kaggle IMC2024コンペ 上位解法まとめ
はじめに
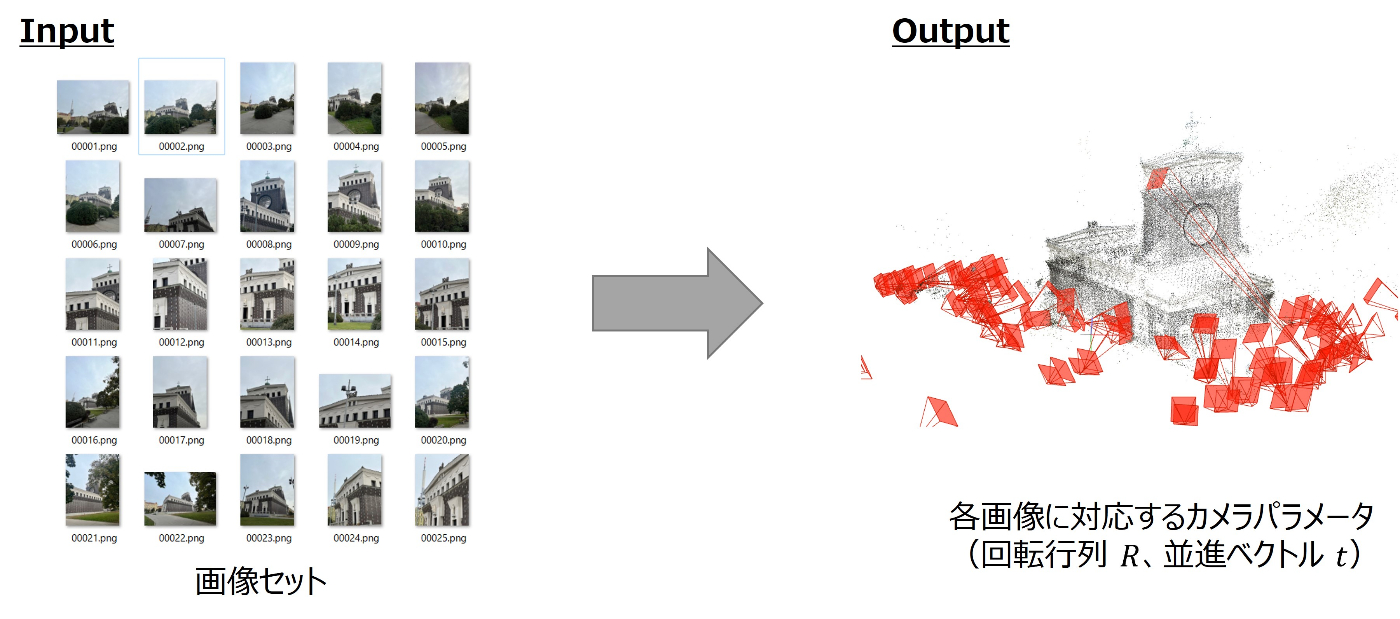
与えられた画像セットからカメラポーズ推定を行うImage Matching Challenge 2024 - Hexathlon というkaggleコンペが2024/6/4まで開催されていました。
コンペ終了後に公開された上位チームの解法からたくさん学びがあったので、備忘録も兼ねてまとめていきたいと思います。
コンペ概要
-
さまざまな角度から撮影された画像セットから、各画像を撮影したカメラの位置と向きを推定してその精度を競うSfMと呼ばれる分野のコンペでした。
-
このコンペはCVPR Workshopの併設コンペで、kaggleプラットフォームでは2022年から毎年開催されています。
- IMC2022では画像ペアのマッチング精度、IMC2023では今回と同様にSfMのカメラ位置推定精度を競うコンペでした。
- それぞれ分かりやすいまとめ記事を公開してくれている方がいるので、興味がある方はそちらを読むことをおすすめします。
Kaggle Image Matching Challenge 2022 まとめ
Kaggle Image Matching Challenge 2023を振り返る
-
今回のコンペはHexathlon(六種競技)の名の通り、一般にカメラ推定が難しいとされる以下の6つの課題のいずれか(もしくは複数)の傾向を持つシーンのカメラポーズを推定することが求められており、昨年よりチャレンジングな内容となっていました。

- simmetories-and-repeats: 前後左右などで同じ見た目の構造をもつオブジェクトを撮影したシーン
- historical-preventation: 異なる時代に撮影されたシーン
- air-to-ground: 地上画像と空撮画像が混合したシーン
- day-night:昼夜それぞれで撮影された明るさが異なるシーン
- nature: 木や生物など自然環境を撮影したシーン
- transparent: 透明なオブジェクトを撮影したシーン
上位チーム解法まとめ
1. Approach
-
基本的にはホストが提供してくれていたベースラインに基づいたパイプラインを全チームが採用していました。

-
ただし、Transparentは公開ベースラインでは上手く推論できないので、多くの上位チームは専用の別パイプラインを構築していました。
-
ちなみにTransparent以外の課題については、ほとんどのチームが対策していないor上手く対策できなかったようです。私見ですがTransparent以外のカテゴリが対策されなかったのは以下の要因が大きいのではないかと考えています。
- historical-preventation、day-night、natureは通常のパイプラインでもそれなりに精度を出せていたので、特に対策する必要が無かった(通常のパイプラインである程度推定できてしまうので対策の効果が薄い)
- air-to-groundは今回の指標では対策がかなり難しかった(メトリクスの特性上、最低でも誤差1m以内で推定しなければならず、地上数十メートルの位置で撮影された画像からカメラポーズを許容範囲内の誤差で推定するのは他と比べても異常に難易度が高く解決が難しい)
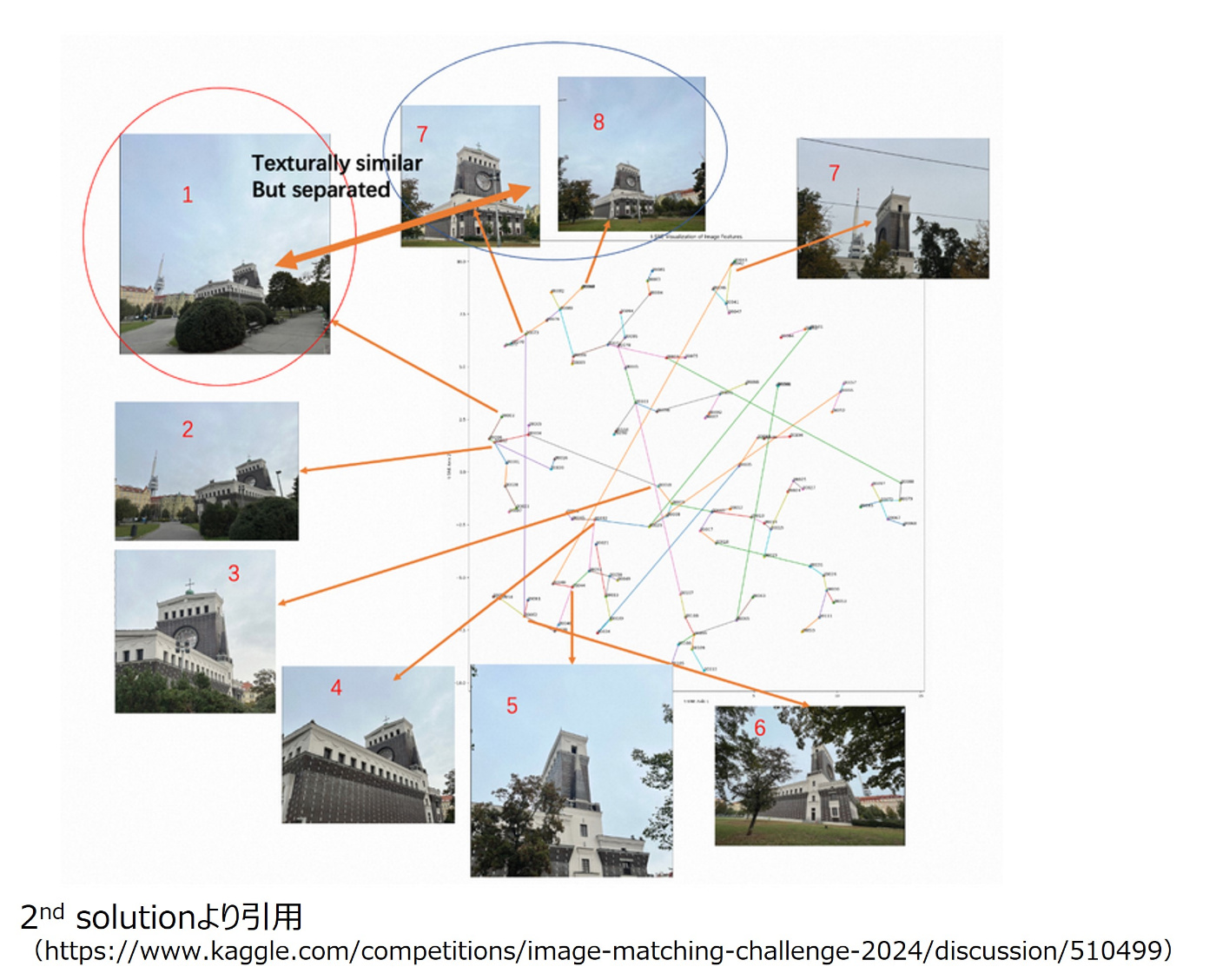
- simmetories-and-repeatsは改善の余地ありだが、先行研究手法を使ってもあまり効果が見られず対策をできたチームがほとんどいなかった(唯一、2ndチームはsymmetoryを考慮したソリューションを実現できていた;後述のMST-aided SfM)
2. 画像ペア選択
Global Feature
- 画像から特徴量(Global Feature)を抽出して類似度の高いペアを選択する方法で、ベースラインが採用していたこともあり、上位チームの多くもこちらの戦略を採用していました。(引用:2nd, 5th, etc...)
- Global Featureはベースラインが使用していたDINOv2を使っているチームが多かったですが、timmの画像分類モデルの中間特徴量をいくつか組み合わせているチームもいました。(引用:5th)
- 2ndチームはSuperPointで点特徴量、DINOv2でパッチ特徴量を抽出し、位置関係に基づいて連結してVLADでより効果的な特徴量を生成するというユニークな方法を考案していました。こちらの手法は従来のNetVLADと比較してPublic+0.017/Private+0.004の改善効果があったとのことです。
Exhausive pair
- 画像セット内で取り得る全てのペアを選択する網羅的(Exhausive)な手法を採用しているチームもいました。(引用:1st、4th)
- こちらの手法は全ての画像間のマッチング結果を反映させることができるので、重要なペアを見逃すリスクを軽減させるメリットがあります。
- 画像総数の2乗に比例してペア数が爆発的に増えていくデメリットはありますが、今回のコンペでは1シーンあたり最大でも100枚までと明言されていたので工夫次第で十分に採用できる手法でした。
3. 特徴点マッチング
マッチングモデル
- モデルについては、特徴点抽出にALIKED、マッチャーにLightGlueを組み合わせたSparseマッチングを使用しているチームがほとんどでした。一部のチームはさらにDedodev2やDISK、SIFTといった特徴点抽出を組み合わせてアンサンブルをしていました。(引用:2nd)
- Denseマッチングは異なるペア間でマッチング点の一貫性が得られないのでcolmapを使ったカメラポーズ推定とは相性が悪いのですが、6thチームは後述のDFSfMによる精緻化と組み合わせることでRoMAというDenseマッチングモデルを採用していました。(引用:6th)
回転補正
- 今回のコンペでもIMC2023と同様に画像の向きを推定して補正する手法が効果的でした。補正パターンは以下の2つのいずれかを採用していました。
- 回転推定モデルを使って各画像ごとに向きを推定する
- ペアごとに画像の片方を0度、90度、180度、270度回転させて、最も一致する回転方向を採用する
- 8thチームは1stステップではペアの片方を回転させながらオリジナル画像に対してマッチングを行い、2ndステップでHomographyMatrixを用いたアフィン変換で向きを合わせるユニークな方法を考案していました。
特徴点密集領域のクロップ
- IMC2022で採用されていた方法と同様に、DBSCANで特徴点クラスタリングし、密集領域を推定してクロップする手法を採用しているチームもいました。(引用:1st、3rd、etc...)
-
1stチームはIMC2022の手法をベースにペアごとではなく画像ごとにクロップ領域を推定する新しい手法を採用していました。
- 画像ごとに一定閾値以上の頻度で他画像とマッチしたキーポイントをDBSCANでクラスタリングして画像ごとの代表領域をクロップしていました。
- 従来の方法では、元画像でマッチングしなかった場合に重要な領域を無視してしまうリスクがありましたが、より多くの画像ペア情報を利用することで重要領域を見逃すリスクを低減できます。
4. カメラポーズ推定
モデル精緻化
- 独自のSfMフレームワークを使って、colmapが生成したモデルをrefine(精緻化)することでスコアを向上させているチームもありました。
-
3rdチームは自身が著者であるVGGSfMというCVPR2024に採択されたSfMフレームワークを使用していました。
- この手法はE2Eで画像セットから(カメラポーズ推定含む)3次元復元ができるフレームワークで、CVも約+0.04の改善が確認できたものの、kaggle環境ではメモリが足りずフルパイプラインを動作させることができなかったそうです。
- そこで、まずsparseマッチング(ALIKED+LG、SP+LG)からcolmapでモデルを生成し、そこで得られたトラックをVGGSfMのfine track predictorモジュールでrefineすることでメモリ制約を回避しつつLB~0.020のスコアを達成したとのことでした。
- 6thチームはIMC2023から引き続き、DFSfMというフレームワークを使用していました。
未登録画像のポーズ推定
- colmapは他画像と十分な関連付けがされていない場合、最終的なモデル(復元結果)に登録されない(もしくは別なモデルに分かれて出力される)画像が発生します。ベースラインでは最も登録数の多いモデルを取得し、そのモデルで推定できたカメラポーズのみを最終出力としていましたが、いくつかのチームは未登録画像と登録画像の変換行列を計算することで未登録画像数を削減してスコアを向上させていました。
- 1stチームは複数のモデル出力を許容するようにcolmapのパラメータを調整し、ホーンアライメントを使ってモデル間の変換行列を推定して、最適なモデルに投影させることで出来るだけ多くの画像を登録していました。
- 3rdチームはcolmapで未登録になった各画像に対して、最もマッチング数の多い登録画像5枚を選択し、6枚の画像セットに対して前述のVGGSfMでカメラポーズを推定し、登録画像5枚の中心に対するアライメント変換行列を計算することで未登録画像のポーズ推定を行っていました。
MST-aided SfM
-
2ndチームが考案した2段階でSfMをすることでsymmetoryも考慮しつつ精密なカメラポーズを推定する方法です。(若干、ペア選択に関するトピックも含まれますが、こちらでまとめて説明します)
-
1stステージでは、頂点が画像、エッジの重みが類似度のグラフを構築し、MST(最小全域木)を計算し、MSTで関連づけられたペアに対してマッチングを行い、colmapで粗いモデルを作成します。
-
2ndステージでは、1stステージで得られたカメラポーズの情報を活用して全データの関連付けを行い、ペアを増やした上で再度colamapを実行し、精密なモデルを作成します。
-
- 1stステージで不正確なマッチングを抑制しつつ、2ndステージでその利点を保ちつつデータを増やすことでPublicで+0.015/Privateで+0.018の改善を実現できたそうです。
5. Transprent対策
Direct Image Pose estimation(DIP)
-
今回のTransparentデータは下図のようにカメラが物体を囲むようなシーンになっていたので、画像の順序を推定して直接カメラポーズを計算するアプローチが有効で、上位の多くがこのアプローチで対策をしていました。(引用:1st、2nd、6th)

-
順序推定は何かしらの方法で画像間の類似度を定義し、その値をエッジの重みとしてTSP(巡回セールスマン問題)に帰着させて実現していました。
-
ちなみにtestデータがtrainデータと同じようなポーズをしていると明言されていたわけではないのでリスキーなアプローチに思えるかもしれませんが、こちらの方法を採用したチームはセグメンテーションで前景抽出して形状がほぼ一致しているか確認したり、データの引用元と思われる論文を見つけることで、ある程度確信を持ってこちらの手法を採用していました。(引用:1st、6th)
マッチングベースアプローチ
- 直接カメラポーズを計算するのではなく、(工夫を行った上で)特徴点マッチングをしてcolmapでポーズ推定をするアプローチを採用しているチームもありました。(引用:4th、5th)
- 4thチームはDINOv2 segmentorで前景抽出し、1024x1024のグリッドに区切ってオリジナルサイズで特徴点抽出をして対応するグリッド間でマッチングを行うことでスコアを上げていました。こちらのチームはペア推定などは特に行っていなかったようです。(私見ですが、おそらく対応するグリッド同士でマッチングさせたことで連続する画像間のマッチングが強調されて上手くカメラポーズ推定ができたのではないかと思います)
- 5thチームはMobileSAMで前景抽出して、マッチング数をベースに前後画像ペア推定をすることでスコアを上げていました。
- 今回のようなケースでは理論値に近い値を出せるのでDIPアプローチの方に軍配が上がりましたが、DIPの前提条件が成り立たないケースではこちらのマッチングベースアプローチの方が有効だったのかなと思います。
まとめ
今回のコンペはホストから明示的に課題が示されていたので何をしなければならないかは比較的明確でしたが、どの課題も非常にチャレンジングでどれから優先的に着手していくかの見極めが非常に大事だったように思います。今回の場合であればTransparentをいかに対策するかが一番のキーになっていましたが、これに気づくためには与えられたデータをよく観察したり、論文をサーベイして対策の有効度を判断するといったように、やはりデータをよく見て向き合うことが重要であると再認識しました。
また、例年のIMCと同様に基本的に全員が同じ公開モデルを使用し、同じベースラインからスタートするので、データをよく見て改善アイデアをひねり出せるかがやはり重要だったように思います。
独特な問題設定のコンペであるものの、ソリューションの中には一般のコンペにも流用できそうな工夫もたくさんあったので、これをきっかけにこれからのコンペや業務に活かしていければと思います。
Discussion