#30DaysOfKaggle
#Day1 TitanicでKaggleデビュー
やったこと (3h)
- How to Get Started with Kaggle’s Titanic Competition | Kaggle を視聴した
- Titanic Tutorial でsubmitした
- ランクが Novice -> Contributor になった
自分で調べたことや疑問をメモ
- Kaggle APIを使うとデータセットのダウンロード、課題の提出がJupyternotebook上でできて便利
-
!unzip titanic.zipで解凍できる。Jupyternotebookでbashコマンド使いたいときは頭に!をつける - Pandasとはデータフレーム形式でデータを色々加工できるライブラリ、主にデータの前処理で使う
- Titanicの目的は予測を通じて何が重要なfactorだったかを明らかにすること。データから現実に起こったことを理解すること
- 二つのDataFrameを扱うとき、各行のPassengerIdが一致していることが明らかなときはいちいちPassengerIdつけずに分離・結合するのがラク
- ランダムフォレストってなんぞ?
- タイタニックでもっと色々やりたいな。LeaderboardみたらScore 1.00がたくさんいたw
- チュートリアルやっただけなのでKaggleの奥深さはまだ全く理解していない
学習方法の振り返り
- もともと分厚い本を一冊やろうと思っていたけど、こまめにインプット/アウトプットしないと身につかなそうだから、Kaggleドリブンにやっていったほうが良さそう
- 次回はKaggleのIntro to Machine Learningをやろうと思う
- 練習コンペに1-2つsubmitしたら、早速コンペに出てみたい
#Day2 Titanicを時間かけて取り組んでみる
やったこと (5h)
- Titanicに自力で取り組んでみる
- Python Tutorials Lesson 1 ~ Lesson 4
自分で調べたことや疑問をメモ
- EDAは何をしたら良いのかわからなかった
- Name, Ticket, Cabin, Ageを上手く前処理できなかった。やりたいことはあったけどコードがわからなかったので、プログラミング力不足
- 重回帰は予測値が0,1じゃなかったんだけど、Titanicには使えないのか?
- ランダムフォレストの使い方を知らなくて、ロジスティック回帰でやるしか方法がなかった
学習方法の振り返り
- PythonやPandasなどを使いこなせるようになるべし
- 各モデルの理論と実装を学ぶべし
#Day3 Python Tutorials
やったこと (3h)
- Python Tutorials Lesson 5 ~ Lesson 7
自分で調べたことや疑問をメモ
- 今までフィーリングで触ってたPythonを体系立てて学ぶことができた
- Python Tutorialsでは原始的なことしかやってないけど、これが機械学習ができるまでになると思うとすごいなと思う
- Numpyなどの外部ライブラリの見慣れない型はtype()やdir()で確認できる
- 外部ライブラリの型で四則演算を行うと直感に反した挙動をすることが往々にしてある
- for文はスコープを作らない
学習方法の振り返り
- 今日、Kaggle Masterのu++さんのツイートで知ったのだけど、なんと先月8月にKaggle公式が30 days of ML という名の基礎講座をやってたらしい。
- カリキュラムは、前半Day1~14がKaggle Courses、後半Day15~Day30がKaggle Competition
- [Courses] Python course (Day1~Day7)
- [Courses] Intro to ML (Day8~Day11)
- [Courses] Intermediate ML (Day12~14)
- [Competition] (その名も)30 Days of ML(Day15~30) ※講座参加者しか問題を閲覧できない
- Day15~30の使い方としては、「勉強しつつ1日1提出以上行うことを目標にする」とのこと
- 参加は逃してしまったけど、この講座のカリキュラムを真似しようと思う
- 目指せ、5ヶ月後(2021年1月末)までにKaggle Expert
#Day4 Python Tutorial
やったこと (1h)
- Python Tutorial 復習
自分で調べたことや疑問をメモ
- 時間が取れなかったので復習だけ
学習方法の振り返り
#Day5 Pandas Tutorial
やったこと (2h)
- Pandas Tutorial #1
- Zennで記事公開
自分で調べたことや疑問をメモ
学習方法の振り返り
- 時間が取れなかったが、DataFrameについて理解が深まったし、Zennで記事を公開できたので嬉しい。
#Day6 Pandas Tutorial
やったこと (1h)
- Pandas Tutorial #1
自分で調べたことや疑問をメモ
- 昨日の続きをやった。Zennの記事にまとめたことで学びが深まった。
学習方法の振り返り
- 土日月とあまり時間が取れなかった。明日からは平常運転で頑張っていきたい。
#Day7 Pandas Tutorial
やったこと (3h)
- Pandas Tutorial #2, 3
自分で調べたことや疑問をメモ
-
ilocはindex(position)-based selectionで、locはlabel-based selection -
iloc[0, 10]が0,..,9を取り出すのに対し、loc[0, 10]は0,...,10を取り出すのはなぜか。それは、locはloc['Apples', 'Potatoes']など文字列のラベルの場合があるから、Potatoesの一つ前が何かわからなかったりして扱いにくい。"gotcha!" - ilocとlocを使うときはrow-first (, column-second).
reviews[cols][0:100] # Native Python, column-first, row-second
reviews.loc[0:99, cols] # Indexing in Pandas, row-first, column-second
- mapはある列(Series)に関数を適用できる
- applyはDataFrameを行ごとに関数を適用できる
学習方法の振り返り
- そろそろKaggleコンペやりたいな。。
#Day8 Pandas Tutorial
やったこと (3h)
- Pandas Tutorial #1~3 復習
- Pandas Tutorial #4~6
- Titanic 1submit
自分で調べたことや疑問をメモ
- 生Pythonではドットアクセス
reviews.countryができないが、Pandasではできる。おそらくPandasはreviews.country => reviews['country']に変換するmixinみたいなのが作ってあるんだと思う。 - bracket vs dot で調べると案外bracketが優勢だったので、自分も変わらずbracketでいこうと思う。
- A.join(B)するときは、A, Bそれぞれにset_indexで共通のキーを登録してあげる。multi-index可。
- 前処理頑張ったらTitanicのスコアが微増した!0.75598→0.76076
学習方法の振り返り
- 前処理で自在に操れるのは楽しくなってきたけど、まだまだ雰囲気でコード書いてる部分があるので、もっとトレーニングしたい。
- とにかくNotebookが汚い
- 元データを上書きしてしまっていて必要なときに困る
- trainの前処理が終わった後にtestでも同じことやるからNotebookがむちゃくちゃになる
- →KaggleのCodeで上手い人のNotebookが見れる!!→模写してみる
- モデル構築に至っては何をやっているのか全く理解できないので、とてもつまらない!
- 単純に憶えることが多すぎるんよな...
#Day9
やったこと (3h)
- Pandas Tutorial #4~6 復習
- Titanic 1submit
自分で調べたことや疑問をメモ
- Groupby.aggのaggはaggregate(集計)の略
- 前処理をするときは、やろうとしていることが破壊的(それ自身に変更が適用される)かどうかを把握することが重要
- Titanic 1submit
- 0.76076 → 0.76076 変わらなかった... CabinBoolを導入したんだけどな
学習方法の振り返り
- 昨日Notebookが汚なかったのはプログラミング(Pandas)の練習不足だと思ったので、再度Titanicを1submit。今回は手順を整理しながらやったので、きれいにできた。基本的な前処理はできるようになったと思う。
- 予定より2days遅れてるけど、明日からいよいよIntro to MLをやっていく
#Day10 Intro to ML
やったこと (3h)
- Intro to ML #1
自分で調べたことや疑問をメモ
- 決定木は分類して分類ごとの平均値を出す
学習方法の振り返り
#Day11 Intro to ML
やったこと (3h)
- Intro to ML #2, 3
自分で調べたことや疑問をメモ
- データをモデルに突っ込むだけの作業
学習方法の振り返り
#Day12, 13 Intro to ML
やったこと (3h)
- Intro to ML #4, 5, 6, 7, Bonus
- 4submitできた!
自分で調べたことや疑問をメモ
- validation dataはモデルの評価をするためのものなので、最善のモデルが見つかったらvalidation dataの役目は終わるので、all dataを使って学習して良い
- モデルを改善する最も良い方法は、特徴量を増やすこと
- とりあえずnot-nullかつInt/float型のものをfeaturesに突っ込んだらスコアが約21000→17860に大幅改善された!
- AutoMLすげえな。AutoML走らせるだけでTOP50%に入れた。TOP10%以内で銅メダルだ
学習方法の振り返り
- 今まで7回ぐらいsubmitしてるけど、どれもAutoMLを超えていないと思う。AutoMLでできるレベル=スタートラインだとして、そこからどれだけスコアを上げていけるかがKaggleの奥深さなのかな〜と。まずは上位の人のNotebookを読んで銅メダルレベルのsubmitを一回やってみたい。
#Day14 Intermediate Machine Learning
やったこと (3h)
- Intermediate Machine Learning #1, 2, 3
- 2submitできた!
自分で調べたことや疑問をメモ
- 欠損値の三つのアプローチ
- 落とす
- 埋める
- 埋める&
_was_missingカラムを追加する- カラム追加後のXとX_testが一致しないと使えないので注意
- カテゴリカルデータの三つのアプローチ
- 落とす
- 順序変数化(Ordinal Encoding)
- 順序が意味をなすときに有効
- 名目変数化(One-Hot Encoding)
- cardinalityが高い(値の種類が多い)と有効性が下がる(目安15以内)
- データを入れるとmaeを返す関数を作っておくと前処理のアプローチごとのスコア比較が楽にできる
- 一般に、比較したい部分以外は関数で共通化するとよい
学習方法の振り返り
- One-Hot Encodingは手順が複雑&実装が難しくて写経するだけになってしまった
#Day15, 16, 17 Intermediate Machine Learning
やったこと (3h)
- Intermediate Machine Learning #4, 5, 6, 7
- #4 Pipelines
- #5 Cross-Validation
- #6 XGBoost
- #7 Data Leakage
- submit counts: 1
自分で調べたことや疑問をメモ
- Pipelineは神、1行でpreprocessとmodelを書ける
- ColumnTransformerはカラムごとに異なる変換を適用できる。
transformers=[(名前, transformer, カラムのリスト),(名前, transformer, カラムのリスト)]- transformersには単一のtransformerだけでなく、複数の直列変換をまとめたPipelineも渡すことができる
- Hold-Out法, Cross-Validation法の使い分け
- 処理時間が短いときはCross-Validation法を試してみる
- 各foldのスコアが大差ないときはHold-Out法で十分だろう
- Data Leakage
- Target Leakage:Target valueが確定した後に更新されるデータを学習に用いることで学習時にだけ高スコアを叩き出してしまう現象。防止するためにはEDAを怠らないこと。また、特徴量エンジニアリングをするときはその計算式にTarget valueを含まないように注意すること(要するにTrain Dataしか使わないこと)。
- 例えば家のサイズ(Size)は売れた(SalePrice)後に変わらないので問題ない
- Train-Test Contamination:うっかりValidation用のデータをモデルのfittingに使ってしまうこと。Notebookがごちゃごちゃしてるときは特に注意。Pipelineは防止に繋がる。
- Target Leakage:Target valueが確定した後に更新されるデータを学習に用いることで学習時にだけ高スコアを叩き出してしまう現象。防止するためにはEDAを怠らないこと。また、特徴量エンジニアリングをするときはその計算式にTarget valueを含まないように注意すること(要するにTrain Dataしか使わないこと)。
学習方法の振り返り
- cross_val_scoreの評価基準とかRandomForestRegressorの引数とかオプションがたくさんあるけど、そもそも「こういうときは○○をするといい」っていう引き出しがないとオプションを使いこなせない。その引き出しを増やすためには統計や機械学習の理論的な知識が必要になってくるんだろうな。
- 一方でGridSearchっていうハイパラ最適化のライブラリがあるらしい。総当り的に計算しまくるやつ
- いつか論文読んでこういうふうにまとめるやつしたいな。最終ゴールはXGBoostの論文を読んで自分で実装できるようになりたい。
元の論文は英語で13ページだから、根気出せばできるかも?→Qiitaの解説記事ですら理解不能でった。 - とりあえず基礎的な勉強は終わったのでコンペに参加するぞ!
#Day18 House Prices
やったこと (3h)
- まずはここまでで学んだことを一通り使ってみる
- House Prices 2 submit
- XGBoost
- Score: 0.14729
- XGBoost+Pipeline
- Score: 0.13725
- XGBoost
試したいこと
- 特徴量エンジニアリング
- SimpleImputerの引数を変えてみる
- 一部OrdinalEncodingも検討してみる
- 複数モデル
- DicisionTree, RandomForest, XGBoost, LinearRegression
- それぞれスコア比較する
- +クロスバリデーションでscoreを出してみる
- ハイパラチューニング
- XGBoost
- n_estimators
- learning_rate
- early_stopping_rounds=5
- XGBoost
自分で調べたことや疑問をメモ
学習方法の振り返り
#Day19 Titanic Data Science Solutions 写経
やったこと (6h)
- submit: 3
- 復習を兼ねてTitanicで1submitしてみる
- gender_submission.csvが0.76555もある衝撃
- Titanicのメダル級のNotebookを一つ模写してみる
- EDAだけで3時間かかった。脳死してないのでやってて苦痛じゃなかった。
自分で調べたことや疑問をメモ
- XGBRegressor使ってベストスコア叩き出そうと思ったのに出力形式が0,1ちゃうんかい!ってなった。各モデルの予測の出力形式0,1なのか0.89とかなのかがわからない。
- pipelineは神。ただ、細かい前処理をするにはどうすればいいんだろう?
学習方法の振り返り
- 知ってる手法を闇雲に試してはいるけど、脳死でやってるので次何したらいいかわからない状態。今のスキルセットを自己評価するとこんな感じ。
- 実装力
- この半月で基礎は身につけた。ゆっくりやればだいたいのことはできる。ただ、できるけど面倒な実装も多々あるので、「こうするとスコアが上がるはずだ!」っていう仮説がないと実装する気が起きない。笑
- 手法の引き出し
- 名前知ってるレベル。どういうときに使うのが良いのかはわからない。
- データ分析
- 皆無。EDA?おいしいの?レベル。
- 実装力
#Day20 Titanic Data Science Solutions 写経
やったこと
- Titanic写経
- submit: 0
自分で調べたことや疑問をメモ
- Ageは年齢層ごとに生存率が高くなったり低くなったりするので、序数的ニューメリカル変数として扱うよりもカテゴリカル変数として扱うほうが適切
- クロス集計(pd.crosstab)は相関を探索するのに便利
学習方法の振り返り
#Day21 Titanic Data Science Solutions 写経
やったこと
- Titanic - Titanic Data Science Solutions 写経
- submit: 2
- 3日(実質7h)かけてようやくTitanic Data Science Solutionsを写経し終わった。
- Titanic Data Science Solutions を写経したやつ
自分で調べたことや疑問をメモ
- ラベルエンコーディングするときは
train_df['Sex'].map({'female': 1, 'male': 0})でいける - FareをFareBandにするにはqcutを使う
- 恥ずかしながら「機械学習といっても結局相関から導くなら相関係数でよくない?」と思っていたけど、よく考えたら相関係数が有効なのはデータが序数的変数のときだけだった。例えば年齢層が上がると生存率が単調増加するわけではないので相関係数出しても"相関なし"みたいに見えてしまう。
- LogisticRegressionは各特徴量の相関度合いが見れるので、前段の特徴量エンジニアリングの妥当性を検証するのにうってつけ。
学習方法の振り返り
- スコアは予定通り低かったけど、脳死せずにデータサイエンスっぽいアプローチを掴めたのは大きい。
- 流れ:EDAでざっくり仮説立てて、特徴量間の相関を中心としたデーテ分析からさらに仮説を磨いて、仮説と決定事項から特徴量エンジニアリングを行い、ロジスティック回帰で妥当性を検証する。
- 次は、ハイスコアなNotebookを写経する。
#Day22 House Prices 写経
やったこと (8h / 4sub)
-
Stacked Regressions : Top 4% on LeaderBoard 写経
- このNotebookのテーマは「特徴量エンジニアリング」と「Stacking」
- #Day18時点: 0.13725
- Pipelineを使ったシンプルな機械学習
- notebook22b2c79d05
- +特徴量エンジニアリング: 0.13725 -> 0.13168
- Quality系を前処理するときにLabel Encodingの代わりにOrdinal Encodingにするアイデアを加えたことで精度が上がった
- +ハイパラ: 0.13168 -> 0.12671
- +シンプルStacking: 0.12671 -> 0.12090
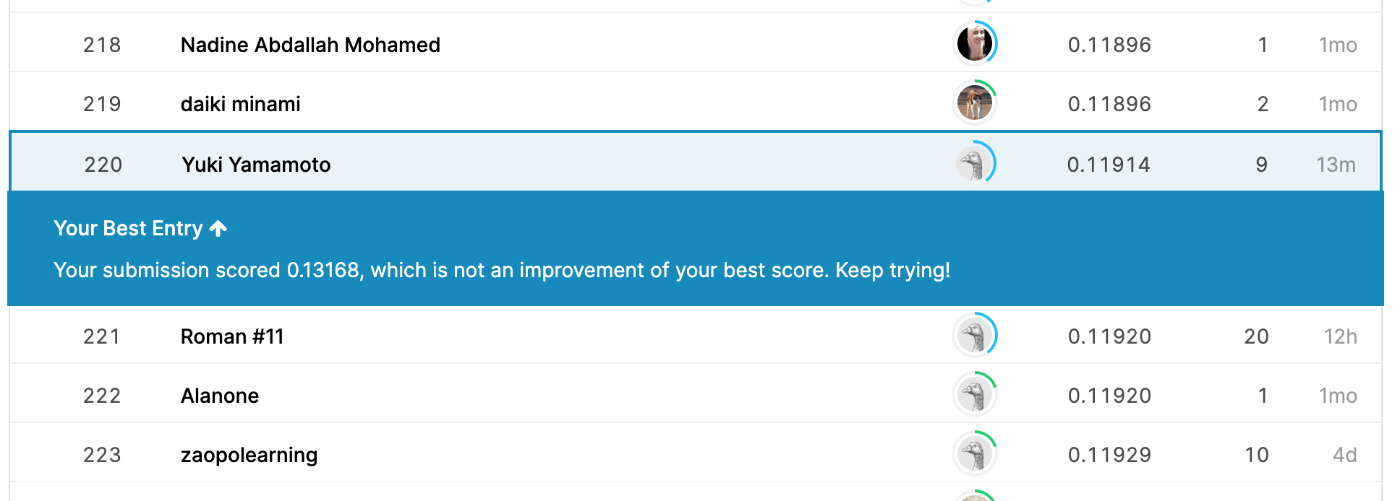
- +Stacking: 0.12090 -> 0.11914 (TOP5%以内)
自分で調べたことや疑問をメモ
- TitanicはTestデータとTrain/Validデータの分布が乖離しているらしいので、いくらやっても決定木が一番ハイスコア(0.77990)らしい。
- GroupByの各グループはSeries型になっている
- 1カラムずつ欠損値を埋めては残りをチェックする作業はゲーム感覚で楽しめた
- Int型のカテゴリカル変数もラベルエンコーディングしてもいい
- 重要な要素は新たに特徴量として作り出してもいい 例. 各フロアの面積から「全体の面積」を作る
- Stackingというアンサンブル手法でスコアを上げることができたけど、どういう手法なのかは理解できなかった。
学習方法の振り返りや心の変化
- 「現状はカテゴリカルデータでuniqueが多いやつをDropしてしまっているので、それらをDropせずに前処理すればスコアは上がるんだろうけど、良い仮説がないので手を動かすのが億劫」という状態。なぜこの前処理をするとロジスティック回帰に優しくなるのか?などを理解した上でやりたい。
- スコアが誰とも被ってなかったのでようやく自分なりの知恵が出せた感があって嬉しいな。。
- 今まで学んだ4つのことを胸に、Playgroundコンペに参加してみようかな!
- ベースラインを設定する
- EDA (欠損値とデータ型を見るだけ)
- シンプルな前処理+シンプルなモデル = シンプルなパイプライン
- データ分析と特徴量エンジニアリングを頑張る(on a simple model)
- モデルごとにハイパラチューニングを頑張る
- 複数モデルを評価するのを頑張る
- アンサンブルを頑張る
- ベースラインを設定する
残りの#Day23~Day30の学習計画
やりたいことリスト
①練習用コンペに2つ参加する
-
PUBG Finish Placement Prediction(Day23, Day24, Day25, Day26, Day27, Day28)
- 選定理由:PUBGが好きだから
-
Tabular Playground Series - Sep 2021(Day29, Day30)
- 選定理由:Kaggle公式の推奨入門コンペだから
②Kaggle Coursesをやる
- Feature Engineering 5hrs.(Day23, Day24, Day25)
- Data Cleaning 4hrs.(Day26, Day27, Day28)
- Data Visualization 4hrs.(余裕があれば)
#Day23 PUBG Finish Placement Prediction
やったこと
- PUBG Finish Placement Prediction
- submit: 1
- ベースラインとなるシンプルなNotebookを提出した
- 計算に1時間半かかったのにファイル名の指定があって提出できなかった泣
- LightGBにしたらスコアはほぼ一緒で3分に短縮できた。0.05659 (840位/1500位)
自分で調べたことや疑問をメモ
- Classifierは"分類"なので0,1などが予測値、Regressionは"回帰"なので0.425などが予測値。コンペの評価基準をに合わせて使い分ける。ただしLogisticRegressionは分類しかできないので注意。
- 400万行x27列のデータをRandomForestに入れたら遅すぎてヤバいことしてないか不安になった。実行時間の目安が知りたい。それに、n_jobs=-1(最大)にしてたけど、調べによると我がMacbook Airのコア数は2らしい笑
- 相関高いやつだけ特徴量に入れてみたけどそんなにスコア変わらなかった。
学習方法の振り返りや心の変化
- PUBGが好きっていうだけでこんなにも違うのか!永遠にデータ見てられるし、仮説もありすぎて全部試したいけどそうしたら1ヶ月はかかるなと思った。
#Day24, 25, 26
やったこと(8h)
- PUBG Finish Placement Prediction
- 他の人のNotebook参考に特徴量エンジニアリングを頑張った
自分で調べたことや疑問をメモ
- 特徴量エンジニアリングの効果はLinearRegressionで十分検証できる
- train_test_splitと前処理、どちらを先にするのが適切なのか?
- 結論:前処理→train_test_split
- 自力でコンペに取り組むといつもNotebookがカオスになる。。
- 混乱しないように1notebook-1pipelineになるように分割する
- どうすれば特徴量エンジニアリングで実験するに値する仮説を多く出せるか?
- どうすればその仮説を複数同時に実験できるか?
学習方法の振り返りや心の変化
- 実装力については体系的に学べているけど、Kaggleで勝つための方法論については体系的学べてない
#Day28
やったこと
- PUBG Finish Placement Prediction
- 他の人のNotebook参考に特徴量エンジニアリングを頑張った
自分で調べたことや疑問をメモ
- trainを複製するときなどは関数化してローカル変数にすると変数名が反乱しなくて済む
- Fittingするとき、要らないカラムをdropするのではなく、使いたいカラムを
cols_to_fit = [...]として管理するとtargetがないtestデータにも使えたりして便利。 - 有望な特徴量を全部盛り込もうとしたらメモリオーバーで断念。。
- メモリを食っている変数を探し出すコマンドの記事
学習方法の振り返りや心の変化
- KaggleでNotebookを公開したら1いいねもらえた。。嬉しい。。
#Day29
やったこと
- Tabular Playground Series - Sep 2021 の概要を読んだ
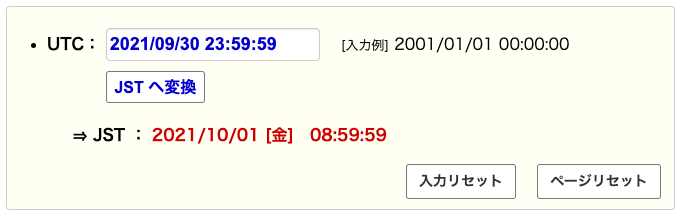
- 日本時間の〆切
自分で調べたことや疑問をメモ
学習方法の振り返りや心の変化
#Day30
やったこと
- Tabular Playground Series - Sep 2021
- 今日頑張ろうと思ったらうっかりsubmit数を超過してしまってもう〆切まで何もできない。。。笑 つらい

自分で調べたことや疑問をメモ
学習方法の振り返りや心の変化
- Tabular Playground Series - Sep 2021 は不完全燃焼で終わった。。
# 30 60DaysOfKaggle
9/1~9/30に続けた#30DaysOfKaggleですが、#60DaysOfKaggleとして10月も継続します!
10月の目標
コンペ
-
Google Brain - Ventilator Pressure Prediction
- 選定理由:
tabular dataActiveかつ11/4〆切のコンペだから - 取り組み方:1submit/day
- 選定理由:
-
Tabular Playground Series - Oct 2021
- 選定理由:
tabular dataActivePlaygroundかつ10/31〆切のコンペだから - 取り組み方:主にCoursesで学んだことをアウトプットする場として適宜活用する。
- 選定理由:
学習内容
- Feature Engineering 5hrs.(Day33, Day34, Day35)
- Data Cleaning 4hrs.(Day36, Day37, Day38)
- Data Visualization 4hrs.(Day39, Day40, Day41)
#Day31, 32, 33, 34
やったこと
- Feature Engineering Lesson1, 2, 3
- MIをみようね
- TargetとのMIだけにとらわれないでね
- MIをFEに活かそうね
- 同じMIでもモデルによってちょっと挙動が違うので注意だよ
- Day31~33はほぼ何もしてないので実質Day34だけ
自分で調べたことや疑問をメモ
- MIはどのように計算されるのか?
- XがわかるとYのエントロピーがどれくらい下がるかの平均値で算出する
- 元となるデータが同じにもかかわらず、新たな特徴量を作ると精度が上がるのはなぜか?
- ってか、シンプルに英語がむずい!
学習方法の振り返りや心の変化
- FEを頑張る前にBaselineを作るのは良いアプローチやってんな
- MIもそうやけど、「そうそう!これがほしかった!」ってなる手法がたいてい存在するから楽しい
#Day35
やったこと
- Feature Engineering Lesson3
- 分布の可視化は標準化のヒントになる → 標準化の詳しくはData Cleaningコースで
自分で調べたことや疑問をメモ
- 特徴量エンジニアリングとは、観測されたデータを私達が知りたいこと(ターゲット)により関連づくように寄せていく試み。例えるならば、「気温」、「湿度」、「風速」から、真に関心のある「体感温度」を計算するのに似ている。
- 特徴量エンジニアリングの観点は、そのデータが"モデル-フレンドリー"かどうかだけど、それがわからないときは"自分-フレンドリー"かどうかで考えるしかない。
- まずはそれぞれのモデルの得意不得意を知るとよい。例えば、線形モデルは正規化の恩恵を受けやすいが、ツリーモデルは受けにくい。詳しくはこちら
- .plot.bar()めっちゃ便利やん
- 例えば最頻値でimputeするときって、trainとtestで独立して最頻値計算したほうがいい?
学習方法の振り返りや心の変化
- シンプルに英語がわからんと集中できないな。。
- Feature Engineeringのコースやってるけど、処理だけやってスコアチェックしないから楽しめない...
#Day36, 37, 38
やったこと
- Feature Engineering Lesson4
- →英語が難しいのと、アウトプット機会が乏しく身につかなさそうなので流し読みして終わることにした
- 『Kaggleで勝つデータ分析の技術』第1章、第2章、第3章
- TPS - Oct 2021 のベースラインモデルを提出
自分で調べたことや疑問をメモ
- 「決定木の気持ちになって考える」
学習方法の振り返りや心の変化
#Day39 TPS - Oct 2021
やったこと
- TPS - Oct 2021
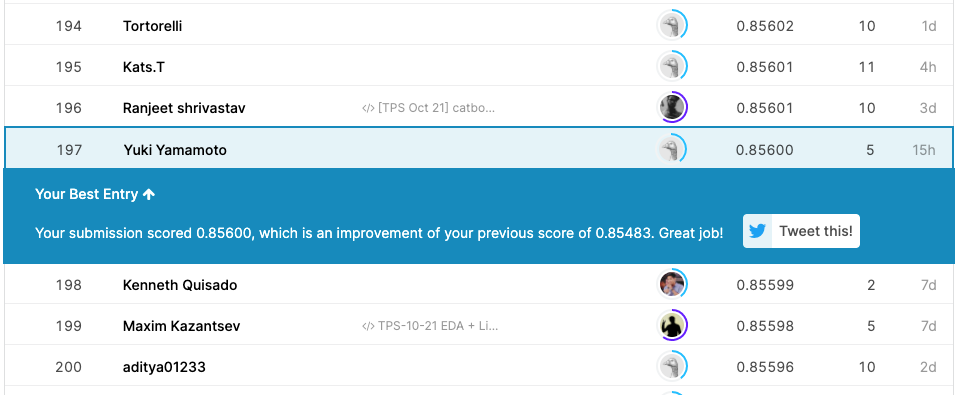
- 現時点で197位/534位!
- Codeを公開したら銅メダルがついた!
自分で調べたことや疑問をメモ
学習方法の振り返りや心の変化
- 銅メダルがついたのが本当に嬉しい!
#Day40, 41, 42 TPS - Oct 2021
やったこと 5.5h
- TPS - Oct 2021
- ハイパラチューニング
- 『Kaggleで勝つ〜』第4章 モデルの作成
- 『Kaggleで勝つ〜』第6章 モデルのチューニング
- Issue Bord作ってみた
自分で調べたことや疑問をメモ
- ハイパラチューニングちょっとわかったけど、最適とはいえない。CVとかやるなら実行時間がかなりかかりそう
学習方法の振り返りや心の変化
- 最近3日に1日ぐらいしかできてないけど、それでもいいのでとにかく続けていくぞ
最後に
先月から機械学習系のインターンを探し始めたことをきっかけにKaggleをお休みしていましたが、気づいたら25日も経ってしまいました。
インターン探しは無事終了し、11月1日から製造業の検品作業を自動化する画像認識AIのスタートアップで働いています。業務内容はPoC(Proof of Concept)など基礎的な部分ですが、機械学習エンジニアチームに採用いただけたことは大きかったです。
ちなみにKaggleの経験はかなり役に立っています。まず、採用面接でも「おお〜」というようなポジティブな反応をいただけました。詳しい理由は言われなかったですが、Python書けることがわかりますし、機械学習についてもsubmitできるぐらいの基礎中の基礎は抑えているというのがわかるのが、インターンレベルでは安心材料になってたのかなと思います。また、今の業務をこなす上でも役に立っています。PoCではモデル作成の部分はGUI化されていますが、画像データの撮像環境をどういうふうにすれば精度が出やすいかを考えたり、モデルの性能評価ではAUCなどKaggleで学んだことが当然のように出てきます。
一方で、当然ですが、新卒などで機械学習エンジニアとして就職するには、もっともっと勉強する必要があります。インターンもやりつつ、2022年1月末までにKaggle Expertになるという目標に向かって、Kaggleを再開します。
業務をしながら学習習慣をつけるには?を模索中なので、 ひとまず この#30DaysOfKaggleは終わりにします。