kaggle RSNA2024コンペ 上位解法まとめ
はじめに
MRIから腰椎疾患の重症度分類行うRSNA 2024 Lumbar Spine Degenerative Classification というkaggleコンペが2024/10/9まで開催されていました。
コンペ終了後に公開された上位チームの解法からたくさん学びがあったので、備忘録も兼ねてまとめていきたいと思います。
コンペ概要
- 各患者ごとにMRIから以下の5つの疾患(condition)の、重症度クラス(正常/軽度、中等度、重度)を予測する3クラス分類タスクのコンペでした。
- Spinal Canal Stenosis(SCS: 脊柱管狭窄)
- Left Neural Foraminal Narrowing(L-NFN: 左側神経根管狭窄)
- Right Neural Foraminal Narrowing(R-NFN: 右側神経根管狭窄)
- Left Subarticular Stenosis(L-SS: 左側椎間孔狭窄)
- Right Subarticular Stenosis(R-SS: 右側椎間孔狭窄)
- さらに各疾患は、L1/L2、L2/L3、L3/L4、L4/L5、およびL5/S1の椎間板レベルごとにそれぞれ重症度クラスを予測する必要があります。
- 分類タスクではありますが評価はlog_lossで行われるため、実際には各クラスのスコア(=確率)を予測しなければなりません。つまり、各患者ごとに5疾患x5レベルx3クラス=75個のスコアを予測して提出する必要があります。
- 他にもany_severe_lossなど本コンペ独特のメトリクスがあったりするので、詳細が気になる方は公式ページの"Evaluation"を参照してください。
提供データ
- 各患者(study_id)ごとに複数のMRIが与えられており、各MRIは約10~50枚程度のスライスで構成されています。
- 各MRIはID(series_id)が割り振られており、"Sagittal T2/STIR"、"Sagittal T1"、"Axial T2"のいずれかの方向・モードで撮影されています。この情報はTrain/Testの両方で与えられています。
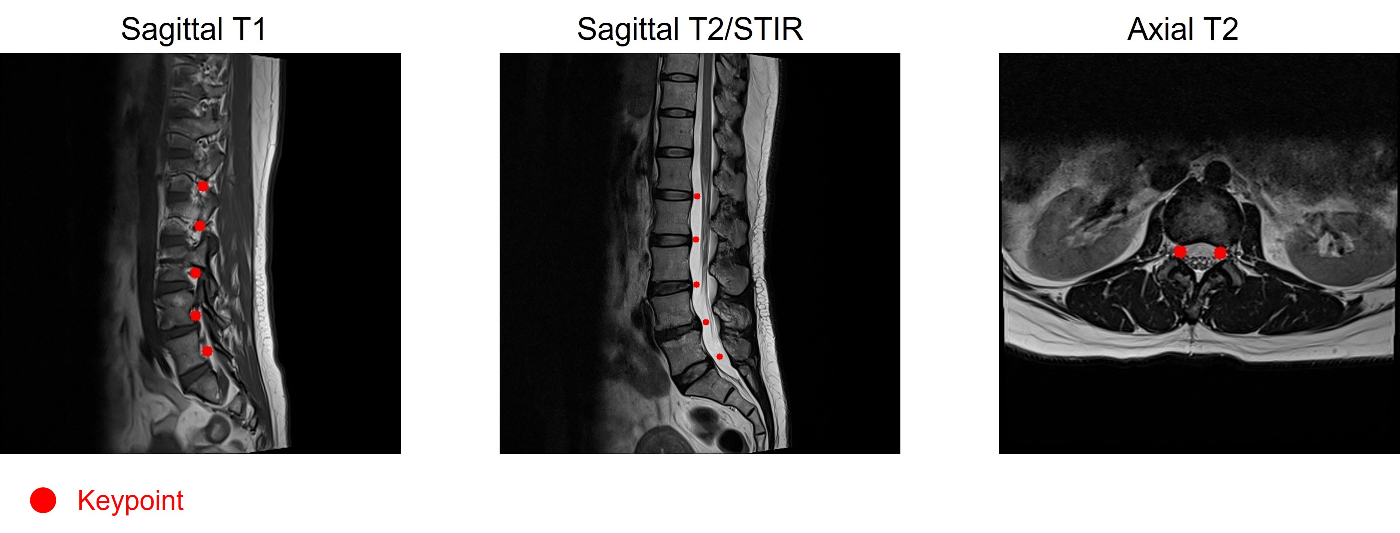
- Trainデータにはアノテーション情報として、予測対象である各condition/各レベルの重症度ラベルがstudy_idごとに与えられているほか、それぞれのconditionの診断に使用したMRIのseries_idとその中のスライスインデックス(instance_number)、画像上のキーポイント(座標)の情報もレベルごとに与えられています。
上位チーム解法まとめ
1. Approach
-
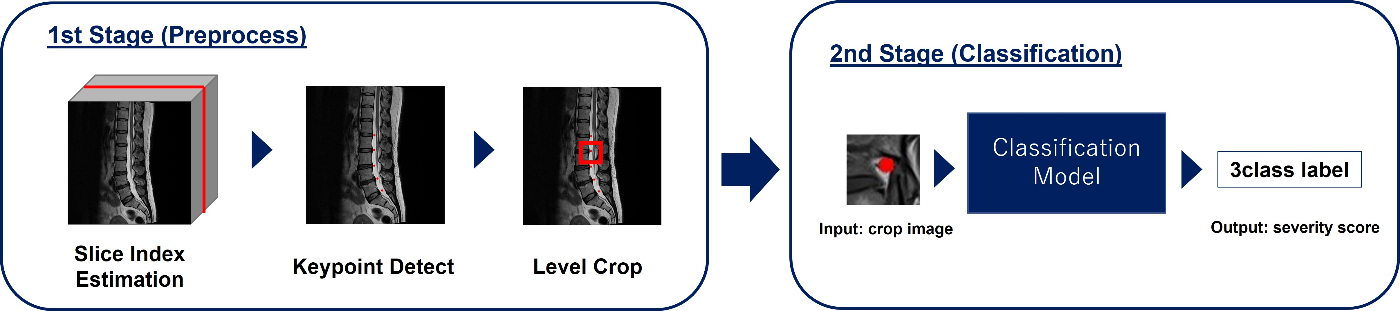
ほぼすべてのチームが2ステージパイプラインを採用していました。(1st, 2nd, 3rd, etc...)
- 1st stageで、スライスインデックス推定、キーポイント推定などを行い、それらに基づいてレベルごとの領域をクロップ
- 2nd stageで、クロップ領域を入力としてクラス分類モデルでレベルごとに重症度スコアを予測
-
レベルごとに領域をクロップしてそれぞれを同等に扱うことで疑似的にデータ数が5倍(NFNとSSは左右も同等に扱うことで5x2=10倍)になるので、データ数があまり十分とは言えないこのコンペでは効果的だったのかと思われます。
-
一方で少数ながらシングルステージパイプラインを採用しているチームもいました。(7th, 8th)
※あくまでクロップしていないという意味なので、"シングルステージ"という表現は若干語弊があるかもです。- シングルステージパイプラインはクロップ領域推定時に発生する誤差の影響が無かったり、画像全体のコンテキストを考慮できるメリットがあるので、難易度は高いですが上手くモデリングすることで2ステージパイプラインと同等以上の精度を出すことができたようです。
- 一例として8thチームは、キーポイント検出(ヒートマップ予測)をサブタスクとして訓練して、得られたヒートマップで重みづけした特徴マップからクラス分類するという方式で、クロップレスながらも着目させたい領域をモデルに上手く注視させていました。(ちゃんとソースコード解読できてないので誤解してる可能性あり)
2. Preprocess(1stステージ処理)
スライスインデックス推定
-
上位チームの多くが、各MRIのスライス群の中から重症度スコア予測に適したスライスインデックス(instance_number)を推定する処理を"スライス推定用モデルを学習"もしくは"ルールベース"いずれかの方法で実現していました。
-
スライス推定用モデルを学習させるアプローチは、各MRIのスライスボリュームから最適なスライスインデックスを出力する2D/3Dモデルを訓練し、レベルごとの最適なスライスインデックスを推定します。(1st, 2nd, etc...)
- 患者によっては背骨が湾曲していてレベルごとに最適なスライスインデックスが異なることがあり、こちらのアプローチではそのようなケースに対応できる強みがあったと思われます。
- スライスインデックスの相対位置を直接的に予測させる回帰タスク、各スライスに対してGTスライスからの距離を予測させる回帰タスク、各スライスがGTかどうかを予測させる分類タスクのいずれかのタスクとして解いていました。
-
ルールベースアプローチは、主にSCSは全体の中心スライス、NFNは中心から一定距離だけ離れているスライスを最適スライスインデックスとして選択しているケースが多かったです。(9th, etc...)
-
一方、そもそもスライスインデックス推定は行っていないチームも一定数ありました。(3rd, etc...)
- こちらのチームは、2ndステージのクラス分類モデルに多くのスライスをまとめて入力することで暗黙的に解決していたようです。(おそらく十分なスライス数を入力して訓練することで、クラス分類モデルが予測に有用なスライスを取捨選択する能力を暗黙的に獲得していったのではないかと予想しています)
キーポイント推定
- 2D/2.5D回帰モデルで直接x,y相対座標を推定しているチームが比較的多かった印象ですが、セグメンテーションモデルでヒートマップを出力することで推定したり(4th, 9th, etc...)、CenterNetを使ったキーポイント検出器で推定しているチーム(3rd)などもいました。
- また、キーポイント推定モデルを独立して準備せずに、スライスインデックスと同時にキーポイントも出力させるモデルを学習させていたチームもありました。(5th)
Axialスライス レベル対応付け
- Axialは各スライスがいずれかのレベルに対応していますが、その対応情報は明示的に与えられていないため、何らかの方法で対応関係を推定する必要がありました。
- 有用なNotebookが公開されていたこともあり、ほとんどのチームがDICOMメタ情報からAxialスライスとSagittalスライスの位置合わせを行い、Sagittalスライスで予測したキーポイントに基づいて各Axialスライスが対応するレベルを推定していました。
- 他の方法で対処した例としては、2ndチームは上記位置合わせの情報を補助的に利用しつつ、各Axialスライスがどのレベルに属するかを予測するモデルを学習させていました。
レベル領域クロップ
-
ほとんどのチームはキーポイント推定で得られた座標を基準に各レベルごとのクロップ範囲を決定していました。
-
キーポイントを使用せず、YOLOやSpineNetV2などの物体検出モデルを使用して直接ROIを出力しているチームもありました。(2nd, 10th)
3. Classification Process(2ndステージ処理)
アーキテクチャ
- 上位チームに共通していた点として、多くのチームが複数スライスを入力とするMILモデルを採用していました。(1st, 2nd, 3rd, etc...)
-
各チーム細かな違いはありますが、大まかには以下のような設計のモデルを採用しているチームが多かった印象です。

- 2Dバックボーンモデルでスライスごとの特徴ベクトルを抽出
- 各スライスの特徴ベクトルをLSTM/GRUに通して時系列情報を反映
- AttentionPoolやGAPで各スライスの特徴ベクトルを集約
- 集約した特徴ベクトルをヘッドに入力して、最終的なクラス分類結果を出力
-
使用している2Dバックボーンモデルは各チーム割とバラバラ(ConvNeXt、EfficientNetv2あたりを使っているチームが若干多い?)でしたが、小さめのモデルを使っていることは共通していました。
-
特徴ベクトルの集約はAttentionPoolを使っているチームが多かったです。
-
- 入力スライス数は、スライスインデックス推定をしていたチームは推定したインデックスを中心に3~5枚程度、スライスインデックス推定をしていないチームは等間隔に10~30枚程度(不足している分はダミーをpadding)にしているケースが多かったです。
- また、一部のチームはch次元に連続するスライスを重ねた画像を通常の画像と同じように扱う2.5Dモデルも採用していました。(2nd, 11th, etc...)
- 書き切れないので個別のアーキテクチャ紹介は割愛しますが、どのチームもユニークなモデリングをしているので、気になる方はディスカッションを巡回することをおすすめします。
マルチview入力
- 基本的にはアノテーションに従って、SCS予測にはSagittal T2、NFN予測にはSagittal T1、SS予測にはAxialを使用しているケースが多かったですが、複数視点の画像を入力とするマルチモーダル的なアーキテクチャを採用しているチームもありました。
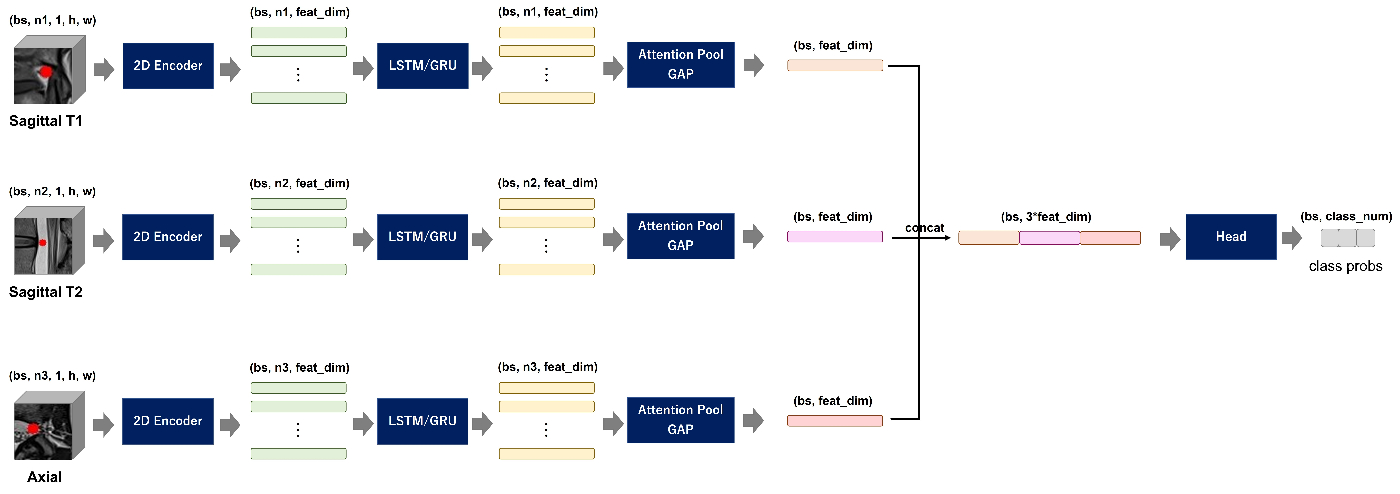
- マルチview入力モデルの実現方式は大きく2つあり、1つはヘッドの直前で特徴ベクトルをconcatして統合する方式、もう1つは2Dバックボーン通過時点の特徴ベクトルを統合する方式です。
-
前者は通常のシングルviewモデルと同等の処理(2Dバックボーン->LSTM/GRU->aggregate)を各視点ごとに独立して実行し、ヘッド入力の直前でconcatして1つの特徴ベクトルに集約させます。(1st, 9th, 10th, etc...)
-
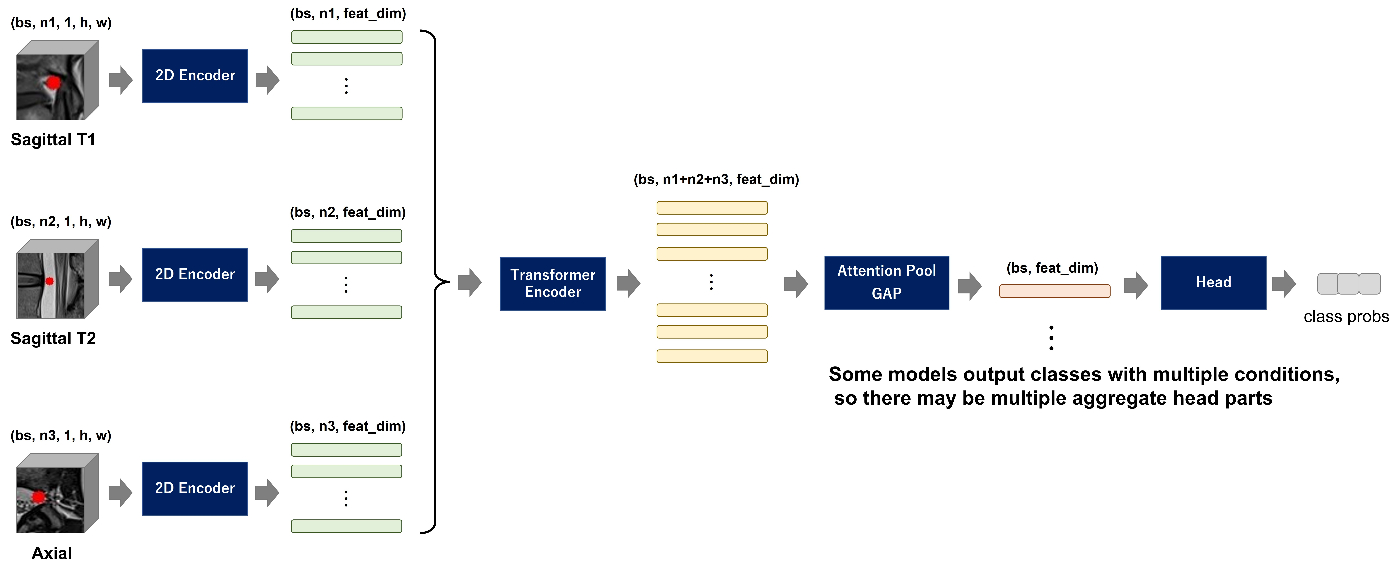
後者は2Dバックボーンの出力時点ですべての視点画像の全スライスの特徴ベクトルをTransformer Encoderに入力して各特徴ベクトル間の関連性を学習させ、それらをAttentionPool/GAPで1つの特徴ベクトルに集約させます。(3rd, 4th, etc...)
-
今回のコンペではどちらが圧倒的に優位ということは無さそうでしたが、異なる情報源から得られた特徴を上手くフュージョンさせる知見は今後類似のタスクを扱う上で役立ちそうと個人的には感じました。
-
Augmentation
- 1stステージのスライスインデックス推定やキーポイント推定で発生する誤差に対してロバストにするため、2ndステージモデル学習時にキーポイント座標やスライスインデックスをランダムにずらすAugmentationが有効でした。(1st, 2nd, 12th, etc...)
- 2ndチームでは、27パターンのクロップ([オリジナルスライスインデックス、±1シフトさせたスライスインデックス] * [オリジナルキーポイント、8方向いずれかにシフトさせたキーポイント]=3 * 9=27)で学習を行い、推論時には同様の27パターンのクロップに対して予測を出力して平均を取るTTAに近い処理をすることで大幅にパフォーマンスが上がったとのことです。
ノイジーデータ除去
-
今回のコンペで提供されていたアノテーションはノイジー(明らかに「正常」であるサンプルに「重症」ラベルが付与されているなど)であり、そのようなデータを取り除くことでスコアを上げることができたそうです。(2nd)
-
ノイジーデータ判定にはアンサンブルoofを用いて、予測結果とGTラベルの差が0.8以上のデータをノイズサンプルとして除外しています。
-
ただ、こちらについては同様の手法でデータ除去して学習したモデルをLate Subしてみましたが、一貫してスコアが下がってしまい、自分の環境では精度向上を再現することができませんでした。
- 自分の再現方法に不備があったか、そもそも除去判定に使用するモデルの性能が十分ではないことなどが原因のような気がしますが、いずれにせよ場合によっては逆効果になることが分かったので別コンペで試す際は慎重に実験・検証すべきと感じました。
まとめ
上位チームのソリューションを一通り読んでみた所感として、どれもユニークである一方で、大まかなパイプライン構成など共通している部分も多かったように感じました。
これは言い換えると、同じ方針を取ったとしても、いかに細部まで丁寧に作り込んだか、細かな工夫をどれだけ積み重ねることができたかが勝負の分かれ目になったということなのかなと思います。
また、各チーム様々な工夫をしていて、自分の中に今まで無かった知見を多く得ることができたので、これをきっかけにコンペや業務で使える手札を増やして活かしていきたいと思います。
Discussion