロパティに文章、"embedding"プロパティにベクトル化したデータが入っています。
上記のようにノードとインデックスが保存されているため「Neo4jVector.from_documents」を「Neo4jVector.from_existing_graph」(ノード検索用メソッド)に変更しても同じ結果を返すようになります。
- 「Neo4jVector.from_existing_graph」を使用するように変更
# グラフからノード検索用インデックスを取得
index = Neo4jVector.from_existing_graph(
embedding=emb,
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE,
node_label="Chunk", # 検索対象ノード
text_node_properties=["text"], # 検索対象プロパティ
embedding_node_property="embedding", # 埋め込みデータの保存先プロパティ
index_name="text_vector_index", # ベクトル検索用のインデックス名
keyword_index_name="text_index", # 全文検索用のインデックス名
search_type="hybrid" # 検索タイプに「ハイブリッド」を設定(デフォルトは「ベクター」)
)
- 実行結果
text: フェルンはフリーレンの弟子
スコア: 1.0
text: その4年後に魔導書の解読を終えたフリーレンと、一人前の魔法使いに成長したフェルン
スコア: 0.9656757678675649
text: いに成長したフェルンは、ハイターの最期を看取ったあとに諸国をめぐる旅に出る。
スコア: 0.9642280504540417
5. 3つの検索(ノード、リレーションシップ、テキスト)を用いたRAG
上の3つ(ノード、リレーションシップ、テキスト)の検索が試せたので、今度はそれを使って簡単なRAGを行います(今まで行った検索を関数化して、それぞれの検索結果を繋げるだけです)。
※ 7(最後の方)で、検索したノードの周辺情報(関係するノードとリレーションシップ)を用いたRAGを試しています。ノード間の繋がりを意識した実装はそちらをご確認ください。
コード(全体)
import os
from langchain_anthropic import ChatAnthropic
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.prompts.chat import ChatPromptTemplate
from langchain_community.vectorstores import Neo4jVector
# AnthropicのAPIキー
os.environ["ANTHROPIC_API_KEY"] = ""
# Neo4jへの接続情報
NEO4J_URL = ""
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = ""
NEO4J_DATABASE = "neo4j"
# ノード情報からドキュメントを取得
def hybrid_node_search(query):
# グラフからノード検索用インデックスを取得
index = Neo4jVector.from_existing_graph(
embedding=emb,
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE,
node_label="Person", # 検索対象ノード
text_node_properties=["id", "text"], # 検索対象プロパティ
embedding_node_property="embedding", # 埋め込みデータの保存先プロパティ
index_name="vector_index", # ベクトル検索用のインデックス名
keyword_index_name="person_index", # 全文検索用のインデックス名
search_type="hybrid" # 検索タイプに「ハイブリッド」を設定(デフォルトは「ベクター」)
)
# クエリを設定して検索を実行
documents = index.similarity_search(query, k=2)
return documents
# リレーションシップ情報からドキュメントを取得
def graph_relasionship_search(query):
# グラフからリレーションシップ検索用インデックスを取得
index = Neo4jVector.from_existing_relationship_index(
emb,
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE,
index_name="relationship_vector_index" # ベクトル検索用のインデックス名
)
# クエリを設定して検索を実行
documents = index.similarity_search(query, k=2)
return documents
# テキスト情報からドキュメントを取得
def hybrid_text_search(query):
# テキストパス
text_path = "./葬送のフリーレン.txt"
# テキストファイルを読み込む
loader = TextLoader(text_path)
documents = loader.load()
# RecursiveCharacterTextSplitterのインスタンスを作成
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=25,
)
# ドキュメントを分割
split_documents = text_splitter.split_documents(documents)
# ドキュメントからインデックスを作成して取得
index = Neo4jVector.from_documents(
split_documents,
emb,
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE,
index_name="text_vector_index", # ベクトル検索用のインデックス名
keyword_index_name="text_index", # 全文検索用のインデックス名
search_type='hybrid' # 検索タイプに「ハイブリッド」を設定(デフォルトは「ベクター」)
)
# クエリを設定して検索を実行
documents = index.similarity_search(query, k=2)
return documents
# Claude 3.5 Sonnetモデルのインスタンスを作成
llm_sonnet = ChatAnthropic(model_name="claude-3-5-sonnet-20240620")
# 埋め込みモデルのインスタンスを作成
emb = HuggingFaceEmbeddings(
model_name="intfloat/multilingual-e5-large"
)
# 質問文
question = "勇者パーティーメンバーの弟子は?"
# ノード、リレーションシップ、テキストからドキュメントを検索
documents = []
documents.extend(hybrid_node_search(question))
documents.extend(graph_relasionship_search(question))
documents.extend(hybrid_text_search(question))
# llmに送るメッセージを作成
system_message = "あなたは常に日本語で回答します。"
human_message ="""次の「=」で区切られたコンテキストを参照して質問に答えてください。
{context}
質問: {query}
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system_message),
("human", human_message),
]
)
partition = "\n" + "=" * 20 + "\n"
documents_context = partition.join([doc.page_content for doc in documents])
messages = prompt.format_messages(context=documents_context, query=question)
# llmから回答を取得
response = llm_sonnet.invoke(messages)
# 入力メッセージを表示
print("\nメッセージ: ")
for message in messages:
print(message.content)
# 回答を表示
print("回答: ", response.content)
今まで行った検索を繋げているだけなので、処理ごとの説明は省きます。
実行結果
質問文: 勇者パーティーメンバーの弟子は?
メッセージ:
あなたは常に日本語で回答します。
次の「=」で区切られたコンテキストを参照して質問に答えてください。
id: ハイター
text: 僧侶、勇者パーティーのメンバー
====================
id: シュタルク
text: 少年戦士、アイゼンの弟子
====================
フリーレンは師匠、フェルンは弟子の関係
====================
フランメは師匠、フリーレンは弟子の関係
====================
フェルンはフリーレンの弟子
====================
ター、戦士アイゼン、魔法使いフリーレンら勇者パーティー4人は、10年間もの旅路を
質問: 勇者パーティーメンバーの弟子は?
回答: 提供された情報に基づいて、勇者パーティーのメンバーの弟子として明確に示されているのは以下の通りです:
1. フェルン:フリーレンの弟子
2. シュタルク:アイゼンの弟子
フリーレンは勇者パーティーのメンバーであり、彼女の弟子がフェルンであることが明確に述べられています。また、アイゼンも勇者パーティーのメンバーであることが示唆されており、シュタルクが彼の弟子であると記述されています。
他の勇者パーティーメンバーの弟子に関する情報は、提供されたコンテキストには含まれていません。
勇者パーティーメンバーの弟子である「フェルン」と「シュタルク」のどちらも認識できているため問題なさそうです。
6. Cypherクエリをllmで生成 → 結果から回答
次に「GraphCypherQAChain」という(作成済みのグラフに対して)Cypherクエリを作成 → 実行 → 結果から回答までを行えるChainを試してみます。
コード(全体)
import os
from langchain_anthropic import ChatAnthropic
from langchain_community.graphs import Neo4jGraph
from langchain_core.prompts.prompt import PromptTemplate
from langchain_community.chains.graph_qa.cypher import GraphCypherQAChain
# AnthropicのAPIキー
os.environ["ANTHROPIC_API_KEY"] = ""
# Claude 3.5 Sonnetモデルのインスタンスを作成
llm_sonnet = ChatAnthropic(model_name="claude-3-5-sonnet-20240620")
# Neo4jへの接続情報
NEO4J_URL = ""
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = ""
NEO4J_DATABASE = "neo4j"
# Neo4jへの接続情報を設定してgraphインスタンスを作成
graph = Neo4jGraph(
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE
)
# Cypherクエリ用のプロンプトテンプレート
CYPHER_GENERATION_TEMPLATE = """
Task: グラフデータベースに問い合わせるCypher文を生成する。
指示:
schemaで提供されている関係タイプとプロパティのみを使用してください。
提供されていない他の関係タイプやプロパティは使用しないでください。
schema:
{schema}
注意: 回答に説明や謝罪は含めないでください。
Cypher ステートメントを作成すること以外を問うような質問には回答しないでください。
生成された Cypher ステートメント以外のテキストを含めないでください。
例) 以下は、特定の質問に対して生成されたCypher文の例です:
# アイゼンの弟子は?
MATCH (p1:Person)-[:MASTER]->(p2:Person)
WHERE p1.id = 'アイゼン'
RETURN p2.id, p2.text
# ゼーリエの弟子の弟子は?
MATCH (p1:Person)-[:MASTER]->(p2:Person)-[:MASTER]->(p3:Person)
WHERE p1.id = 'ゼーリエ'
RETURN p3.id, p3.text
質問: {question}"""
# プロンプトテンプレートからプロンプトを作成
CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["schema", "question"],
template=CYPHER_GENERATION_TEMPLATE
)
# Cypherクエリを作成 → 実行 → 結果から回答を行うChainを作成
cypher_chain = GraphCypherQAChain.from_llm(
llm_sonnet,
graph=graph,
cypher_prompt=CYPHER_GENERATION_PROMPT, # Cypherクエリ用にプロンプトをセット
verbose=True # 詳細表示を「True」に設定
)
# 質問文を設定してllmから回答を取得
response = cypher_chain.run({"query": "フランメの弟子の弟子は?"})
# 回答を表示
print(response)
上記の内、ポイントとなる箇所を確認します。
コード(ポイントとなる箇所)
Cypherクエリ用のプロンプトテンプレート
CYPHER_GENERATION_TEMPLATE = """
Task: グラフデータベースに問い合わせるCypher文を生成する。
指示:
schemaで提供されている関係タイプとプロパティのみを使用してください。
提供されていない他の関係タイプやプロパティは使用しないでください。
schema:
{schema}
注意: 回答に説明や謝罪は含めないでください。
Cypher ステートメントを作成すること以外を問うような質問には回答しないでください。
生成された Cypher ステートメント以外のテキストを含めないでください。
例) 以下は、特定の質問に対して生成されたCypher文の例です:
# アイゼンの弟子は?
MATCH (p1:Person)-[:MASTER]->(p2:Person)
WHERE p1.id = 'アイゼン'
RETURN p2.id, p2.text
# ゼーリエの弟子の弟子は?
MATCH (p1:Person)-[:MASTER]->(p2:Person)-[:MASTER]->(p3:Person)
WHERE p1.id = 'ゼーリエ'
RETURN p3.id, p3.text
質問: {question}"""
llmがCypherクエリを作成する際に使用するプロンプトです。設定しなくても実行は可能ですが、うまく生成できない場合があります。
schemaに関しては「GraphCypherQAChain」内部でグラフから読み取ったスキーマが設定されます。
プロンプトは以下を参照:
Cypherクエリを作成 → 実行 → 結果から回答を行うChainを作成
cypher_chain = GraphCypherQAChain.from_llm(
llm_sonnet,
graph=graph,
cypher_prompt=CYPHER_GENERATION_PROMPT, # Cypherクエリ用にプロンプトをセット
verbose=True # 詳細表示を「True」に設定
)
verboseを「True」にすることで、生成したCypherクエリとその実行結果を表示することができます(デフォルトは「False」)。
参考:
質問文を設定してllmから回答を取得
response = cypher_chain.run({"query": "フランメの弟子の弟子は?"})
クエリへの変換 & 質問に使用する文章(「フランメの弟子の弟子は?」)を設定しています。
実行結果
質問文: フランメの弟子の弟子は?

「弟子の弟子」という質問にリレーションシップを2回経由することでうまく回答できています。
7. 検索したノードの周辺情報(関係するノードとリレーションシップ)を用いたRAG
最後に(「GraphCypherQAChain」を使わず)検索したノードから、リレーションシップ → ノード → リレーションシップ → ノード と探索して、それらの情報をコンテキストとするようなRAGを試してみます。
コード全体
import os
from langchain_anthropic import ChatAnthropic
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.prompts.chat import ChatPromptTemplate
from langchain_community.graphs import Neo4jGraph
from langchain_community.vectorstores import Neo4jVector
# AnthropicのAPIキー
os.environ["ANTHROPIC_API_KEY"] = ""
# Neo4jへの接続情報
NEO4J_URL = ""
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = ""
NEO4J_DATABASE = "neo4j"
# Neo4jへの接続情報を設定してgraphインスタンスを作成
graph = Neo4jGraph(
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE
)
# ノード情報からドキュメントを取得
def hybrid_node_search(query):
# グラフからノード検索用インデックスを取得
index = Neo4jVector.from_existing_graph(
embedding=emb,
url=NEO4J_URL,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database=NEO4J_DATABASE,
node_label="Person", # 検索対象ノード
text_node_properties=["id", "text"], # 検索対象プロパティ
embedding_node_property="embedding", # 埋め込みデータの保存先プロパティ
index_name="vector_index", # ベクトル検索用のインデックス名
keyword_index_name="person_index", # 全文検索用のインデックス名
search_type="hybrid" # 検索タイプに「ハイブリッド」を設定(デフォルトは「ベクター」)
)
# クエリを設定して検索を実行
documents = index.similarity_search(query, k=2)
return documents
# 検索結果から周辺ノード、リレーションシップの情報を取得
def cypher_node_search(documents):
cypher_response = []
for doc in documents:
id = doc.page_content.split('\n')[1].split(': ')[1].strip()
cypher = f"""
MATCH (p1:Person)-[r1]->(p2:Person)-[r2]->(p3:Person)
WHERE p1.id = '{id}'
RETURN p1.id, p2.id, p3.id,
type(r1) as r1_type, type(r2) as r2_type
"""
cypher_response.append(graph.query(cypher))
return cypher_response
# Claude 3.5 Sonnetモデルのインスタンスを作成
llm_sonnet = ChatAnthropic(model_name="claude-3-5-sonnet-20240620")
# 埋め込みモデルのインスタンスを作成
emb = HuggingFaceEmbeddings(
model_name="intfloat/multilingual-e5-large"
)
# 質問文
question = "フランメの弟子のパーティーメンバーは?"
# リレーションシップからドキュメントを検索
documents = hybrid_node_search(question)
# 検索したドキュメントの周辺情報を取得
cypher_response = cypher_node_search(documents)
# 人物と関係性のコンテキストを作成
person_context = ""
for member in cypher_response:
for person in member:
person_context += f"""
=====================================
"{person['p1.id']}"は"{person['p2.id']}"にとって「{person['r1_type']}」の関係
"{person['p2.id']}"は"{person['p3.id']}"にとって「{person['r2_type']}」の関係
=====================================
"""
# llmに送るメッセージを作成
system_message = "あなたは常に日本語で回答します。"
human_message ="""次の「=」で区切られたコンテキストを参照して質問に答えてください。
{context}
質問: {query}
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system_message),
("human", human_message),
]
)
messages = prompt.format_messages(context=person_context, query=question)
# llmから回答を取得
response = llm_sonnet.invoke(messages)
# 入力メッセージを表示
print("\nメッセージ: ")
for message in messages:
print(message.content)
# 回答を表示
print("回答: ", response.content)
上記の内、ポイントとなる箇所を確認します。
コード(ポイントとなる箇所)
検索結果から周辺ノード、リレーションシップの情報を取得
def cypher_node_search(documents):
cypher_response = []
for doc in documents:
id = doc.page_content.split('\n')[1].split(': ')[1].strip()
cypher = f"""
MATCH (p1:Person)-[r1]->(p2:Person)-[r2]->(p3:Person)
WHERE p1.id = '{id}'
RETURN p1.id, p2.id, p3.id,
type(r1) as r1_type, type(r2) as r2_type
"""
cypher_response.append(graph.query(cypher))
return cypher_response
検索したノードの情報("id"プロパティ)をもとにしてグラフを探索しています。
今回は、検索したノードから続く関係先情報(3つのノードと2つのリレーションシップ)を取得しているだけですが、より高度なグラフ探索を用いることで複雑な質問や関係性を意識した回答が可能になるかと思います。
実行結果
質問文: フランメの弟子のパーティーメンバーは?
メッセージ:
あなたは常に日本語で回答します。
次の「=」で区切られたコンテキストを参照して質問に答えてください。
=====================================
"フランメ"は"フリーレン"にとって「MASTER」の関係
"フリーレン"は"ヒンメル"にとって「PARTY_MEMBER」の関係
=====================================
=====================================
"フランメ"は"フリーレン"にとって「MASTER」の関係
"フリーレン"は"ハイター"にとって「PARTY_MEMBER」の関係
=====================================
=====================================
"フランメ"は"フリーレン"にとって「MASTER」の関係
"フリーレン"は"アイゼン"にとって「PARTY_MEMBER」の関係
=====================================
=====================================
"フランメ"は"フリーレン"にとって「MASTER」の関係
"フリーレン"は"フェルン"にとって「MASTER」の関係
=====================================
質問: フランメの弟子のパーティーメンバーは?
回答: 与えられた情報から、フランメの弟子はフリーレンであることがわかります。そして、フリーレンのパーティーメンバーとして言及されているのは以下の3人です:
1. ヒンメル
2. ハイター
3. アイゼン
したがって、フランメの弟子(フリーレン)のパーティーメンバーは、ヒンメル、ハイター、アイゼンの3人です。
上記、関係先の関係(フランメの弟子の「パーティーメンバー」)がきちんと取得できました。
ノード間の繋がりから情報を取得できるため、単独での検索よりも関係性の流れを考慮することができます(弟子の弟子の弟子の...など)。
おわりに
今回は少し長くなってしまいました・・・。ですが一つ一つの処理は短かいため試すのは容易かと思います。ご興味があればお試しください。
ほとんどの処理は、グラフへのCypherクエリは内部が実装されており、あまり意識しなくても試せるようになっているため使いやすかったです(「3. グラフのリレーションシップ情報からベクトル検索を実行」に関してはCypherクエリを少し扱いましたが・・・)。
また機会があればよろしくお願いします。
参考記事
Discussion